
{kind=link}
System Design Case Study #4: How WalkMe Engineering Scaled their Stateful Service Leveraging Pub-Sub Mechanism
WalkMe Engineering had a stateful monolith service handling an average of 22.5 million monthly requests, peaking upto 30 million.
The service managed this massive load sustained by vertical scaling but started to show cracks as a single monolith server can be vertically scaled only so much. The state of availability was such if the server went down, the application went down.
An obvious move was to scale the service horizontally by adding more instances that could handle the requests parallelly with a shared service state across the cluster.
The application could also be split into a microservices architecture, moving different application features across different services and scaling each feature separately. This would increase the availability and flexibility, but breaking down a massive seven years old project isn’t easy and its migration to a microservices architecture is a work in progress.
Relevant read: How Uber transitioned from monolithic to microservices architecture.
The immediate solution was to introduce new nodes, create a service cluster and replicate the service state across the cluster nodes to split the traffic amongst them.
What was the service state?
The application server held large content files in-memory. This reduced the latency, averting the need to fetch content from external systems like the database or the object store to serve a request.
The files were originally hosted in AWS S3 object storage service and fetching them on every user request had a significant amount of IO-latency. It took almost two minutes to download 1.5GB from S3. Accessing the same data from memory took 20 seconds — around 600% faster. Thus, the files were stored on the server in-memory.
Whenever the files on S3 changed, the data on the application server was synched with S3. This kept the data consistent between S3 & application server on an ongoing basis.
In my previous post, I discussed ways to make a stateful service like this stateless, including using a distributed cache to hold the cluster state acting as a central cluster state storage. Do give it a read.
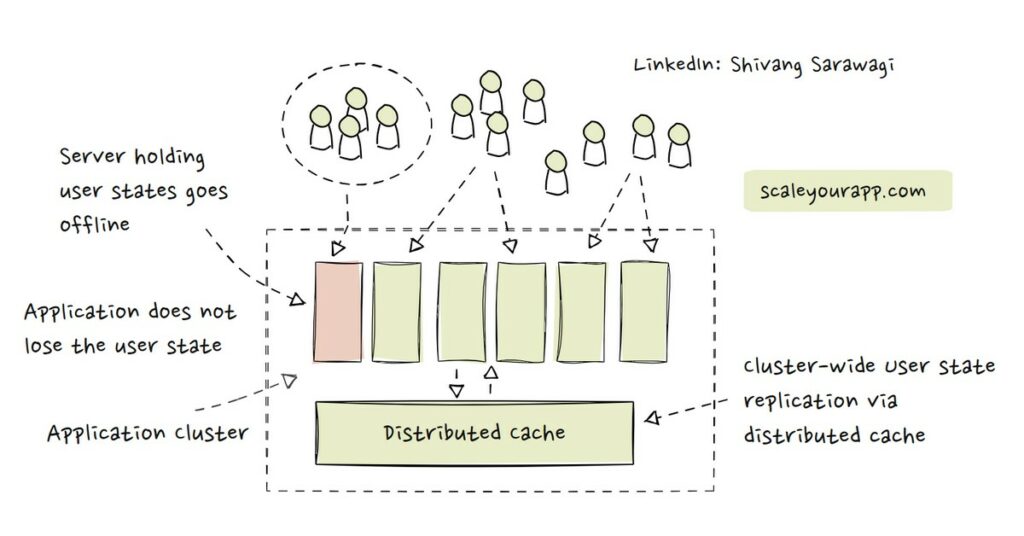
Introducing new server instances in the infrastructure wasn’t that straightforward. It brought along a new challenge. Whenever the state of the files in S3 storage changed, it had to be synched across all the instances in the cluster along with the external cache. This necessitated a state synching mechanism in the cluster.
Issues With the Implementation Of Distributed Cache
Redis-powered AWS Elasticcache was considered to offload the service state from the application servers to an external cache. If all the state from the cluster instances were moved to the central cache, syncing the files with S3 would be simpler since the source of service state data in the cluster would be one as opposed to multiple instances holding state.
The primary issue with this solution was Redis wasn’t as performant for storing large files since it’s a single-threaded server and processing large files for every read/write request would take a significantly long time.
A single-threaded server can process only one request at a time. I’ve discussed this in detail in my single-threaded event loop architecture article. Do give it a read for an in-depth understanding.
Redis is built for low-latency access to different data types such as strings, lists, sets, hashes, etc. It is not built for storing blobs. Object stores suit best for storing blobs.
Storing Service State On the Application Server
Before the cache, the application server stored these large files in-memory for quick access. However, the application server in this scenario needed a lot of memory to store files in addition to having buffer memory for compute.
For instance, if an application server with 16 gigs of memory needs to store 10 GB of service state data where each file is 1 GB, theoretically, that would leave only 6 GB of memory for other operations. However, this does not account for the memory required by the operating system and other software installed on the server to run the application. Ideally, these use cases require memory-optimized servers that are built to handle extensive data in memory.
How much data can be stored in-memory in application servers deserves a dedicated article, and I will publish it soon on my blog. You can subscribe to my newsletter to receive the content in your inbox as soon as it is published.
In addition, data on servers can also be compressed, leveraging different compression techniques for efficient storage, in addition to eliminating duplicates.
GitHub leveraged a technique called content addressable storage to reduce 115TB of data to 28TB of unique content. After compression, the entire index was just 25TB. I’ve done a detailed case study on it. Check it out.
Slack’s real-time messaging architecture, similar to WalkMe’s use case, holds the service state in-memory for low-latency access. At peak times, approx. 16 million Slack channels are served per host. Here is a detailed case study I did earlier.
Storage Costs
In addition to Redis-powered Elasticache being single-threaded, the costs associated with storing large files in the distributed cache were starkly high in comparison to storing them in the application server.
This is primarily because the Elasticache charges hourly based on the number of nodes deployed and the bigger files required more nodes for storage and processing. In addition to this, there were additional backup storage and data transfer costs associated.
The next option was to consider a pub/sub messaging model that would broadcast a change of state on a certain server to other nodes in the cluster.
Pub/sub or publish-subscribe is an asynchronous service-to-service communication model where publishers publish messages to topics and the subscribers receive those messages by subscribing to relevant topics.
In this model, the publishers are decoupled from the subscribers via a message broker or a message bus as the publishers send the messages into topics and the subscribers subscribe to relevant topics to receive the messages without knowing who the publisher is. This facilitates flexible and scalable system design.
If you wish to delve into the fundamentals of it, check out my web architecture fundamentals course here.
Leveraging the Pub-Sub Distributed System to Scale the Monolith Service
As opposed to offloading the application state to a distributed cache, the idea now was to sync the application state with all the servers in the cluster. And this could be made possible with the publish-subscribe pattern/messaging model.
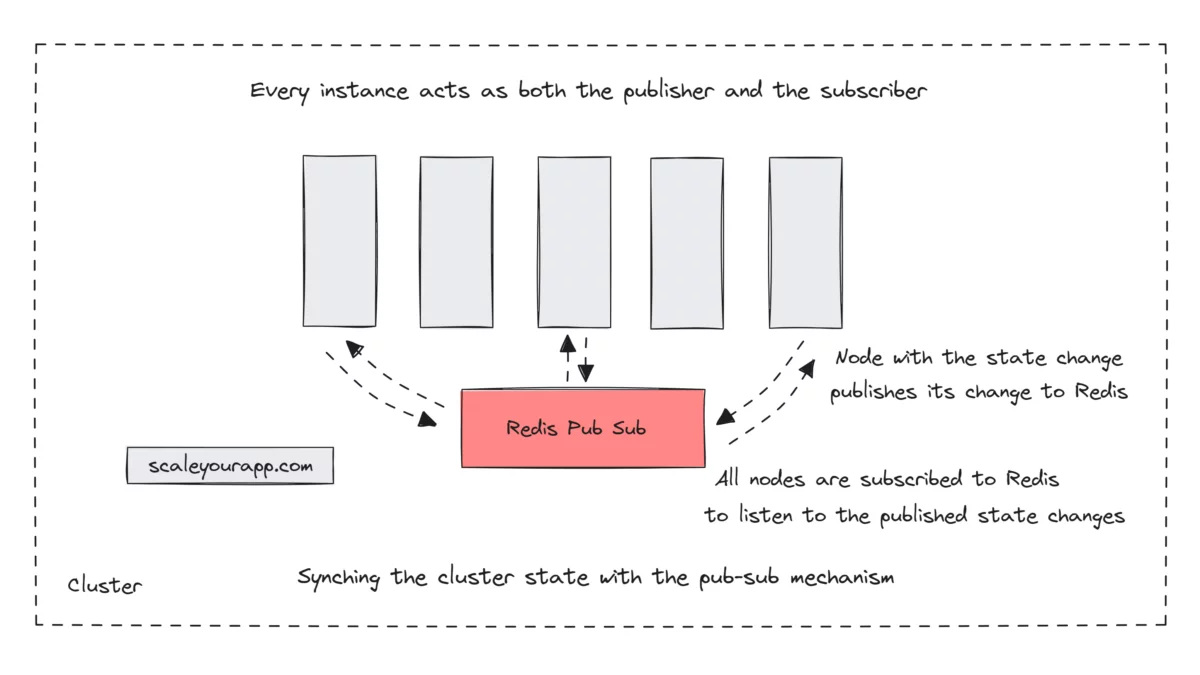
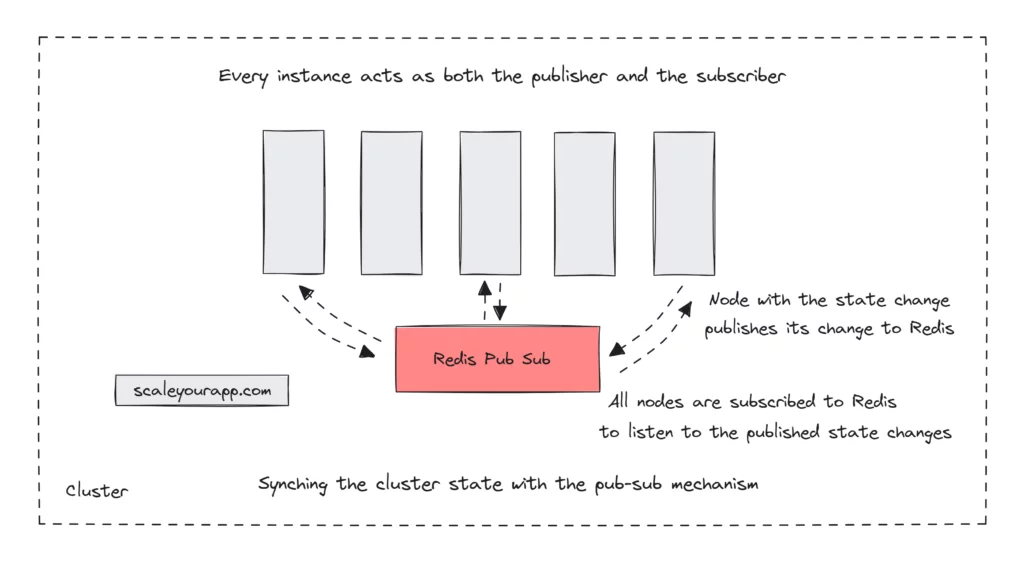
In the application cluster, with the pub/sub model being implemented, every instance would act as both the subscriber and the publisher. Whenever the state changed on any instance, it would publish the changes to a topic and all the instances of the cluster would subscribe to that topic to listen to the changes. Once the servers get the updates, they will update their user state, synching it with the cluster.
To facilitate the pub/sub mechanism, WalkMe Engineering leveraged the Redis pub-sub feature.
Why Not Implement the Publish-Subscribe Model Using A Traditional Message Broker?
Since they were deployed on AWS, they considered AWS SNS (AWS’s managed messaging service), but the implementation had an issue that didn’t allow the private IP addresses of subscribers to subscribe to an AWS SNS topic. To fix this, they had to make the IPs of the instances public, which was a security risk.
As a workaround, they leveraged the Redis pub-sub feature, which enabled them to keep the servers in sync.
Redis, as opposed to being a traditional message broker, is a distributed data structure server that offers a pub-sub feature. It isn’t a replacement for a message broker. Since they had encountered an issue with AWS SNS, using Redis was more of a hack.
The key is as opposed to using a distributed cache for synching the cluster state; another approach the pub-sub mechanism can be leveraged when the files are large enough to be processed by a single-threaded cache system.
Also, not all technologies are the same; pros and cons are associated. Although Redis offers the pub-sub implementation, it is not a replacement for the pub-sub implementation by a dedicated messaging solution. Redis does not guarantee the delivery of messages. This could leave the cluster in an inconsistent state. We have to take this into account in our implementation.
Though not much details are given in the WalkMe article, on how they implemented the pub-sub with Redis, I reckon to handle the message loss, network & instance failure, they would have some backup mechanism implemented to periodically sync the cluster state with the servers and an additional persistent system like the database to persist the service/user state.
In case you wish to delve into the details of differences between the Redis pub-sub and the pub-sub implementation via dedicated message brokers, below are some of the good reads:
RabbitMQ vs. Redis – Difference Between Pub/Sub Messaging Systems
Redis vs. Kafka – Difference Between Pub/Sub Messaging Systems
Redis Pubsub and Message Queueing – Stack Overflow
Chunking Larger In-Memory Files
We learned that the primary issue when using Redis as a distributed cache to sync the cluster state was Redis, being single-threaded, took significantly long to process every large file in sequence.
This made WalkMe Engineering move to the next option, which was leveraging the Redis pub-sub mechanism to sync the cluster state by moving the state changes (that meant the change in large in-memory cached files on application servers) across the cluster.
Didn’t this mean Redis had to deal with large files again?
Before I move on, I would want to state that the details of the WalkMe Redis pub-sub implementation are not given in the source article. I am just speculating here.
When using Redis as a pub-sub system as opposed to a distributed cache, the system might not need Redis to process the entire files but rather publish only the changes (delta) to those files that would be consumed by the subscribers.
Also, the server might not store all the files as a whole in-memory but rather chunk them into parts with compression applied for efficient processing. Also, publishing the updated files as a whole in their entirety to be synced across the cluster would not make sense as it would take an eternity, spiking the latency. This will make the pub-sub system an application bottleneck.
The files would be split into chunks, with each chunk given a unique identifier that could be used to locate and reassemble the original file.
This will reduce the server’s memory and CPU usage significantly in addition to the network bandwidth consumption.
Key System Design Learnings from this Case Study
Single-threaded architectures aren’t best suited for in-memory processing use cases. They are best suited for I/O-bound cases. This is why Redis being single-threaded, had such high latency when processing large files in-memory. Go through this article for a detailed read.
Besides using a distributed cache to manage the cluster state, leveraging the pub-sub mechanism is another way to sync the cluster state across different instances.
Every tech has its pros and cons. There is no silver bullet. Real-world services have a lot of intricacies. There is no standard formula or a rule that can be applied to every service to scale or increase its availability.
So, as opposed to learning by heart the system designs of popular large-scale services available on the web for our interviews, if we could break them down into use cases and learn the concepts implemented behind those with an understanding of why and how a certain concept is implemented in a certain use case, we would do a lot better in our system design interviews.
If you wish to delve deeper into the backend architecture of large-scale services, with discussions on how large-scale services are designed, including discussions on fundamental concepts like scalability, high availability, client-server interaction, message queues, data streaming, cloud infrastructure, how large-scale services are deployed in different cloud regions and availability zones and more, check out the Zero to Mastering Software Architecture learning path (comprising three courses), I’ve authored.
It gives you a structured learning experience, taking you right from having no knowledge on the domain to making you a pro in designing web-scale distributed systems like YouTube, Netflix, ESPN and the like.
With that being said, I’ll wrap up this article. If you found the content helpful, consider sharing it with your network for more reach. I am Shivang. Here is my X and LinkedIn profile. Feel free to send me a message. I’ll see you in the next post. Until then, Cheers!
If you wish to receive similar posts along with subscriber-only content in your inbox, consider subscribing to my newsletter.


Follow Me On Social Media