
Facebook Real-time Chat Architecture Scaling With Over Multi-Billion Messages Daily
This is my second write-up on Facebook architecture. In the first, I covered the databases leveraged by Facebook.
In this write-up, I will talk about the real-time chat architecture of Facebook which scales with over multi-billion messages sent every single day.
Let’s jump right into it.
Distributed Systems
For a complete list of similar articles on distributed systems and real-world architectures, here you go
1. Introduction
It all started at a hackathon where a few Facebook engineers wrote a chat prototype & presented it before their team. The feature was pretty basic with bare minimum features, the chatbox floated on and could be dragged around the web page, it also persisted through page reloads and other page navigations.
Engineers at Fb took the prototype and evolved it into a full-blown real-time chat feature, one of the most heavily used features in the Facebook services ecosystem.
It facilitates billions of messages sent every single day all across the world. The engineering team of the social platform has scaled it pretty well with response time as less than 100 ms.
The feature is continually improved with the sole aim of providing a top-notch communication service to the users.
Besides having the standard chat features, the chat module is integrated with the Fb social graph. Users can easily pull out the list of their friends and other relevant information such as games they are playing and such.
All the information which is available to a user on the platform, in general, is also accessible through the chat module.
2. Real-Time Chat Architecture & Technology Stack
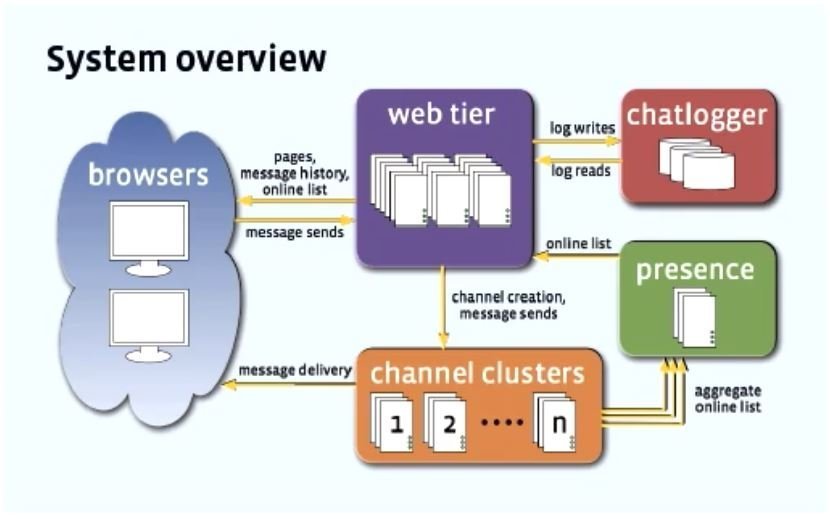
The entire system consists of several loosely coupled modules working in conjunction with each other such as the web tier, user interface, chat logger, user presence module & channel cluster.
User Interface
The user interface is written in JavaScript with some PHP used for server-side rendering.
Long-opened persistent connections are established between the client and the server with the help of AJAX.
Flash was dismissed purely due to two reasons. First, it would ask the users to install a plugin in their browsers which is not a good user experience. Second, Flash is not a preferred choice from a security standpoint.
The message fetch flow is a mix of PULL & PUSH-based HTTP models.
Initially, the client sends a PULL request to get the first snapshot of the messages, at the same time subscribing to delta updates which is a PUSH-based approach.
Once the user subscribes to the updates, the Facebook backend starts pushing the updates to the client whenever new updates are available.
Backend Web Tier
The web tier is powered by PHP. It deals with vanilla web requests. Takes care of user authentication, friend’s privacy settings, chat history, updates made by friends & other platform features business logic.
User Presence Module
This module provides online availability information of the connections/friends of a user. It’s written in C++ & is the most heavily pinged module of the system.
The module aggregates the online info of the users in memory & sends the information to the client when requested.
Channel Servers
Channel servers take care of message queuing and delivery. The functionality is written using Erlang.
Erlang is a concurrent functional programming language used for writing real-time scalable & highly available systems like instant messaging, fintech apps, online telephony etc.
The run-time system for Erlang has built-in support for concurrency, distribution & fault tolerance.
The channel servers leverage the Mochi Web library. It is an Erlang library for building lightweight HTTP servers. The messages sent by users are queued in the channel servers. Each message has a sequence number to facilitate synchronous communication between any two or more users.
Chat Logger
Logging of chat meta & other information is done via the chat logging module. It’s written in C++ & logs information between UI page loads.
To educate yourself on software architecture from the right resources, to master the art of designing large-scale distributed systems that would scale to millions of users, and to understand what tech companies are really looking for in a candidate during their system design interviews. Read my blog post on master system design for your interviews or web startup.
3. Service Scalability & Deployment
User Presence & Chat logging data is replicated across all of the data centers at Facebook while the Channel servers data is stored at just one dedicated data center to ensure strong consistency of messages.
All the backend modules are loosely coupled. They communicate with each other via Thrift.
Thrift is a communication protocol that facilitates communication between services running on heterogeneous technologies.
It’s a serialization & RPC framework for service communication developed in-house at Facebook. It helps systems running on C++, Erlang, PHP, JavaScript work together as a team.
The Most Resource Intensive Operation
The most resource-intensive operation in the entire system is not sending billions of messages across but keeping the user informed about their connections/friends’ online status.
This is important as a person would begin a conversation only when they see their connections online.
To achieve this, one option was to send notifications to the users of their connections being online. But this process wasn’t scalable by any means considering the number of users the platform has.
This operation has a worst-case complexity of O(average number of friends users have * number of users at the time of peak traffic * frequency of users going offline & re-connecting online) messages/second.
During peak hours, the number of concurrent users on the site is in several million. Keeping all the user presence information up to date was technically just not feasible.
Besides the users who weren’t even chatting put a lot of load on the servers by just asynchronously polling the backend for their connections’ active status.
Real-time systems are hard to scale. Scaling their back ends needs some pretty solid engineering skills.
To scale the user presence backend, the cluster of channel servers keeps a record of users available to chat which it sends to the presence servers via regular batch updates.
The upside of this process is with only one single query the entire list of a user’s connections who are available to chat can be fetched.
Considering the wild amount of information exchanged between the modules, the channel servers compress all the information before streaming it to the presence servers.
The number of load balancers was increased to manage the sheer number of user connections. The ability of the infrastructure to manage concurrent user connections increased significantly after this. This was one bottleneck that caused chat service outages on & off for a while at peak times.
4. Synchronization Of Messages & Storage
To manage synchronous communication, as I stated earlier, every message has a sequence number.
Besides this Facebook created a Messenger Sync Protocol that cut down the non-media data usage by 40%. This reduced the congestion on their network, getting rid of errors happening due to that.
The engineering team at Facebook wrote a service called Iris, which enables message updates to be organized in an ordered queue.
The queue has different pointers to it which help track the message updates that have been read by the user & the ones still pending.
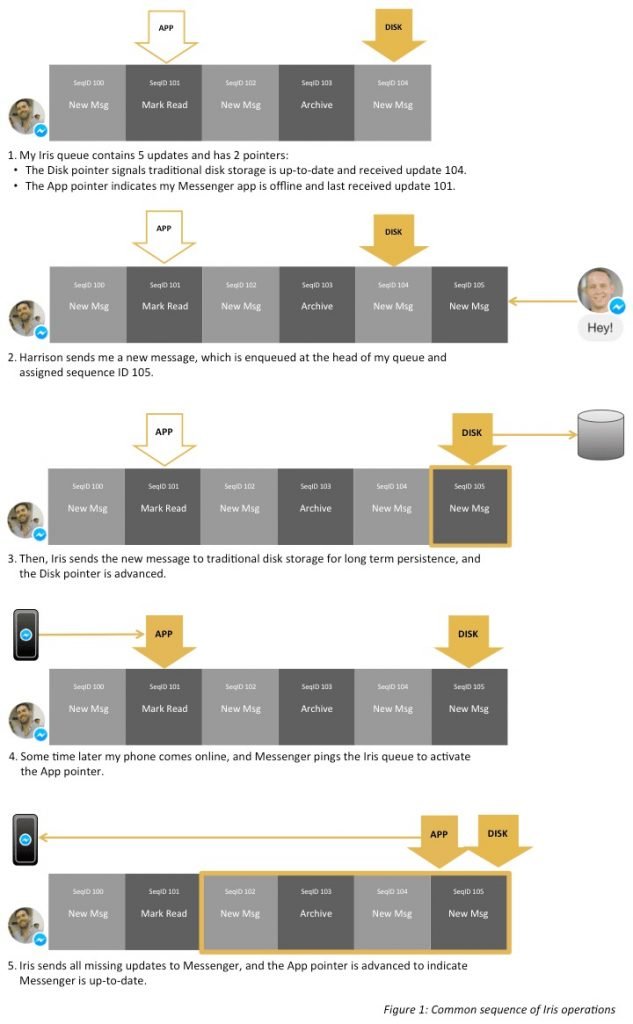
The recent messages are sent from Iris’s memory and the older conversations are fetched from the traditional storage. Iris is built on top of MySQL & Flash memory.
Hbase was used initially as the messenger storage but later the storage was migrated to MyRocks. It’s an open-source database project written by Facebook that has RocksDB as a MySQL storage engine.
For more information on this read, what databases does Facebook use?
Check out the Zero to Software Architecture Proficiency learning path, a series of three courses I have written intending to educate you, step by step, on the domain of software architecture and distributed system design. The learning path takes you right from having no knowledge in it to making you a pro in designing large-scale distributed systems like YouTube, Netflix, Hotstar, and more.

Subscribe to the newsletter to stay notified of the new posts.


Follow Me On Social Media