
A Discussion on Stateless & Stateful Services (Managing User State on the Backend)
In most articles I come across on stateless and stateful services, stateful service architectures are viewed less favorably in contrast to stateless services primarily due to the horizontal scalability challenge they bring along.
It is always recommended to implement a stateless service architecture as opposed to stateful but I believe things are not so binary when dealing with a service’s state. It’s rather more nuanced and both forms have their use cases.
Most web services we interact with in our day-to-day lives hold some degree of user state to function effectively, making them stateful. And how we manage the state on the backend ascertains the complexity involved in scaling the service.
This write-up helps us to understand the intricacies of managing user state in a web service. Let’s begin with understanding what the user state is.
What Is User State?
User state is the user activity data the application backend stores to provide the user tailored responses based on their past activity. This state may represent the user interaction in both the current and the former application sessions.
For instance, in an MMO (Massive Multiplayer Online) game, user state would comprise user game session data, their progress, data on real-time interactions with other players and so on, stored in the application servers. A collaborative document editing service would manage document state and user cursor position data. An e-commerce service would store the content of the user’s shopping cart in-memory. Video streaming platforms store video playback history in real-time as the user streams a video and so on.
All this data stored by the application servers that enable the system to send custom responses to every user based on their behavior is user state and is key in driving conversions (customers visiting the site to purchasing a product) on any platform.
Out of all the services maintaining user state, real-time services such as online games, collaborative apps, communication apps like chat messengers, etc., heavily rely on storing and managing user state in the application servers to provide low-latency behavior. In these systems, users are collaborating in real-time and they need quick access to the synchronized interaction data. For this, the application servers have to hold the user state in-memory for quick access.
One real-world example of this is Slack’s real-time messaging architecture, where Slack Channel Servers hold channel information in-memory and are stateful to deliver messages to clients quickly and efficiently. Since the backend servers store the channel information in-memory, they don’t have to poll any external storage like the database to fetch information on every client request. This enables the service to quickly return the response to the clients, keeping the latency low.
I’ve done a detailed case study on Slack’s real-time messaging architecture. You can read it here.
Now, when every server node in the cluster running a distributed service like Slack holds the user state, how is the traffic & user state managed?
Managing User State in a Cluster
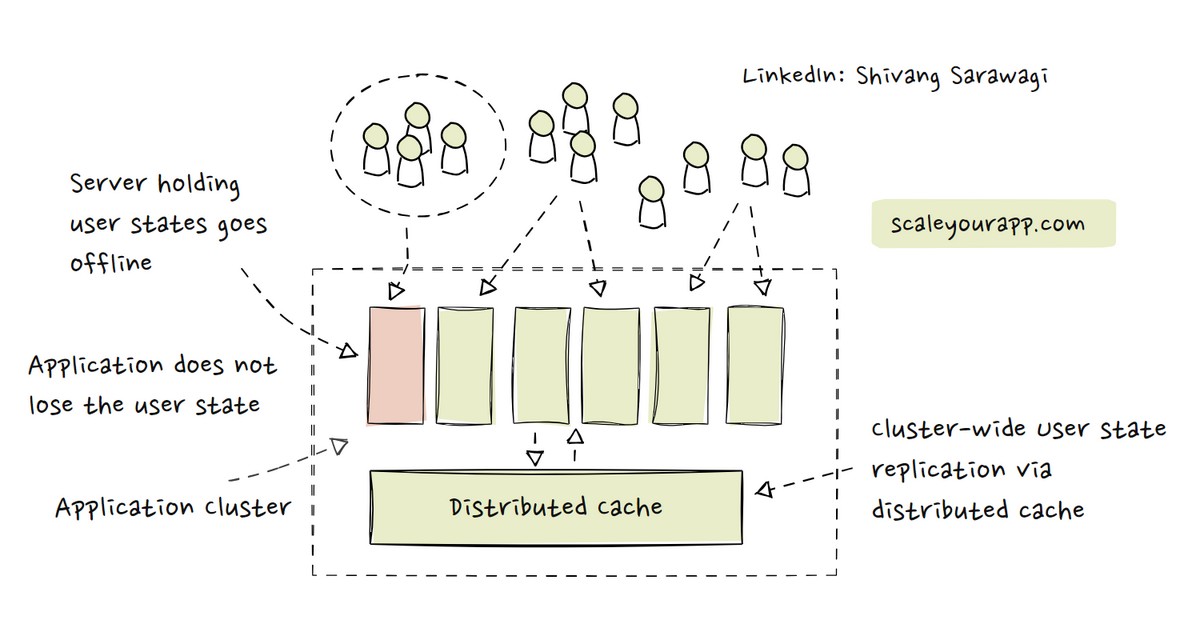
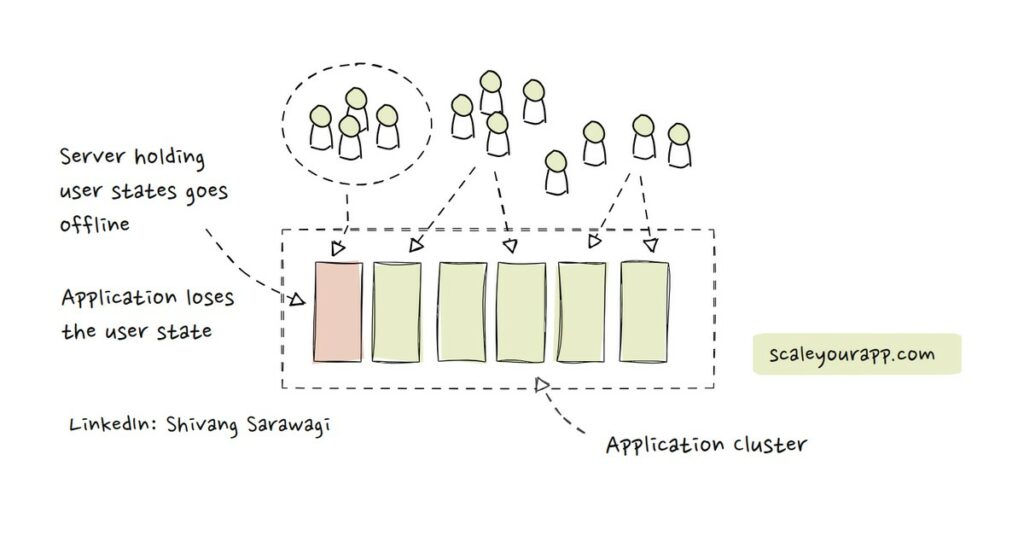
Imagine a server node handling requests from a set of users and it goes down. In this case, the state is lost. The node cannot be replaced by another node in the cluster without the user discovering that since it does not have the current user state that the node that went down had.
This is primarily the issue with stateful services. If the node holding state goes down, the state is lost.
Even when the node is alive, how does the cluster ensure that the same node handles the sequential requests of the same users it handled before since it holds their user states?
Let’s discuss the first scenario:
The Node Holding User State Goes Down
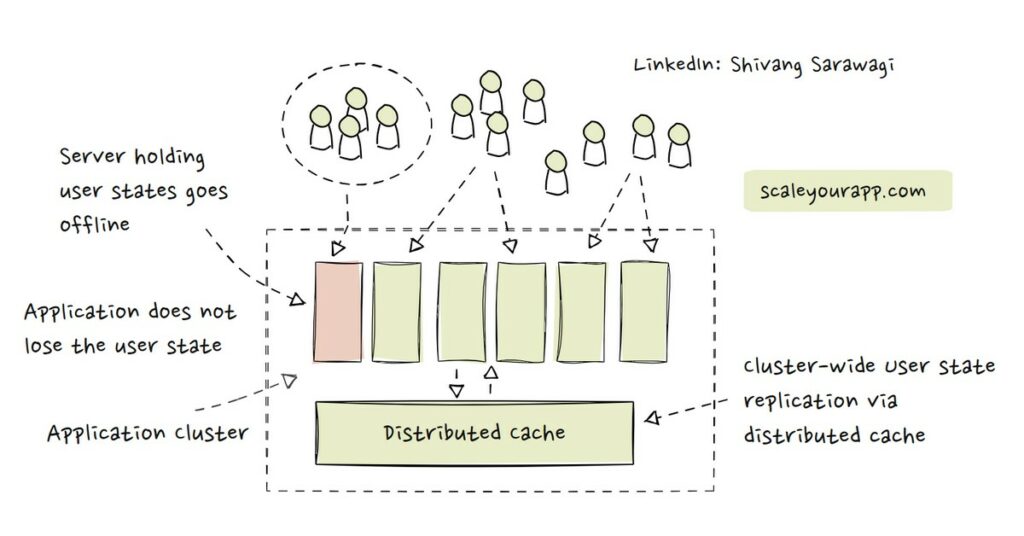
To avoid losing the user state in case the node holding it goes down, we can replicate the user state onto an external storage, either a distributed cache or a database, in addition to replicating the state to other nodes in the cluster via a cluster synchronization service like ZooKeeper.
Replicating the user state from one specific node to other system components and cluster nodes averts losing user data when a node goes offline. The node replacing the offline node can access user data from the external storage and resume processing user requests without any noticeable impact on the user experience.
Replicating User State to a Distributed Cache
When we replicate the user state from respective servers to a distributed cache, this enables other nodes in the cluster to have access to a centrally stored user state.
Even if a few nodes go down, new nodes can replace them, fetching the required information from the cluster cache. This adds statelessness to our stateful service as new nodes can be added as and when required, facilitating horizontal scalability.
Storing User State in a Database
User state can also be stored in a database. The cluster instances can read from and write user state to the database. Cloud providers offer dedicated session management databases and services to manage user sessions and other user activity related data. These services have data synchronization features that synchronize user state across clusters, data centers, cloud availability zones and regions.
However, caches are primarily preferred for storing user state since they are built for no-brainer low-latency access of temporarily stored data based on a key. In contrast, databases are meant for persistent storage and running complex queries.
I’ll give you one instance where both a database and the cache together can be leveraged for storing user state.
Leveraging Both the Database & the Cache for Storing User State
When storing items in a user cart on an ecomm platform, we can store the data in the distributed cache along with storing it on the application server handling the user requests to make the service stateless.
However, data in the cache has an expiration period & eviction policy and may not stay forever. Users may just add items to their cart and purchase them days later.
This data is crucial for businesses as well as for the user experience. For this, we need to persist the cart state in the database as well. We can either setup a dedicated database for this or store it in a separate Cart table in the DB as per our application design.
The application server, along with storing the cart state in the cache, will also push the data to the database. Again, as per the use case requirements, this may not happen as frequently as the data is synched with the cache. We may persist the user state to the database at stipulated intervals.
This way, even if we lose data in the cache, we have a persistent backup of the user cart in the database.
Replication of User State Across the Cluster
Sessions are replicated across the cluster either synchronously or asynchronously. Synchronous replication promises strong consistency across the cluster, though this adds a bit of latency to the request-response flow.
Asynchronous replication makes the cluster eventually consistent without adding any latency to the request-response flow. There are multiple ways to replicate sessions across the cluster, including leveraging the load balancers, message queues and distributed coordinators like Apache Zookeeper.
Distributed coordination services like Zookeeper help manage the cluster state, leader election, failover, and more. They ensure cluster availability and consistency.
Speaking of load balancers, let’s discuss the second scenario, where a stateful server node does not go down, is in a healthy state and handles requests for a set of users.
The Stateful Node Handles Requests for a Set of Users
Load balancers route the traffic to the same node that handled the former request for a certain user via various algorithms and cookies. One popular approach is called the session affinity or sticky sessions.
Sticky sessions enable the load balancer to route the user requests to the same cluster node handling that user’s requests. This approach is largely used with stateful applications, including legacy applications that have significant redesigning costs to make them stateless.
Though, the sticky sessions approach has significant load balancing challenges, including uneven use of cluster resources as a certain sticky server can be overwhelmed with user requests while other servers sit idle with ample request processing bandwidth.
In addition, if the sticky server is deployed geographically distant from the user, the response will have additional network latency as well.
Implementing a cluster-wide distributed cache in this scenario helps a great deal as sessions can be moved over to a central storage space and every node can access them, averting the load balancer to route the user requests to a sticky server. This makes our system scalable.
In my cloud course, you’ll find discussions on cluster communication, service deployment infrastructure, how services are deployed across the globe in different cloud regions and availability zones and more.
This course is a part of the Zero to Mastering Software Architecture learning path that I’ve authored, comprising three courses that offers you a structured learning experience, taking you right from having no knowledge on the distributed system design domain to making you a pro in designing web-scale distributed systems like YouTube, Netflix, ESPN and the like. Check it out.
If you found the content helpful, consider sharing it with your network for more reach. I am Shivang. Here is my X and LinkedIn profile. Feel free to send me a message. I’ll see you in the next post. Until then, Cheers!
If you wish to receive similar posts along with subscriber-only content in your inbox, consider subscribing to my newsletter.


Follow Me On Social Media