
{kind=link}
Razorpay is India’s leading payment-gateway service that offers a suite of products to businesses to accept, process and disburse payments enabling them to establish an online presence.
They dealt with an interesting problem: the problem of sudden transaction bursts during events such as the Indian premier cricket league. Businesses, especially in food delivery and gaming, offer flash sales and various offers to their customers minutes before and during the cricket match, which caused the sudden transaction burst.
The company’s infrastructure is hosted on AWS and configured to autoscale. But to do that, the autoscaler of the cluster and the nodes have to kick in. And this took 3-4 minutes. By this time, the system used to go down due to the heavy traffic influx.
During the IPL 2019 season, their system went down 3 days in a row for small durations. They were forced to rate-limit their customers to ensure their system was up and running.
Key Issues
After the season, they reviewed their architecture thoroughly and zeroed in on a few key issues:
They had no throttling implemented. This averted them from having control over the traffic hitting their servers.
The monitoring alerts were configured in a way that they got triggered after the issue occurred. There was a significant time lag between the issue occurrence and the alert.
The latency of the API calls to different banks went significantly high during the event. This created back-pressure on their services. Also, there was no automatic traffic routing to the banking systems with low latency.
Their backend is written in PHP, which is not scalable with databases since the programming language doesn’t support connection pooling natively. There were a lot of idle MySQL DB connections that ate up resources.
Solution
ProxySQL
The MySQL servers had a lot of idle connections due to the high latency response from the banks. Since PHP does not support connection pooling natively, the DB connections couldn’t be used efficiently.
This became a bottleneck. To fix the issue, ProxySQL was added as the interceptor between the application and the MySQL servers.
ProxySQL deployed on Kubernetes not only provided an efficient pooling mechanism, but it enabled the persistence tier to be more highly available and scalable.
Rate-limiting and throttling
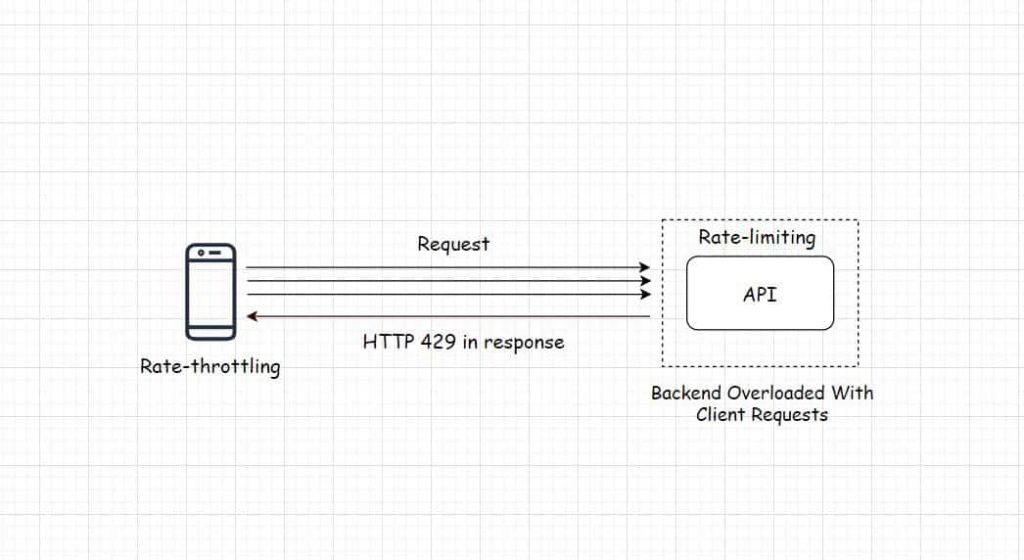
Rate-limiting and throttling were implemented to safeguard their system against a deluge of requests also DDoS attacks.
Initially, they had a very basic rate-limiting implemented on their application server using the leaky bucket algorithm. They upgraded their rate-limiting implementation to an Nginx-based proxy server having its dedicated cache.
The algorithm was changed from leaky bucket to fixed window, which proved more efficient. Several different algorithms can be leveraged to implement rate-limiting. Each has their use case.
Moreover, just implementing rate-limiting on the backend doesn’t stop the clients from sending the requests. In this scenario, the bandwidth is continually consumed as well as the rate-limiting logic has to constantly run on the backend consuming additional compute resources.
If we have control over the client, we need to implement rate-throttling on it to reduce the rate at which it sends the requests to the backend as and when it starts receiving errors in response.
Observability
The Razorpay engineering team built a real-time alerting system with VictoriaMetrics and Grafana. This enabled them to react to and debug issues quicker.
Smart routing of requests
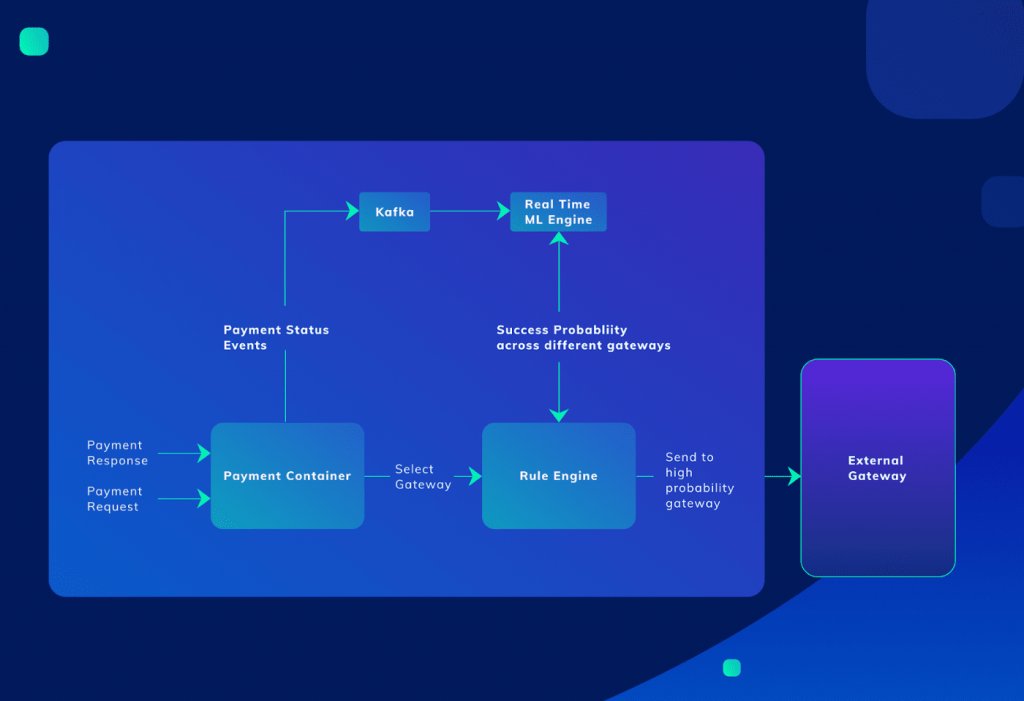
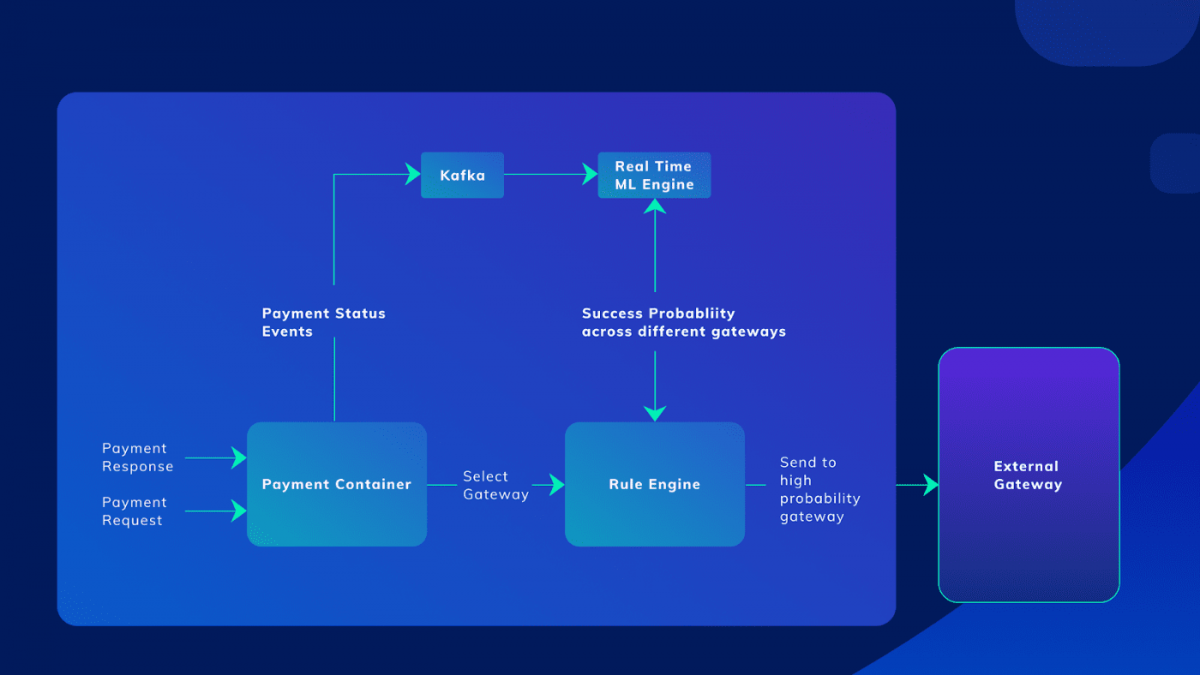
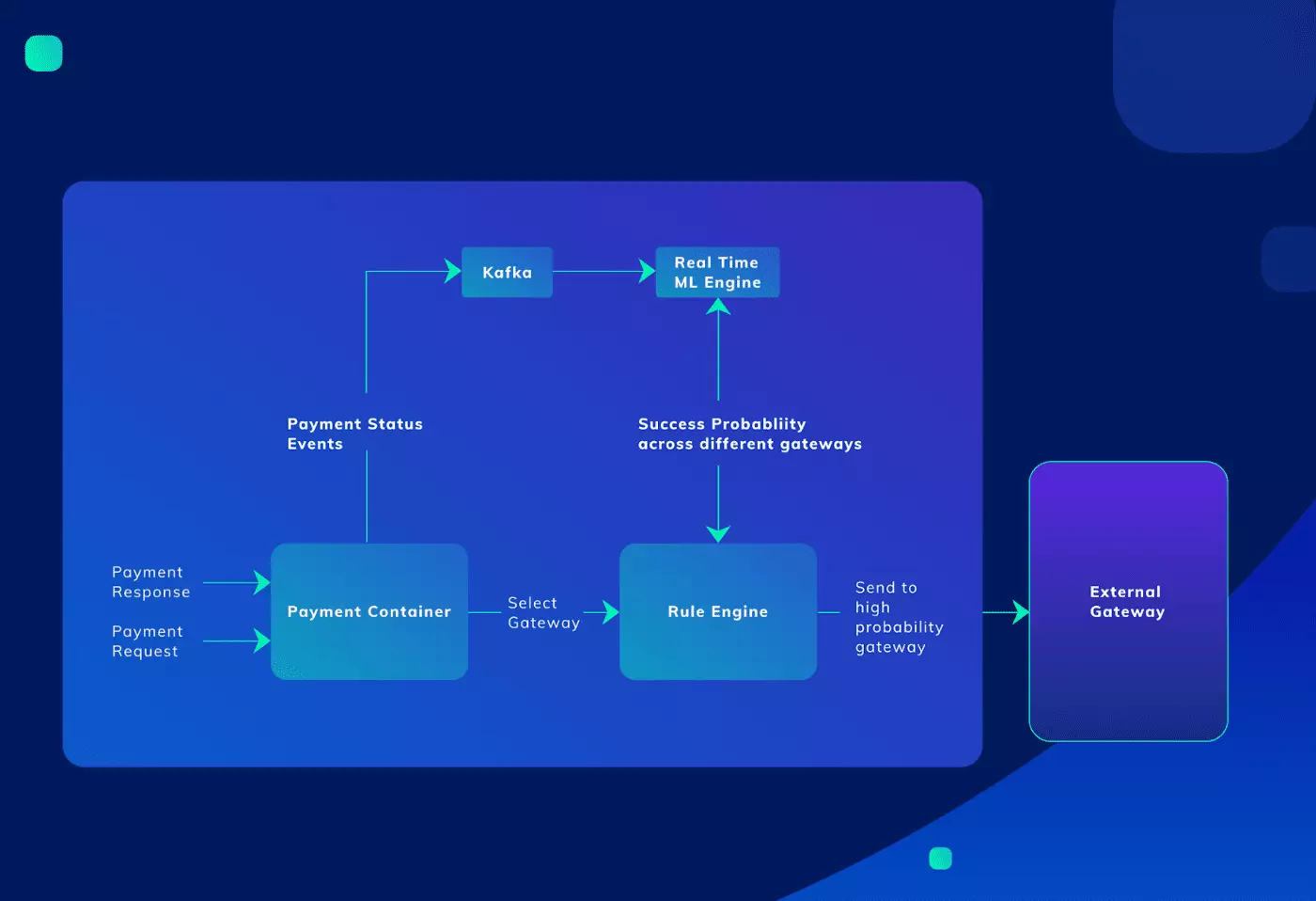
To deal with the challenge of high latency bank system responses during the traffic burst, a machine learning-based system was written to smartly route requests to other available bank systems.
Originally this routing was done manually, but when the peak load got to 200 to 1500 requests per second, manually routing the requests wasn’t viable anymore.
The machine learning system consumed payment success and failure events to predict in real-time where the payment requests should be directed. The model provided a probability of success with each banking gateway improving the payment success rate by 60%.
Besides these major changes, several other minor tweaks were made in the application and the infrastructure to help the system scale, such as code optimization, infrastructure automation, moving from synchronous to asynchronous processing, and so on.
Source: IPL: Razorpay’s second innings
If you wish to learn to design large-scale distributed systems starting right from zero, check out the Zero to Software Architect learning track, comprising three courses that I’ve written.
The learning track educates you step by step on the fundamentals of software architecture, cloud infrastructure and distributed system design, starting right from zero. It takes you right from having no knowledge on the domain to making you a pro in designing web-scale distributed systems like YouTube, Netflix, ESPN and the like.



Follow Me On Social Media