
{kind=link}
In this system design series, I’ve started on this blog, I discuss the intricacies of designing distributed scalable systems and the related concepts. This will help you immensely with your software architecture and system design interview rounds, in addition to helping you become a better software engineer.
If you wish to master the art of designing large-scale distributed systems starting from the bare bones, check out the zero to software architect learning track, that I’ve authored.
If you are new to system design and software architecture, I recommend starting with this blog post on web application architecture.
With that being said, let’s get started.
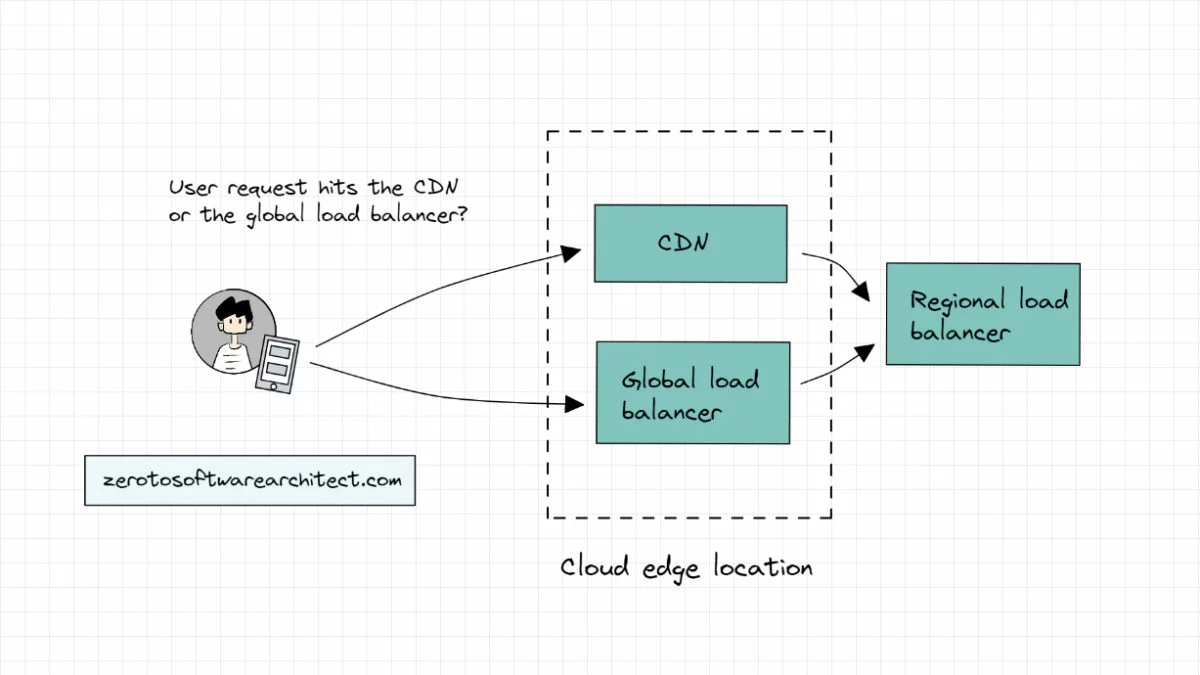
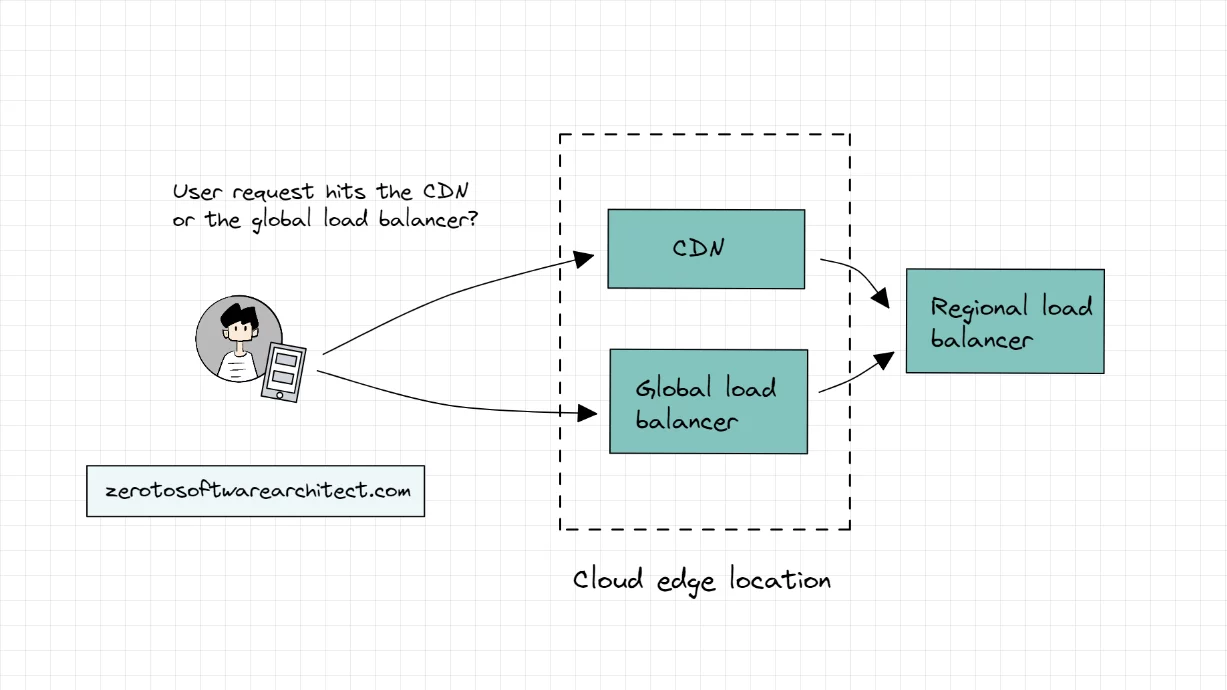
Picture a user requesting data from the application backend deployed across multiple cloud regions. After DNS resolution, what do you think, which system component will the request hit first—the CDN or the load balancer? P.S. both components are typically deployed in the cloud edge locations.
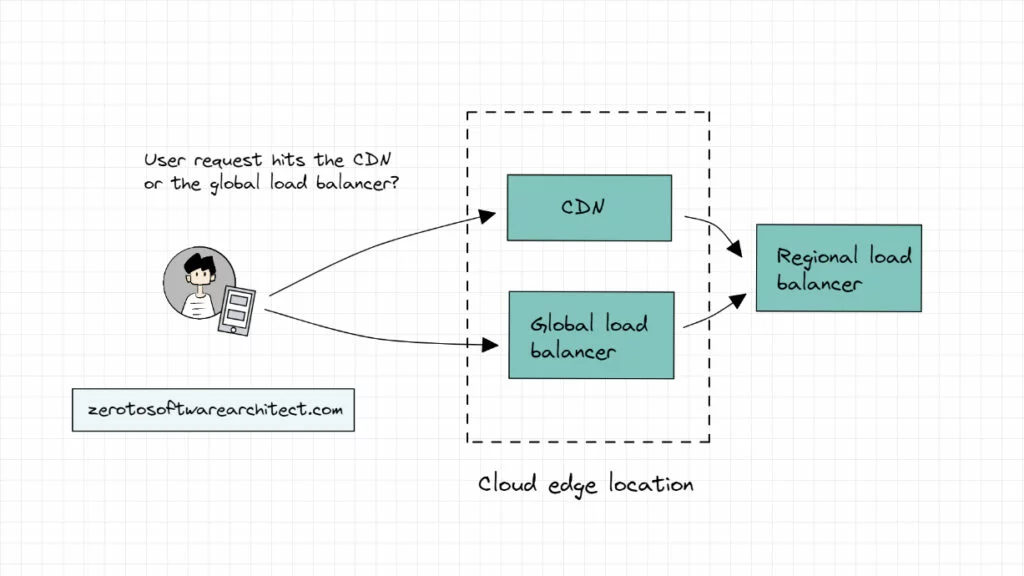
If the request hits the CDN, does all the traffic go through the CDN to the load balancer to the API gateway to the backend services and back? In this scenario, the CDN has to balance the global traffic load of the system since it is the first point of contact. If yes, what’s the point of having a global load balancer?
If the request hits the load balancer first, then based on the request data, does the load balancer route the request to the CDN and the components at the backend (additional load balancers, API gateway and so on)? In this scenario, isn’t the load balancer adding additional latency to the response if the CDN contains the requested data? Shouldn’t the request be hitting the CDN first?
CDN and Load balancers
A knee-jerk answer to the question asked above would be ‘it depends’; It depends on the use case requirements. And I agree with that. However, I’ll discuss the typical use case found in most system architectures deployed across multiple cloud regions globally. This will also give you insights into the intricacies of working with both components (CDN and load balancer) of application architecture.
Applications typically contain both static and dynamic data. And the user requests after DNS resolution typically hit a CDN before they are routed to the origin servers if the CDN doesn’t contain the requested data.
CDNs have load balancing features implemented internally that tackle the heavy traffic load from different regions hitting the application, maintaining availability. If the CDN contains the data, it returns it to the user ensuring minimal latency. If it doesn’t, it routes the request to the global load balancer.
The load balancer, in turn, routes the requests to the load balancers down the hierarchy, like regional and availability zones load balancers. Which in turn distribute traffic across application instances of a certain service.
Load balancers have listeners, rules and target groups configured with them. Listeners listen to the connections between the client and the load balancer using the configured protocol and the port. In this case, the client is the CDN.
Rules specify how the traffic will be distributed in the downstream application components. And target groups contain targets (application instances, containers, etc.) for the traffic to be routed to. These targets can be deployed in several availability zones across multiple data centers.
In case of a traffic surge, additional targets can be added to the target groups and configured with the load balancer to augment the system’s processing capacity. After performing health checks, the load balancer starts routing the traffic to the newly added targets.
The global load balancer continually, in stipulated time intervals, checks the availability of regional load balancers. If a regional load balancer goes down, based on the configuration (active-active or active-passive), the backup load balancer should pick up the slack. If this doesn’t happen, the global load balancer may route the request to other cloud regions. This is where having a hierarchy of load balancers saves the day.
In my web application and software architecture 101 course, I’ve discussed how load balancers work, how DNS resolution works when a user sends a request to the backend and how DNS-based load balancing works. In my cloud computing course, I’ve discussed the underlying application architecture on which our distributed systems run, including edge locations and how the cloud deploys our services across the globe, ensuring scalability and high availability.
These two courses are a part of the Zero to Software Architect learning track that I’ve authored, which takes you right from having no knowledge on the domain to being able to design large-scale distributed applications like Netflix, ESPN and the like. Check it out.
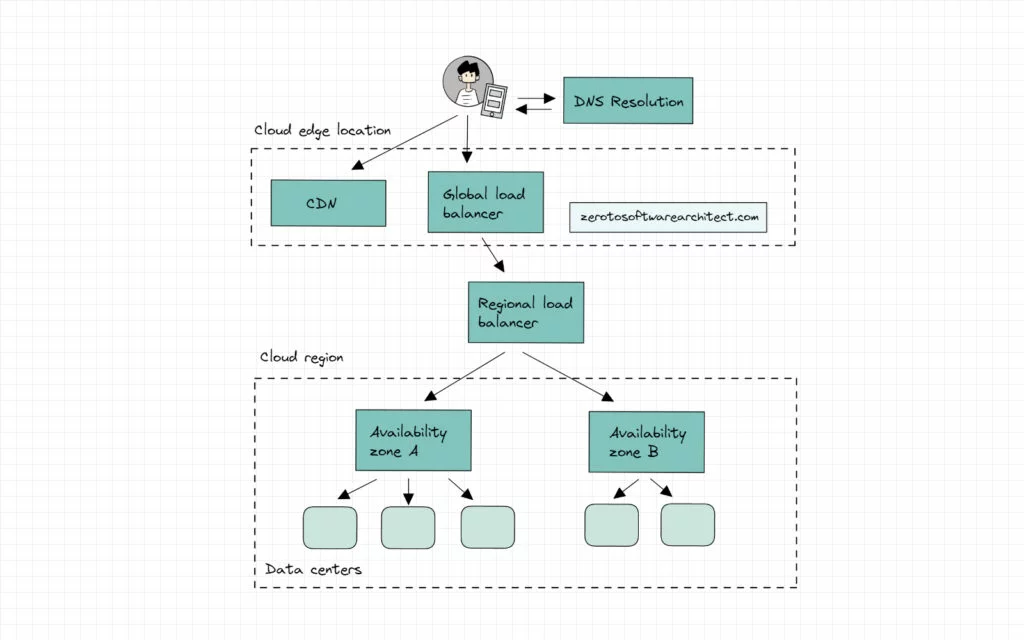
So, the global load balancer deployed on the edge locations across the globe routes the traffic to the regional load balancers. The regional load balancers, in turn, route the traffic across cloud availability zones. Each availability zone typically has two to three data centers.
The hierarchy of load balancers depends on the application requirements. The request coming in from the CDN can even directly hit the regional balancer if the global load balancing isn’t implemented.
Besides the global and regional level, load balancing can be implemented at the application component level as well, like with the database, messaging servers and so on. This is called internal load balancing.

Understanding the request flow with load balancers
Whether the request hits the CDN or the load balancer or selectively both (based on the request) depends on our application architecture and the configuration for that is done at the DNS level. Based on the request headers and the routing policy, traffic is routed to the designated components.
Routing policies
There are several routing policies that help us route the traffic based on certain logic, for instance, geolocation and geoproximity policies, route traffic based on the location of the users and the system resources.
Latency-based routing policy helps route the traffic to the resource across AZs and regions that provides minimal latency.
Weighted and IP-based routing policies help route traffic to specific IPs, whether it’s of CDN or load balancer.
Content-based routing policy helps route the requests to specific machines based on the content they host. More on this coming up ahead.
Global load balancers typically have two architectures—DNS-based and Anycast-based. DNS load balancing returns a number of IPs to connect with. This is done to enable the client to use other IP addresses in the list in case the first doesn’t return a response within a stipulated time. I’ve discussed DNS load balancing in detail in my web architecture 101 course.
Anycast-based routing
In contrast, anycast-based routing returns the same IP for multiple instances and a router routes the requests to the closest instances via the optimum network path. This is done with the help of protocols like the border gateway protocol.
I’ll explain this with the help of an example. Say a user request with DNS load balancing requests data from the backend. DNS will return three IP addresses of three machines of a service: IP instance A, IP instance B, and IP instance C. The user’s system can hit any IP, for instance, IP instance A and get the data.
In anycast, all three machines will have the same IP. And the network protocol will route the request to the closest one. If, in any case, the closest machine stops working, the system automatically looks for an alternative network path to find a working machine.
This helps mitigate DDoS attacks on a single machine since all the machines have a common IP. The attacker couldn’t know the exact address of a certain machine to attack it. Though, the downside of using anycast-based routing is the network route information has to be continually maintained and optimized to enable the request to be routed to the closest machine. This requires additional resource investment.
Both of these approaches (DNS and anycast) have their pros and cons. Cloudflare CDN extensively uses anycast-based routing. Google cloud load balancing leverages anycast with cross-region load balancing, including multi-region failover.
On the other hand, AWS Cloudfront leverages DNS-based routing.
Selectively routing traffic between CDN and load balancer
As I mentioned, our application is designed as per the use case requirements. All the requests can go through the CDN or the load balancer or selectively routed through both.
In selective routing, the requests are routed based on a content-based routing policy configured at the DNS level.
The requests can be routed based on the path name in the URL. For instance, if the request has /images or /videos in the path, it would be directed to the CDN and other URLs possibly requesting dynamic data can be routed to the load balancer.
This would significantly cut down the load on the origin servers while static content is served from the CDN at the edge. Also, requests for dynamic data directly hit the load balancer as opposed to the CDN.
Besides configuring content routing at the DNS level, there are other possible ways to route traffic, such as setting up a proxy server between the client and the origin servers. However, DNS configuration is a more straightforward way without adding an additional component to the architecture, increasing its complexity.
Whichever way it is, the routing algorithm scans the URL path and the request headers to route the request to the right application component.
If we route all the traffic through the CDN, the CDN is updated with the latest data like a write-through cache. If the CDN doesn’t contain the data, it requests the backend through the load balancer and the data returning from the application backend is updated in the CDN and returned to the user via it. So, the next time, the CDN deals with the request for that data, cutting down the load on the origin servers.
In contrast, when selectively routing data between the CDN and the load balancer. The CDN has to be explicitly updated with the latest data continually. This reminds me of a feature Google load balancers have. They automatically update the frequently accessed data through the load balancers to the CDN. Check out the below video: Combining CDN + Load balancing for better performance
If you found the content helpful, check out the Zero to Software Architect learning track, a series of three courses I have written intending to educate you, step by step, on the domain of software architecture and distributed system design. The learning track takes you right from having no knowledge in it to making you a pro in designing large-scale distributed systems like YouTube, Netflix, Hotstar, and more.
Where to go next?
Here is the next blog post in the series, where I discuss API gateway and the need for it in the application architecture. Give it a read.
Well, folks, this is pretty much it. If you found the content helpful, consider sharing it with your network for better reach. You can also subscribe to my newsletter to see the latest content published by me in your inbox. You can read about me here.
I’ll see you in the next blog post. Until then, Cheers!


Follow Me On Social Media