
{kind=link}
Leveraging the Backends for frontends pattern to avert API gateway from becoming a system bottleneck
In this system design series, I discuss the intricacies of designing distributed scalable systems and the related concepts. This will help you immensely with your software architecture and system design interview rounds, in addition to helping you become a better software engineer.
Here is the first post of this series (CDN and load balancers). If you haven’t read it, it’s a recommended read. With that being said, let’s get started.
In my previous post, I discussed API gateway and the advantages of integrating it into our application architecture.
Introducing an API gateway brings along several upsides but also has a potential downside that is becoming a single point of failure and an application bottleneck since the entire traffic routes through it.
In this post, I’ll discuss how we can leverage the Backends for Frontends pattern with API gateways to tackle the system bottleneck issue.
With that being said, let’s get started with having an understanding of the system design pattern.
BFF (Backends for Frontends) pattern
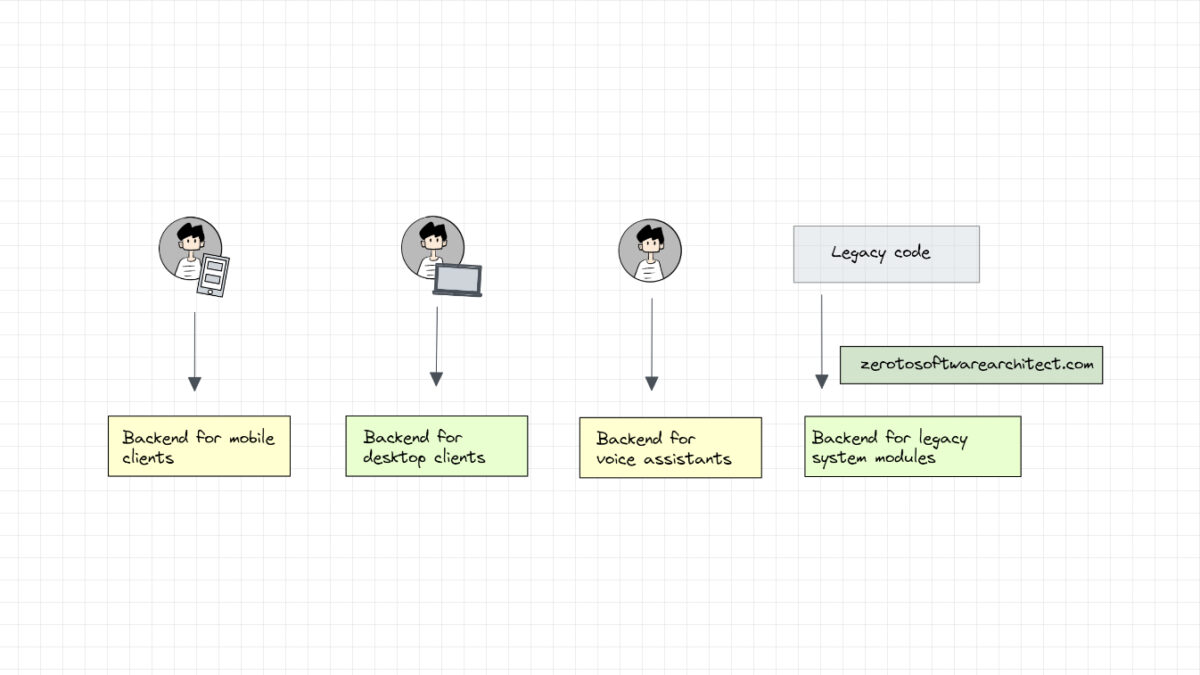
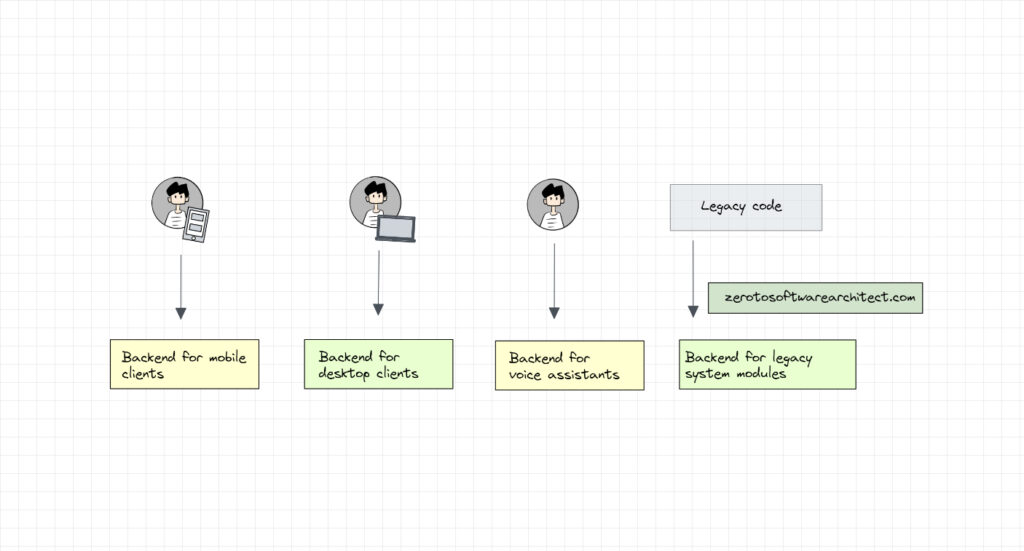
With the Backends for frontends pattern, we can have different backends for different types of clients in our application. For instance, if our application has a mobile client, a desktop client, a voice assistant client and other legacy application modules interacting with our backend, we can have separate backends for every type of client.
We will have a backend handling the requests from the desktop, another backend handling mobile traffic, another handling voice assistant requests and so on.
How does this help?
Having different backends based on the type of client helps us get rid of single point of failure in our architecture, prevent a single backend component from becoming a system bottleneck and implement client-specific functionality on dedicated backends.
This is similar to the microservices concept, like how microservices increase the fault tolerance of the system. When a single or a few microservices go down, the system may work with reduced functionality but would not go down completely. Similarly, with the BFF pattern, a backend for a certain type of client may get impacted without impacting the backends of other client types.
With the BFF pattern, we can implement client-specific functionality on dedicated backends. For instance, the mobile client may need a set of services that are location-specific and data optimized, keeping the device’s battery consumption in mind. The voice client would need some other services related to voice processing and so on. We can separately implement these services on respective backends dedicated to the specific type of clients as opposed to having all the functionality implemented in a single backend ending up bloating it.
This makes the backend implementation less tricky, maintainable and manageable. Changes can be made to a specific type of backend without impacting other types of backends. So, for instance, if something goes horribly wrong with the voice assistant backend and it dies, the mobile and desktop-based services won’t be impacted.
Now, let’s see how we can leverage this application design pattern to avoid our API gateway from becoming a system bottleneck.

API Gateway and BFF pattern
In our API gateway scenario, just like the backends for frontends pattern, we can have a separate API gateway for the mobile client, desktop client, voice assistant, and so on. With this, instead of the total application traffic being routed through a single API gateway, it now routes through multiple gateways.
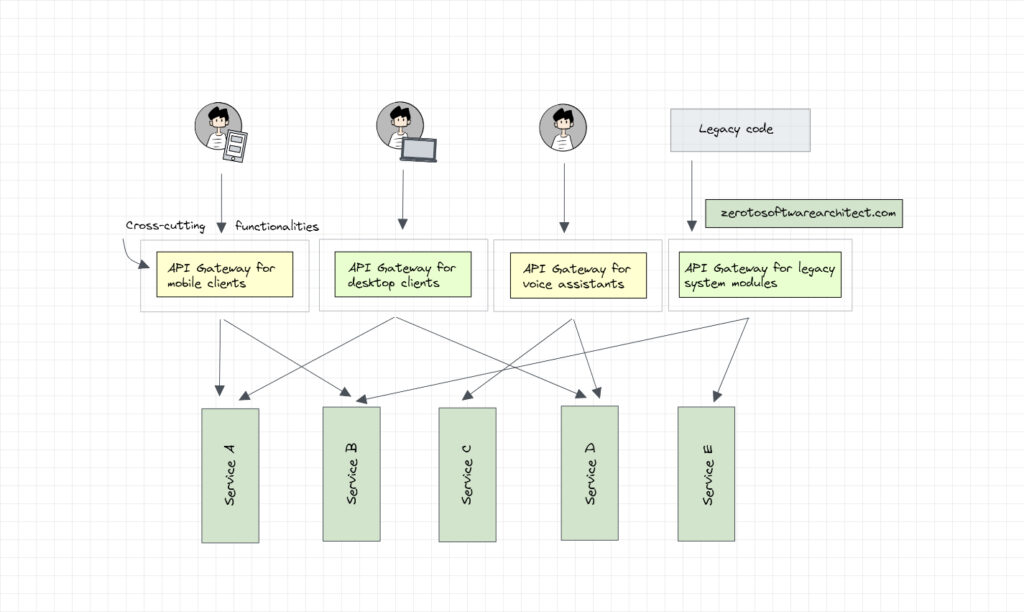
We can further add more API gateways to our architecture based on the use case. For instance, we can introduce an API gateway for the Android OS client and another for the iOS. However, we have to keep a check on the number of API gateways used. If we keep increasing their number in our architecture, it will defeat the whole purpose of using an API gateway in the first place.
Routing client-specific traffic through dedicated API gateways helps us enforce client-specific routing policies and related business logic. This enables us to maintain different versions of client-specific APIs keeping things cleaner and maintainable.
Folks, this is pretty much it. Consider sharing this post with your network for better reach.
Check out the next post in the series, where I discuss the actor model to build non-blocking, high-throughput distributed systems.
Check out the Zero to Software Architecture Proficiency learning path, a series of three courses I have written intending to educate you, step by step, on the domain of software architecture and distributed system design. The learning path takes you right from having no knowledge in it to making you a pro in designing large-scale distributed systems like YouTube, Netflix, Hotstar, and more.
You can also subscribe to my newsletter to get the content I publish in your inbox. I am Shivang, you can read more about me here. I’ll see you in the next blog post, until then, Cheers.


Follow Me On Social Media