
{kind=link}
Understanding SLA (Service Level Agreement) In Cloud Services: How Is SLA Calculated In Large-Scale Services?
An SLA (Service Level Agreement) is a contract or agreement between a service provider and the consumer that defines the expectations a consumer should have from the service provided by the service provider. An SLA helps maintain service standards and establishes service providers’ accountability towards delivering a functional and performant service, fulfilling metrics stated in the SLA.
So, for instance, if I use a managed service of a certain cloud platform, for instance, a managed database, the SLA provided by the database service will be an agreement between the cloud provider and me on what I can expect from the managed service, i.e., the service quality, availability, reliability, query latency, disaster data recovery contingencies, etc.
Let’s understand this further with the help of a use case.
Understanding SLA (Service Level Agreement) With the Help Of A Use Case
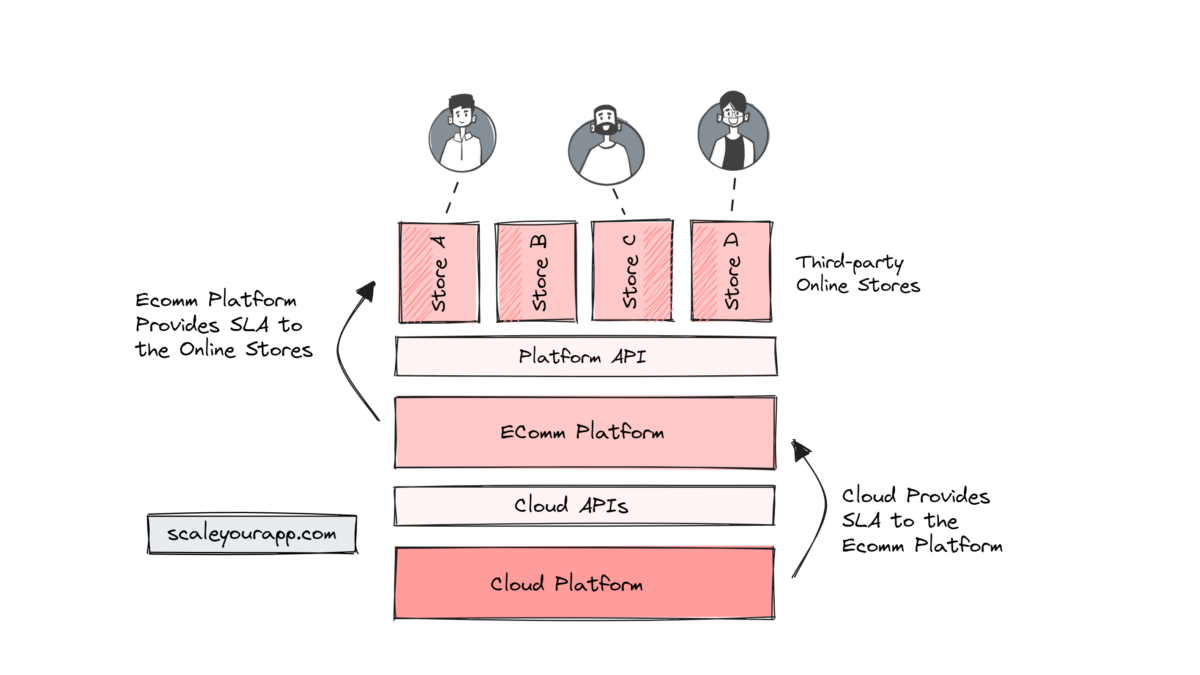
Imagine we run a cloud-based e-commerce service like Shopify that enables different business owners to set up their online store leveraging our platform.
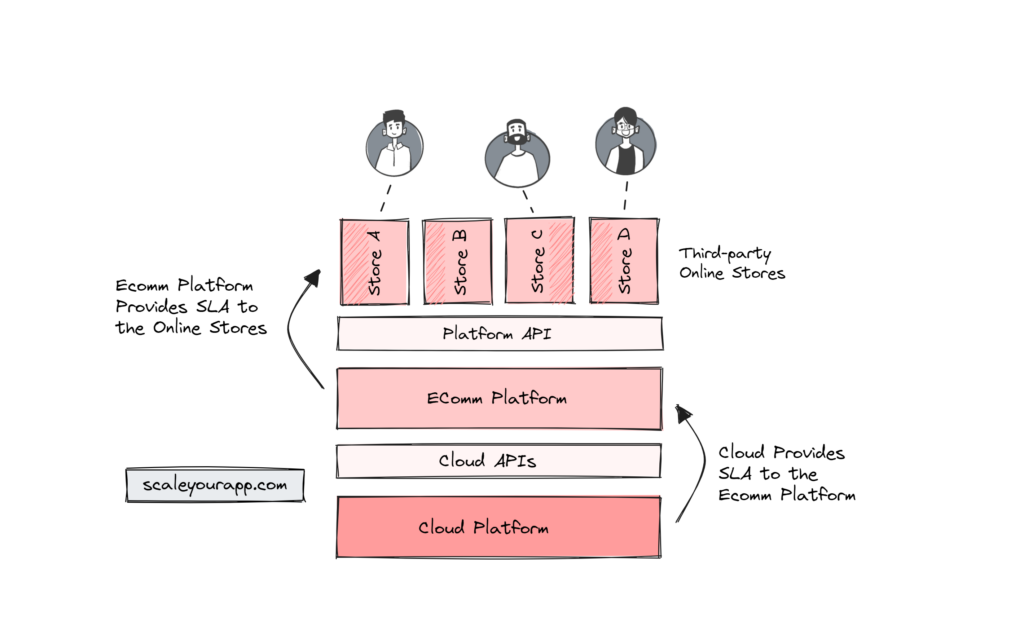
In this scenario, we have to provide an SLA to the business owners, which will be an understanding between our e-comm platform and them on the expectations they can have from our service.
What are these expectations?
SLA Metrics
Availability
The SLA will specify the platform availability. If it says, the platform availability is 99.999%. This means the platform cannot be offline for more than 5.26 minutes a year, 1.30 minutes per quarter and 25.9 seconds per month.
If the platform is unavailable for more than the stated time in the SLA, we have to compensate the users via financial credits or extend their subscription time, etc. The service level agreement will clearly state all these terms and conditions.
Besides availability, other metrics we typically find in cloud-based services SLAs are response time, scalability, security measures in effect, disaster recovery contingencies, etc.
Let’s quickly look into a few of them:
Response Time
An SLA may state maximum response times for certain features or microservices, like 200 milliseconds for loading product pages, processing transactions, etc.
Scalability
For scalability, the SLA may state the maximum number of concurrent transactions our platform will support for an individual e-commerce store without having a performance degradation.
Security
From a security standpoint, an SLA may contain the security and privacy standards the platform adheres to. How does it protect customer data from attacks? What happens if the customer data is breached? And so on.
Disaster Recovery
The customer, via an SLA, should also be aware of the platform’s contingencies to protect their data against natural disasters, region-wide power outages, etc.
Why Are These Metrics Stated In the SLA Important Or A Service Level Agreement as a Whole Important?
As mentioned above, an SLA establishes a clear understanding between the customer and the service provider on the service deliverability. Both parties have a common understanding in terms of service availability, reliability, scalability, performance and so on before doing business—this mitigates future contentions and risks.
These metrics are the baseline on which the service’s performance can be measured and evaluated by the customers and the service provider.
Having a well-defined SLA showcases the commitment the service provider has toward running a performant service. This often gives us a competitive edge in the market.
How Do We Create An SLA (Service Level Agreement) For Our Service?
Here is typically how things roll out: the system design process of our service begins with the software architects, developers, devops folks, stakeholders and other required roles designing the high-level service architecture and planning the infrastructure based on the business use case and requirements.
For instance, if we intend to run our service globally, we have to design a multi-regional cloud architecture to deploy our service across different cloud regions and availability zones. We also need to plan out the data storage and redundancy strategies staying in compliance with local data laws.
Once our architecture is designed, an initial version of our application is coded with various use cases implemented. Running and testing this system helps us gauge the system’s performance, possible bottlenecks, query patterns, etc.
Once we have an understanding of our system architecture, capabilities and bottlenecks, we can create an initial version of the SLA that we intend to share with our customers.
Metrics in an SLA are computed based on business goals and technical feasibility. We need to be certain on what level of availability allows us to hit our business goals. Having the service availability closest to 100% sounds great, but we also need to consider the infrastructure maintenance windows, infrastructure failures, network failures, storage issues, etc., that might occur. For this, we need to have an error budget.
What is an error budget?
Error Budget
An error budget is the amount of error that is okay to occur over time without making our service users unhappy.
Creating an error budget requires user behavior analysis, analysis of past traffic patterns, including other historical data, an understanding of business requirements, and the technical feasibility of hitting the business goals.
Infrastructure maintenance windows should be treated as downtime and included in the error budget.
So, for instance, if we promise an availability of 99.9% (“three nines”) to the customer, we are allowed a maximum downtime of 8.77 hours a year, which amounts to 2.19 hours per quarter, 43.83 minutes per month, 10.08 minutes per week and 1.44 minutes per day.
Here is the service availability chart that helps us gauge the downtime allowed based on the availability promised in the SLA.
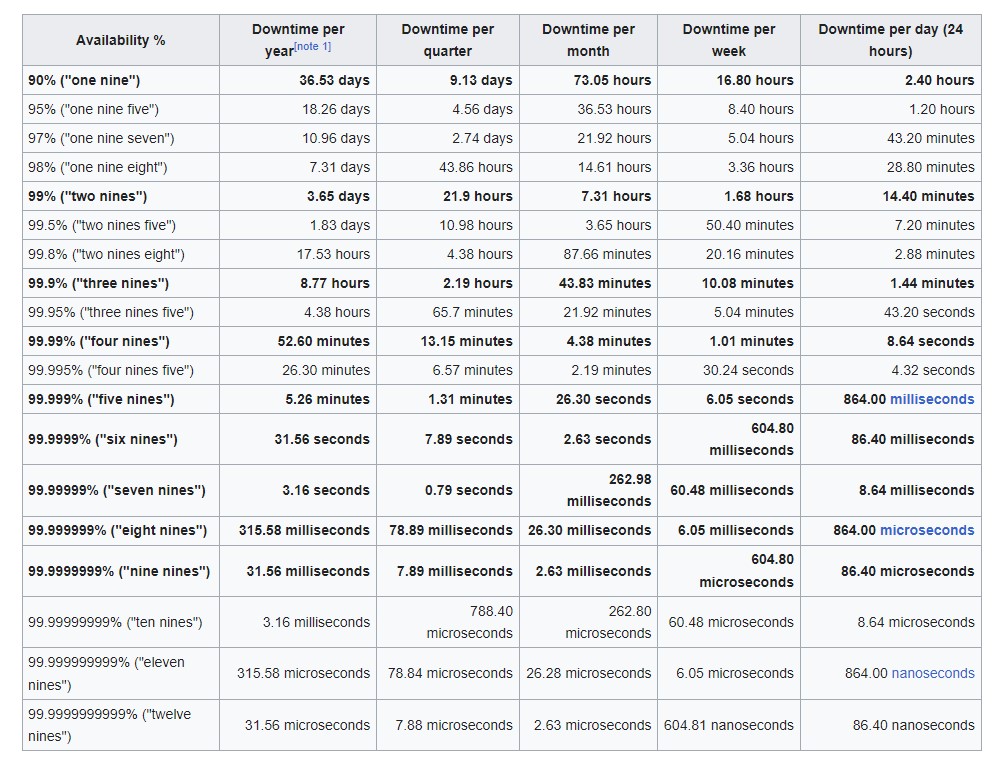
Source: Wikipedia
Now, our error budget, which is 2.19 hours a quarter, includes maintenance windows, infrastructure failure issues, high service latency, request failures due to software issues, and everything that could possibly go wrong with the service.
If just our maintenance window in a month stretches for, say, 3 hours, we are way over our error budget. Sometimes, due to legacy system architecture, tightly coupled service modules and other reasons, it’s hard to reduce the span of maintenance windows. We must keep all these things in mind when stating the metrics in our SLA.
Aligning SLA Metrics With Our Business Goals
Staying close to 100% service availability is great. However, we need to keep a balance between the SLA metrics and our business goals.
Imagine our service receives 100K requests a day and the request failure rate is 10%. Despite the 10% failure rate, we continually hit our revenue goals. Here, we have to evaluate if investing ‘n‘ engineering resources to bring down the failure rate would be worthwhile or if we could invest that many engineering resources in developing a platform feature that is highly requested by the customers.
In this scenario, we need not promise our customers 99.999% availability but rather less, keeping the system as available as required.
Dependence On Underlying Service Infrastructure
Our e-comm service’s SLA also largely depends on the underlying public cloud platform’s (AWS, Azure, Google Cloud, etc.) infrastructure and managed services (cloud API gateways, load balancers, databases, message queues, etc.) our service leverages.
We need to thoroughly understand the underlying infrastructure, including managed cloud services and their SLAs.
You can find the SLAs of different services Google Cloud offers here. Here are the SLAs of various AWS services.
Once we have created an initial version of our SLA we can fine-tune our architecture to ensure the system meets the specified performance and availability goals.
This process will involve adding redundancy and failover mechanisms to different application components, implementing caching to improve performance, optimizing the infrastructure and code, implementing load balancers to improve availability, and so on. I’ll write a detailed article on cloud architecture following this article. You can subscribe to my newsletter to get it in your inbox.
After all the refinements, we test the system with stress, performance and load tests. This provides insight into how our system is doing. Does it meet the specified SLA metrics?
Our system must also be ready for the holiday period to deal with the traffic spikes. Additional resources need to be allocated to enable the system to autoscale. Devs and the infrastructure team must plan resource provisioning and scaling strategies to accommodate the increased load.
Once the system is ready, the service launched and the SLA shared with the customers, we need to monitor our system continuously to ensure the service is available and performant.
If you wish to gain a detailed insight into how large-scale services are designed, including topics like cloud infrastructure, how to prepare our infrastructure for seasonal traffic spikes, scaling strategies, strategies of handling web-scale concurrent production traffic and more, check out Zero to Mastering Software Architecture learning path, comprising three courses, I’ve authored. The learning path takes you right from having no knowledge of web architecture to making you a pro in designing large-scale distributed systems like YouTube, Netflix, Hotstar, and more.
Thorough System Testing For Accurate SLA Metrics
Thorough system testing is vital to determine accurate SLA metrics. The system should be redundancy tested across machine clusters, data centers, availability zones, and cloud regions (if deployed globally) by injecting failures into the system like simulated hardware failures, network interruptions, notching up the request latency, etc.
Heavy concurrent traffic should be simulated with continual infrastructure monitoring to test for scalability, possible bottlenecks, etc.
If failures occur, we should record the average time of certain modules or the entire service to bounce back. These steps are key in accurately determining the SLA metrics.
Roles Of Different Teams In Computing SLA & Internal SLAs
Creating a service level agreement for a large-scale service involves setting up internal business use cases or module-based SLAs assisted by several roles, such as product managers, business analysts, operations teams, developers, network engineers, software architects, QA, security teams, etc.
Setting up internal SLAs helps establish accountability, expectations and performance benchmarks within the organization.
The product managers, product owners and business analysts work closely with stakeholders, understanding the business requirements and market expectations. This helps set service quality, availability and performance baselines.
Developers and operations teams determine the technical feasibility of meeting the set SLA metrics. They may have internal deployment SLAs that encourage them to deploy new features or updates to be pushed to production within a couple of days of code complete.
Time-boxed code review SLAs make the teams complete code review within a stipulated time. Bug-fix SLAs set expectations of fixing critical and high-priority bugs in minimal time.
Infrastructure provisioning SLAs establish how quickly the infrastructure resources should be scaled up and down based on the demand, in addition to, setting the frequency for data backups, running disaster recovery tests etc. All these SLAs facilitate accelerated development and deployment.
Software architects actively keep an eye on the service architecture to ensure the service continually fulfills the SLA metrics.
Network engineers provide input on the network latency, bandwidth consumption, network uptime and such and ensure that the network design and performance meet the SLA metrics.
These internal SLAs prove effective in speeding up service development, deployment, monitoring, bug fixing, improving collaboration amongst different teams in the organization, and streamlining the entire process.
Folks, this is it. If you found the content helpful, consider sharing it with your network for more reach. I am Shivang. Here are my X and LinkedIn profiles. You can read about me here. I’ll see you in the next blog post.
Until then, Cheers!
Check out the Zero to Software Architecture Proficiency learning path, a series of three courses I have written intending to educate you, step by step, on the domain of software architecture and distributed system design. The learning path takes you right from having no knowledge in it to making you a pro in designing large-scale distributed systems like YouTube, Netflix, Hotstar, and more.



Follow Me On Social Media