
{kind=link}
This article is a deep dive into the internal architecture of databases/DBMS (Database Management Systems). I’ll begin with a standard architecture relational databases have; will then take a peek into the architectures of a couple of real-world SQL databases and then, in the subsequent articles, will discuss the architectures of NoSQL databases post understanding a few distributed systems concepts.
With that being said, let’s jump right in.
Database Architecture
The sole purpose of a database is to efficiently and reliably store data and make it available to its clients with minimal latency.
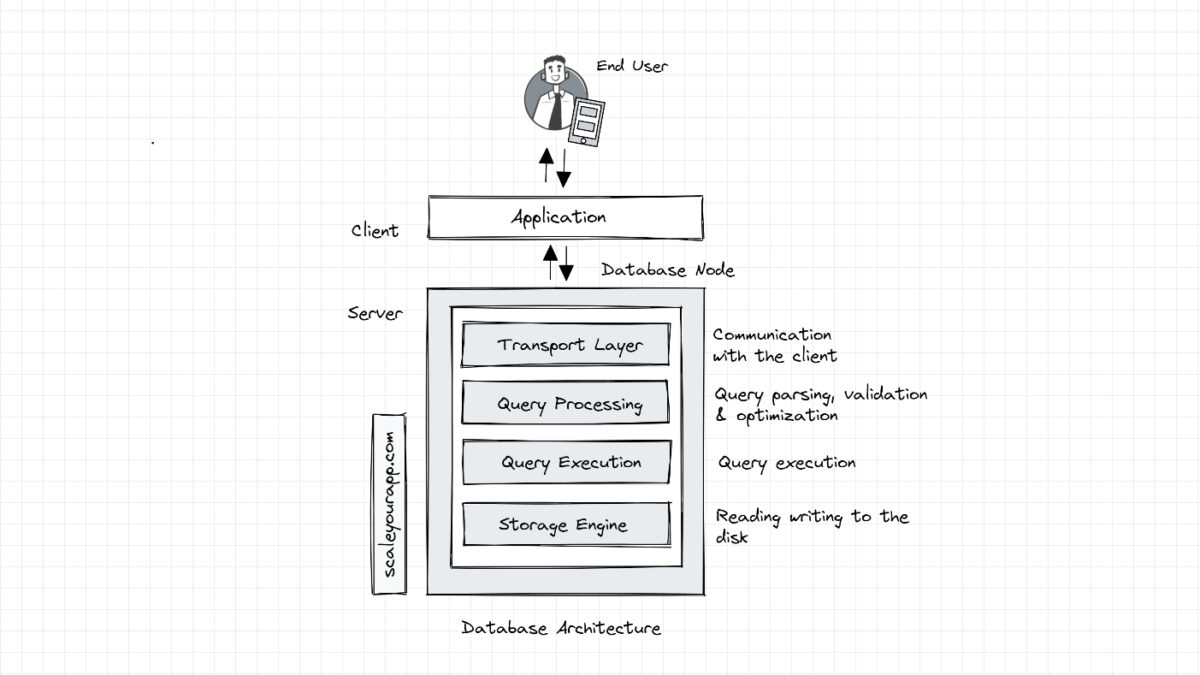
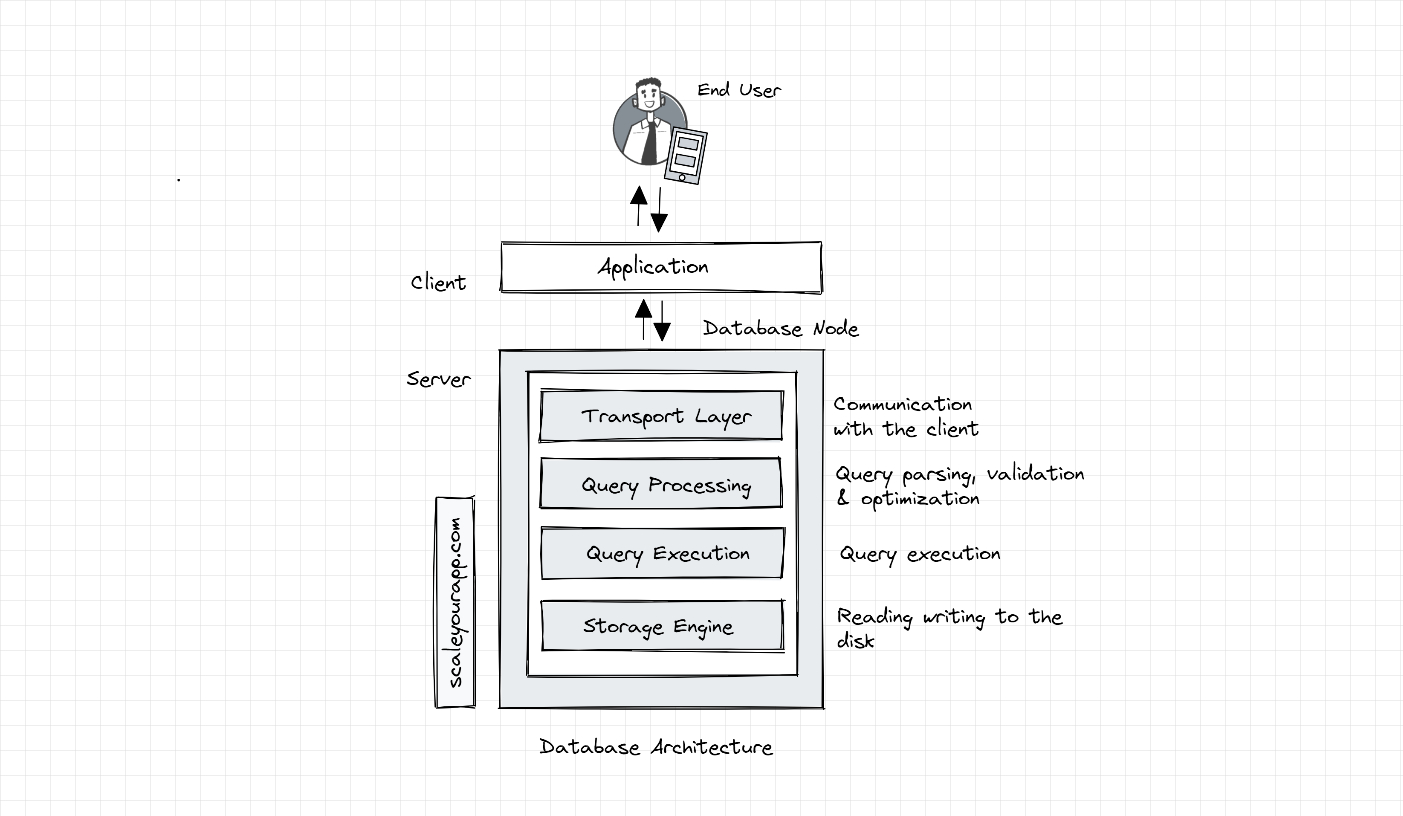
A typical strongly consistent ACID-compliant relational SQL database consists of several components/layers, such as the transport layer, query processor, execution engine and the storage engine layer. These layers have specific responsibilities, enabling the database to stay efficient and reliable.
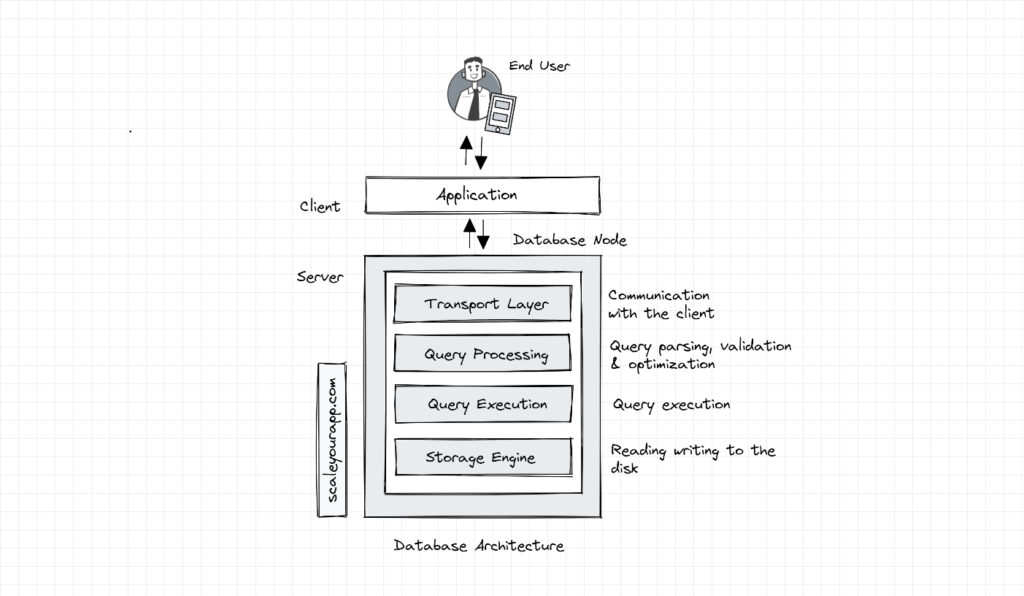
Databases have a client-server model where the database acts as the server and the transport layer accepts the request from the client (typically the application code) in the form of an SQL query.
The transport layer is responsible for facilitating the communication between the application instances and the database node. It manages the DB connectors for different programming languages, frameworks etc.
The transport layer also facilitates the communication of an individual DB node with other nodes in the cluster.
This layer subsequently passes on the query request to the query processing layer, which validates and parses the query and optimizes it in order to run it most efficiently to ensure minimal latency.
The optimized query (in the form of a sequence of operations, aka the query plan) is passed on to the query execution layer that executes the query and collects the results. The query can be run locally (on the same node) or in conjunction with other nodes in the cluster.
The local queries are executed by the storage engine through the execution layer. The storage engine is a pluggable component of the database that is in charge of running several key operations, such as handling the transactions by locking database objects, rolling them back in case of failures, managing concurrent requests (applying fitting transaction isolation levels, mapping them to underlying OS processes and threads), storing data most efficiently via different data storage structures and algorithms, caching data in memory buffers, logging operations and so on.
In the upcoming posts, I’ll explore how databases leverage different data storage structures and algorithms to store data efficiently.
Most databases have pluggable storage engines, which enables devs to change or tweak them based on their requirements. For instance, Facebook started with MySQL InnoDB engine to persist social data but faced data space and compression challenges. To tackle this, they wrote a new MySQL storage engine MyRocks to reduce the space usage by 50%. Here is a deep dive into the databases used by Facebook on this blog.
Recommended read: YouTube database – How does it store so many videos without running out of storage space?
Storage Engines
Every DB storage engine has its use cases, supports specific performance requirements and data access patterns and is leveraged by developers accordingly. Speaking of MySQL database, some of the storage engines supported by it are:
InnoDB: This is the default ACID-compliant transaction-safe storage engine that facilitates multi-user concurrency and optimized performance.
MyISAM: Mostly used for read-only or read-mostly workloads due to the table-level locking. This storage engine is used for its simplicity.
Memory: Stores all data in RAM and provides fast key-value lookups in massive distributed datasets.
Archive: This is used for storing large amounts of historical data. Primarily used for OLAP (Online Analytical Processing) use cases.
NDB: Suits applications that require the highest degree of uptime and availability.
These are a few of the many storage engines supported by MySQL. For further reading on this, check out this resource.
Similarly, MongoDB supports WiredTiger (the default storage engine) and an in-memory storage engine. The in-memory storage engine retains all data in-memory as opposed to the disk to ensure lower data latency.
Now, let’s look at the architectures of a couple of real-world databases.
MySQL Architecture
The diagram below shows MySQL architecture. As you can infer from the diagram, it almost has the same internal DB components as I discussed above.
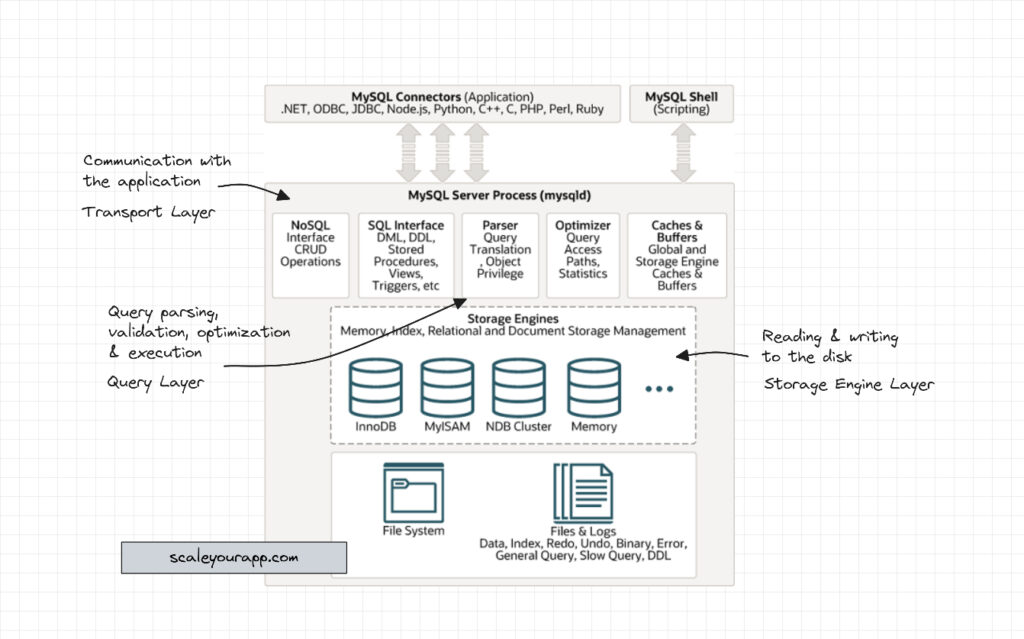
Database management systems wrap all the components and present the functionality to the client via an easy-to-use API.
CockroachDB Architecture
CockroachDB is a distributed SQL database built on a transactional and consistent key-value store. It is built for multi-cloud region and multi-data center deployments supporting strongly consistent ACID transactions along with horizontal scalability. DB clients can interact with data via the SQL API the database offers.
Let’s have an insight into its architecture and understand what’s happening under the hood.
A Cockroach DB node has several layers beginning with the SQL layer.
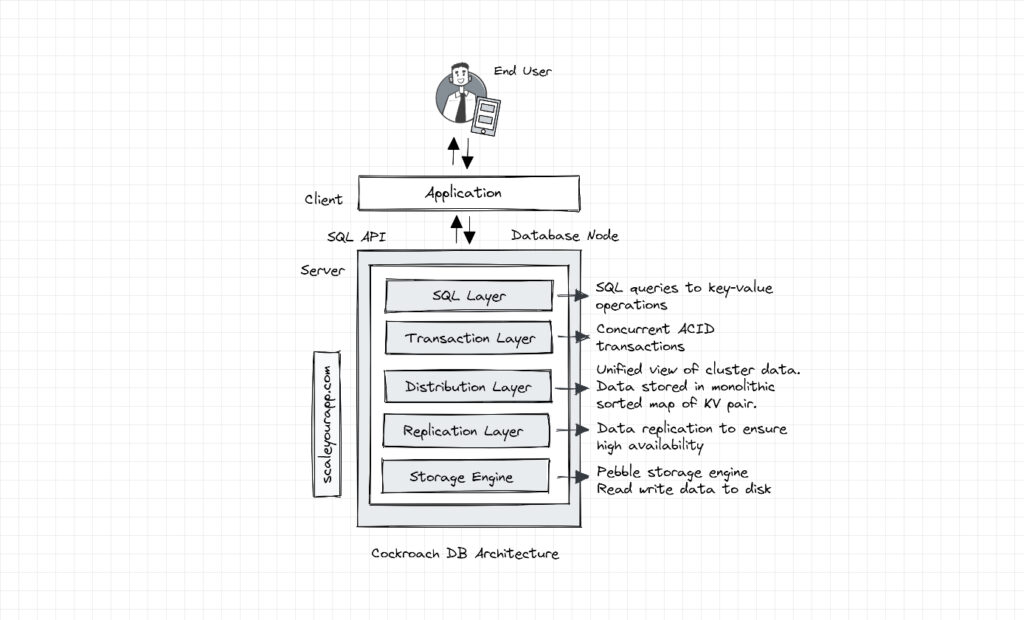
SQL Layer
This layer exposes the SQL API for the database clients. When it receives a request in the form of an SQL query, it performs several operations on it, such as converting SQL text into an AST (Abstract Syntax Tree).
AST is a data structure that is used to represent the structure of code. It primarily helps determine its syntactical correctness and convert the query into a format the database can work with.
The AST is further optimized into a logical and then physical query plan to be executed by one or multiple nodes in the cluster. Further, the SQL execution engine executes the query plans in the form of key-value operations to perform read and write requests working with the layers further down the database architecture.
In Cockroach DB, all the nodes in the cluster behave symmetrically so the client can send their request to any node in the cluster and whichever node receives the request, it acts as the gateway node processing the request.
Transaction Layer
The transaction layer manages concurrent transactions and facilitates ACID transactions spanning the entire cluster. The consistency is achieved using a distributed atomic commit protocol called Parallel commit, which I’ll be discussing in my future posts.
This layer sequences incoming requests and provides isolation between them throughout their lifetime via various DB isolation levels and locks to avoid conflicts.
Distribution Layer
The distribution layer provides a unified view of the CockroachDB cluster data. To achieve this, it stores data in a monolithic sorted map of key-value pairs.
The key space describes the data in the cluster, including its location. This key space is divided into contiguous chunks called ranges to ensure a range encompasses every key.
A DB table and its indexes are mapped to a certain range, where each key-value pair in the range represent a single row in the table. The sorted map helps CockroachDB identify which nodes hold certain data by scanning ranges.
When a range grows beyond a defined size, it is split into two ranges. As the data grows, new ranges are created due to the splitting of overgrown ranges.
The distribution layer automatically balances these new ranges to nodes with capacity. This is done with the help of gossip protocol, via which nodes share their network address, capacity and other required information.
How CockroachDB maps SQL data to key-value pair housed in ranges demands a dedicated article. I will be discussing it in detail in the near future on this blog.
Replication Layer
The replication layer takes care of data replication between nodes to ensure high availability. This is achieved with the help of the Raft consensus algorithm.
Replication ensures the data remains available even if a few nodes go down. When any failure occurs, the database automatically redistributes and replicates data keeping the cluster balanced to stay available.
Storage Layer
The storage layer reads and writes data to the disk. The data is in the form of key-value pairs, as discussed above. The storage engine used is Pebble.
Pebble (developed by Cockroach Labs) is inspired by RocksDB, the storage engine built by Facebook (which I brought up above), is written in Go and contains a subset of a large feature set that RocksDB has. It leverages the LSM (Log-structured Merge Tree) data structure to manage data.
Well, this is pretty much about the architecture of CockroachDB.
If you are wondering how are strongly consistent ACID transactions possible with horizontal scalability. Isn’t it against the CAP theorem? How does the transaction layer manage concurrent connections maintaining strong consistency?
I’ve discussed all that in detail in my Zero to Software Architecture Proficiency learning path. It is a series of three courses designed to help you understand how databases work, how large-scale services scale, what data model fits best in what use case, data consistency models, how nodes work together in a cluster, distributed SQL, distributed transactions, how databases handle growth and much much more. All concepts are explained step by step in a beginner friendly way. Check it out.
Thus far, we discussed the standard database architecture. We got an insight into the architectures of MySQL (an SQL database) and CockroachDB (a distributed SQL database) in addition to peeking into storage engines and how devs leverage them as per the requirements.
Next, we will look into the architectures of a few NoSQL databases, like ScyllaDB and ClickHouseDB and understand why their architectures differ.
Why do different databases have different architectures?
Databases have different architectures to address varying application/workload requirements such as serving analytics that typically require a column-oriented data storage, financial transactions that require strong consistency, storing time series data of IoT devices and so on. Some may be optimized for consistency, some for scalability and availability, some for specific data models, data access patterns and distributed system challenges such as node failures, replication, data partitioning, etc.
As an example, MySQL supports ACID transactions and strong consistency, ClickHouse DB is built for high-speed analytics, Cockroach DB excels in managing distributed transactions and ScyllaDB in high write throughputs.
Before we delve into the architectures of NoSQL databases, we need to understand parallel processing architecture—how cloud servers process data parallelly to increase the write throughput and such. This is the subsequent post to the current one you’re reading. Check it out.
If you found the content helpful, I run a newsletter called Backend Insights, where I actively publish exclusive posts in the backend engineering space encompassing topics like distributed systems, cloud, application development, shiny new products, tech trends, learning resources, and essentially everything that is part of the backend engineering realm.
Being a part of this newsletter, you’ll stay on top of the developments that happen in this space on an ongoing basis in addition to becoming a more informed backend engineer. Do check it out.
Folks! 👋🏻 If you found the content helpful, I’ll do a cartwheel if you share it with your network for more reach. I’ll see you in the next post. You can read about me here. Until then, Cheers!
Distributed Systems
For a complete list of similar articles on distributed systems and real-world architectures, here you go


Follow Me On Social Media