
{kind=link}
System Design Case Study #3: How Discord Scaled Their Member Update Feature Benchmarking Different Data Structures
The member list update feature in Discord servers became quite a bottleneck in terms of memory & CPU usage because the system had to update the entire member list in every Discord server every time someone joined or left the server, changed their status (online, offline, idle, do not disturb, etc.) or the member role was changed.
Member updates in respective Discord servers with hundreds of thousands or even millions of users in real-time made the system do a lot of processing, which was resource-intensive.
If you are wondering why the entire member list needed to be updated as opposed to updating only the delta in case of a member status change event occurred, here’s why: the system keeps track of an aggregate number of users in respective Discord servers along with an order; users are arranged by their online status, roles, permissions & other criteria. If the status of users changes, the list has to reflect that and the order has to be updated.
The members’ order helps the system connect online users based on their roles and permissions in the server. This enables users to easily identify and communicate with those who share their interests, preferences, or goals in the server.
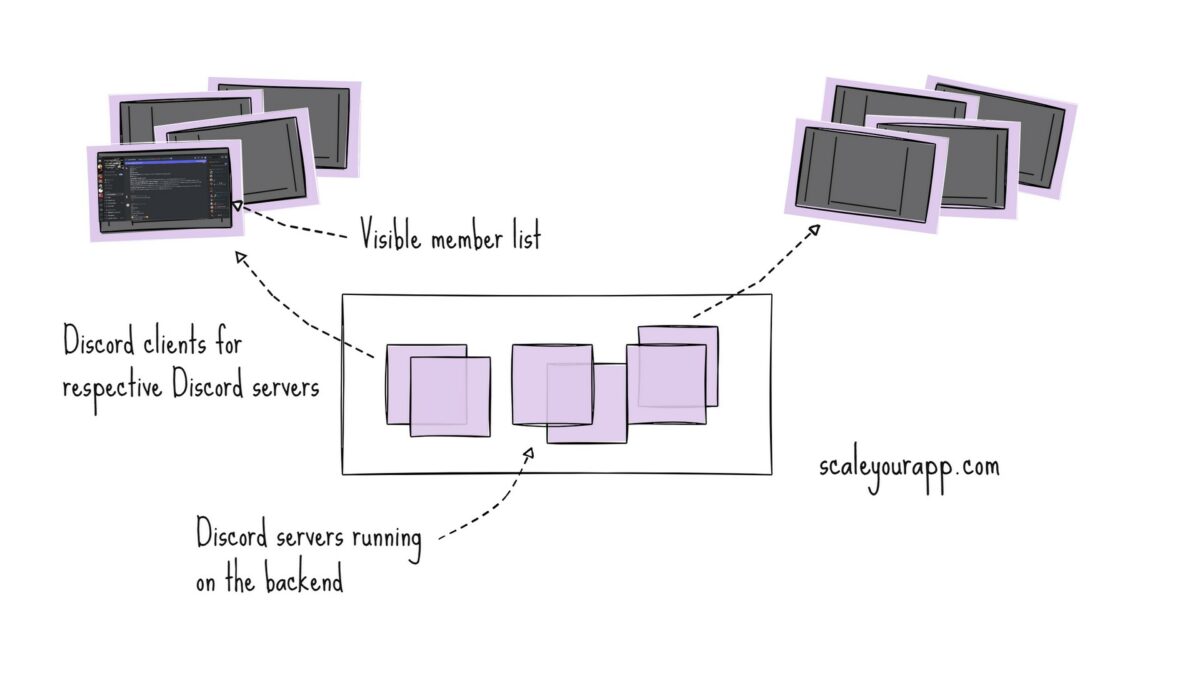
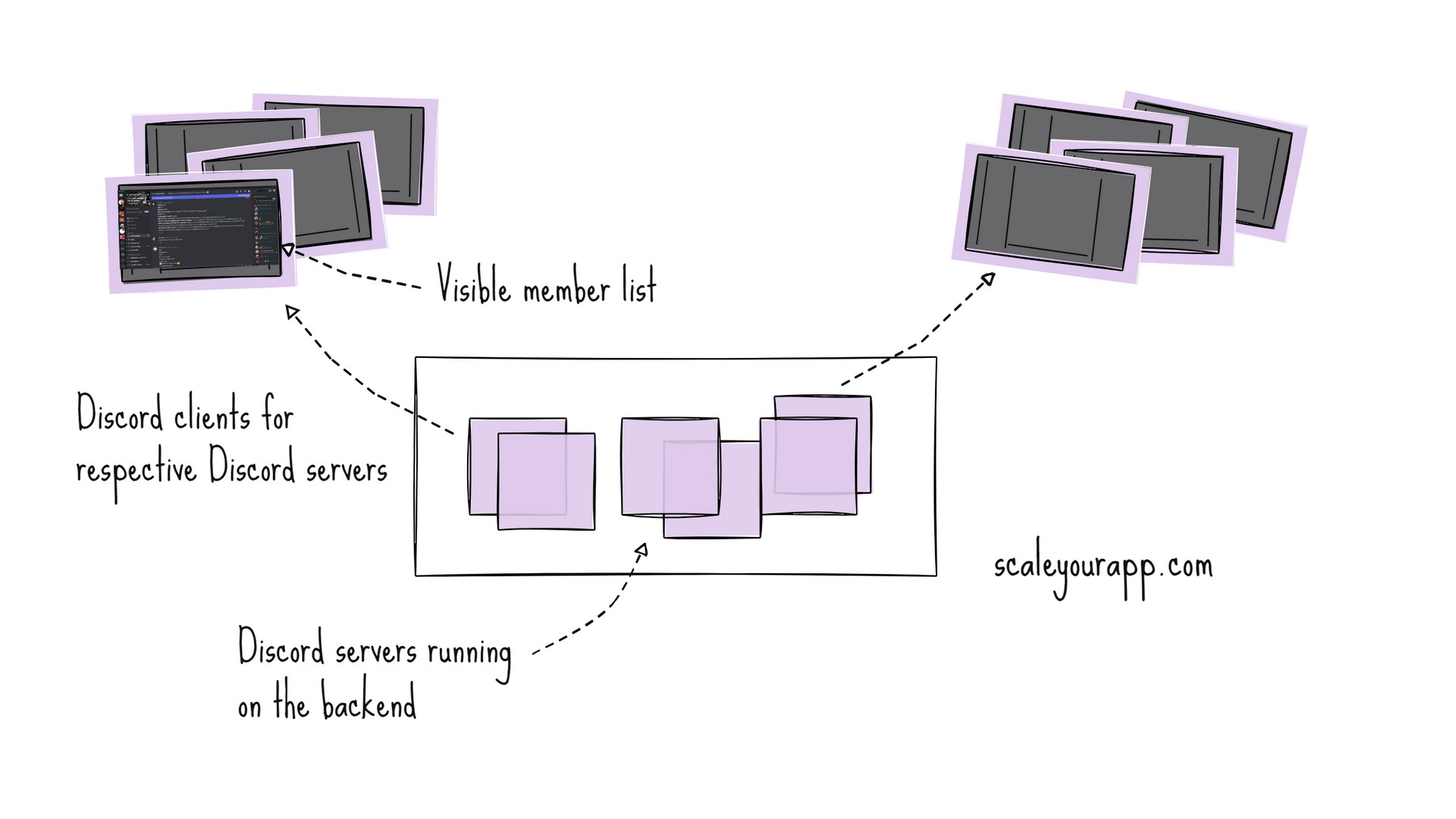
Along with rearranging the member list of respective Discord servers on the backend, the updates needed to be sent to the Discord clients in case any member in the list got updated. This meant a lot of push updates to Discord clients.
To optimize this, for a given Discord server, as opposed to pushing updates to the Discord clients whenever a member in the list got updated, updates were pushed only for those updated members that were visible in the Discord window of respective clients.
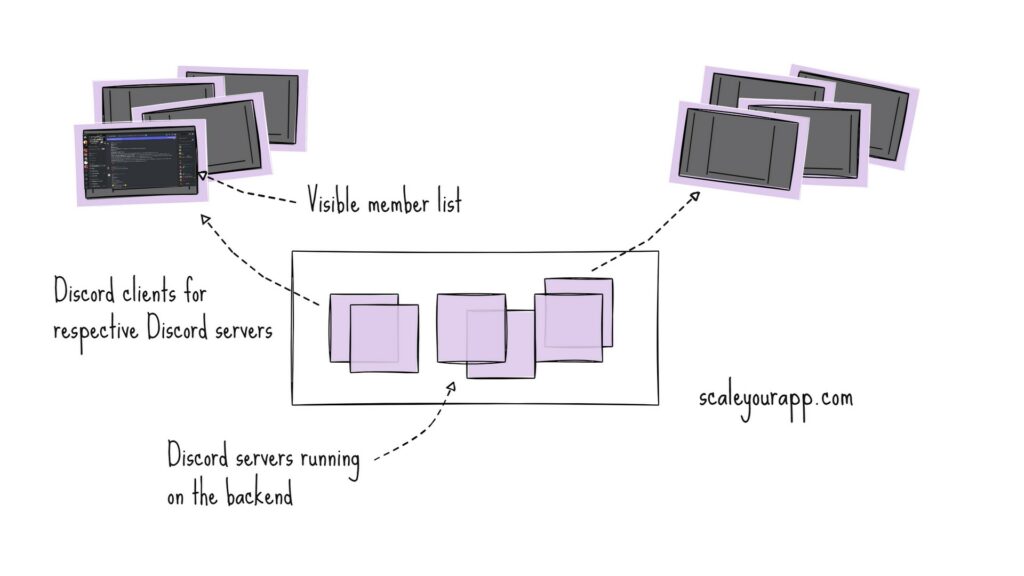
This cut down the network traffic, CPU and other resource consumption starkly.
To handle the member updates on the backend efficiently, Discord needed a data structure that could handle an ordered set of members while accommodating real-time mutations within specified time constraints.
Various Elixir data structures were considered (Discord is coded in Elixir), such as MapSet, a custom List type (that could enforce uniqueness and sort the list after the insertion of new elements), an OrderedSet and a SkipList.
MapSet provided no guarantees around member ordering. The custom List type element insertion time benchmark was too slow and did not scale well as the number of members in the list increased. Adding an element to the end of a 250,000 item list took an eternity (170,000𝜇s).
The same was the issue with the OrderedSet (27,000𝜇s) & the SkipList (5,000𝜇s). Though these were faster than the custom list, but still too slow.
In addition, with SkipList, a new worst case of insertion at the beginning of the list had been created; a 250,000-item list was clocking in at 19,000𝜇s.
They further tweaked the OrderedSet to reduce the time it took to insert an item at the end of the list with a list size of 250,000 to 640𝜇s. This was good, but was this certainly not the best with the increasing user counts in Discord servers.
The Need for a Fitting Technology
As I mentioned earlier, Discord’s core services had been written in Elixir running on BEAM VM. Elixir is a functional programming language based on Erlang, known for its support for concurrency and fault tolerance.
Though Elixir is fit for implementing high IO, non-blocking real-time services like Discord, single-threaded Elixir processes aren’t best suited to run CPU-intensive tasks.
If you wish to delve deep into how single-threaded architecture suits best for IO-bound services and is not fit for CPU-intensive tasks, here is a detailed discussion on single-threaded, non-blocking systems on this blog.
Furthermore, the Elixir data structures are immutable to support concurrency and this has high memory consumption since every time there is a mutation, a brand new data structure needs to be created after applying the operation to the existing data structure.
Discord had been using Rust as well, and the language allowed the mutation of data structures without the need to create a new one. Elixir’s BEAM VM supports Rust code with native implemented functions NIFs and, leveraging that Discord With Rust achieved the worst-case performance of 3.68𝜇s with a SortedSet with 1,000,000 members. Thus, a Rust-backed SortedSet powers the member list update feature in Discord servers.
Key System Design Learnings from this Case Study
There Is No Silver Bullet
Though we witness the cheering and support for the latest shiny new technologies all the time, along with page-long rationales on how the existing tech is doomed and the new tech is the future, there is no silver bullet.
Every technology has a use case and performance limitations. Elixir helps with the implementation of an IO-bound, non-blocking service but needs immutable data structures for concurrency, which in turn has high memory usage. Elixir processes are single-threaded, lightweight and isolated units of computation that can communicate with each other through message passing.
In contrast, Rust suits compute-intensive operations supporting mutable data structures. It offers low-level control over memory with threads, async/await, etc. With threads, the programming language can leverage the power of multiple CPU cores, executing CPU-intensive operations and making the code more performant.
Here are two relevant reads on this I’ve written in the past:
1. Parallel Processing: How Modern Cloud Servers Leverage Different System Architectures to Optimize Parallel Compute
2. Single-threaded event loop architecture for building Asynchronous, non-blocking, highly concurrent real-time services.
Benchmarking Saves the Day
Benchmarking becomes crucial when our systems deal with large volumes of traffic and data. It helps us gauge the performance characteristics of different data structures and algorithms under different workloads.
This is key when implementing scalable systems as we might think a Map, Set or a List might best fit our use case, but it may not give the required performance when subjected to production traffic and data. This is what we learned in Discord’s case. We should scan for potential bottlenecks in our systems and leverage the most efficient components based on benchmark results. Addressing these bottlenecks can result in stark performance improvements in our code.
Also, benchmarking, stress testing, scanning for bottlenecks, etc., to maintain the SLA aren’t a one-time thing but rather an ongoing process as long as our service is in business.
Let’s discuss benchmarking a bit more.
Consider a scenario where we need to store a million users in-memory. At what point and how should we benchmark our code?
Multiple things are involved in ensuring our code/system scales well with the use case requirements. For instance, when implementing a use case, we will first pick the fitting data structure based on the data access patterns and the in-memory data storage and mutation operations (insertion, deletion, updation, search, etc) requirements.
Consider the worst-case time & space complexities of the picked data structure. Refer to this Big O cheatsheet.
For instance, let’s say the List data structure fits best to store a million users in-memory. We will check the average and the worst-case time & space complexities of the insertion, deletion, and search operations on the list and analyze if it meets our memory and time constraints.
If it doesn’t, we will find a different data structure that fits our requirements or we may have to write a custom data structure as well.
GitHub wrote a custom data structure called the Geometric filter to determine the optimal ingest order and to tell how similar one repository is to another in terms of its content for their search engine. I’ve done a case study on how GitHub indexes data for search. It is pretty insightful. Check it out here.
We could next do a memory profiling of the system to understand its current memory usage. That would help us make further decisions, such as:
- If the users could be lazy-loaded or paginated from the DB as opposed to eagerly-loaded
- If the system garbage collection and memory management needs to be tweaked to cut down on memory usage to help with the feature performance.
- If the data model needs to be optimized.
- If the server node requires external persistent memory and so on.
Benchmarking can be done in both our local machines and a dedicated simulated production environment with the help of technology-specific benchmarking tools.
In addition, we need a rough idea of the target hardware our code will run on to get insights into the available memory, CPU capacity, network capabilities, storage and so on. This helps us design our system to run efficiently on the target environment.
Based on the profiling and benchmarking results, we can tweak our systems and ensure our application is ready to handle the expected workload without any memory or performance issues in production.
Ideally, in production, the hardware and the infrastructure should exceed in capacity from the one used in benchmarking and performance testing.
Memory and performance optimization are ongoing concerns that we need to delve into as the traffic on our application grows and our application evolves.
If you’d like to delve deeper into this or share your insights, feel free to tag me on LinkedIn and Twitter to kickstart a discussion. I’d love to hear from you.
If you wish to take a deeper dive into how scalable systems are designed, in addition to mastering the fundamentals of distributed system design and the underlying cloud infrastructure that powers our services, check out the Zero to Mastering Software Architecture learning path comprising three courses I’ve authored.
This learning path offers you a structured learning experience, taking you right from having no knowledge on the domain to making you a pro in designing web-scale distributed systems like YouTube, Netflix, ESPN and the like. Check it out.
I explore real-world architectures to understand the architectural and system design concepts web-scale companies leverage to scale, stay available and fault-tolerant.
Here is the former case study: How GitHub Indexes Code For Blazing Fast Search & Retrieval. Check it out.
Information source: Discord Engineering
I am Shivang. Here is my X and LinkedIn profile. Feel free to send me a message. If you found the content helpful, consider sharing it with your network for more reach.
I’ll see you in the next post. Until then, Cheers!
If you wish to receive these case studies and behind-the-scenes info along with subscriber-only content in your inbox, consider subscribing to my newsletter.


Follow Me On Social Media