
{kind=link}
System Design Case Study #2: How GitHub Indexes Code For Blazing Fast Search & Retrieval
GitHub coded their search engine from scratch in Rust called Project Blackbird because existing off-the-shelf solutions didn’t fit their requirements at the scale they were operating. The engine supports features like searching with identifiers, punctuations, substrings, regular expressions, wildcards, etc., which are specific to code searches in contrast to regular text-based searching.
The search engine also supports global queries across 200 million repos and indexes code changes in repositories within minutes. The code search index is by far the largest cluster that GitHub runs, comprising 5184 vCPUs, 40TB of RAM, and 1.25PB of backing storage, supporting a query load of 200 requests per second on average and indexing over 53 billion source files.
Indexing Code
GitHub precomputes information as indices, which are keys to sorted lists of document IDs. For instance, here is how an index is created for search by programming languages: they scan each document to detect what programming language it’s written in and then assign a document ID to it.
| Doc ID | Content |
|---|---|
| 1 | def lim puts “mit” end |
| 2 | fn limits() { |
| 3 | function mits() { |
Then, an inverted index is created where the programming language is the key and the value is the list of document IDs where the programming language appears.
| Language | Doc IDs (postings) |
|---|---|
| JavaScript | 3, 8, 12, … |
| Ruby | 1, 10, 13, … |
| Rust | 2, 5, 11, … |
For code search, they need a special type of inverted index called an n-gram index, which helps find substrings of content.
N-grams
The n-gram index helps implement the “search as you type” functionality by predicting the most probable word that might follow in a sequence. It’s a probabilistic model trained on a corpus of data that facilitates partial matches, similar text etc., even with spelling mistakes or variations in the input query.
N-grams are sequences of n characters or words extracted from a certain text. So, for instance, in 3-gram indexing, the text “Python” will be split into “pyt”, “yth”, “tho”, “hon”.
The generated 3-grams can be indexed in a data structure like a hash table or a search tree. Each n-gram will be associated with the location of the document where it occurs.
Here is how an n-gram index will look like:
| ngram | Doc IDs (postings) |
|---|---|
| pyt | 1, 2, … |
| yth | 2, … |
| tho | 1, 2, 3, … |
| hon | 2, 3, … |
When running a search query, the query is broken into n-grams in the same way as it is indexed and then those n-grams are matched with those in the index to retrieve a list of matching documents.
A search engine can have dynamic values of n in an n-gram based on the search query, context and data indexed.
The indices created by the GitHub code search engine are too big to fit in-memory, so GitHub built iterators for each index to access the elements of each index sequentially without loading the entire index into memory.
To index 200 million repositories with duplicate content, GitHub leverages content addressable storage.
Content Addressable Storage
Content-addressable storage is a technique of storing data where, as opposed to saving it via file name or the file location, it is stored based on the unique hash generated by the content. This helps eliminate duplicate content, reducing storage space and costs significantly.
The hashes are computed from the actual content of data with hash functions such as MD5, SHA-1, SHA-2, SHA-256, etc., generally used to generate hashes. Since the hashes are unique and change on data updation, this approach provides strong data integrity.
If the data changes over time, different hashes will be created, enabling us to access different versions of data while maintaining a version history.
CDNs use this technique to efficiently cache and distribute data in edge regions worldwide.
GitHub leveraged this approach to reduce 115TB of data to 28TB of unique content. After compression, the entire index was just 25TB, including all the indices, including the ngram indices and all the compressed unique content. Content addressable storage reduced the total data size to roughly a quarter of the original data.
GitHub distributes data across shards evenly based on Git blob object ID. This helps horizontally scale the system. It can handle more QPS (Queries Per Second) by spreading queries across shards. Data can be spread across disks for increased storage space. And data indexing time goes down, which is constrained by CPU and memory limits on individual hosts.
Now, let’s quickly understand how GitHub stores blob data.
Code Storage
Git stores its data based on content hash as a blob object in an object store, which at core is a key-value data store.
Though Git is built to store code, it stores docs, config files, images, PDFs, etc., in repos, making the data unstructured fit for object storage. Whatever data goes into Git has a unique key (blob object ID) that can be used to retrieve it.
This way, the object store acts like a key-value database table with two columns: the object ID and the object content.
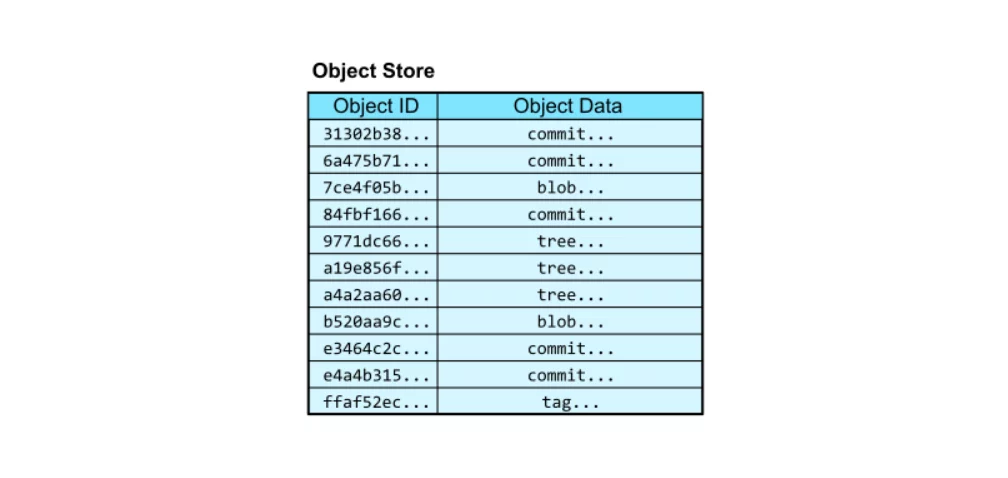
Img src: GitHub
The blobs are raw data. These do not contain the file names and other metadata such as repo name, owner, visibility etc. All this information is stored in trees. Trees are paired with objects to store a hierarchy of files in a repository.
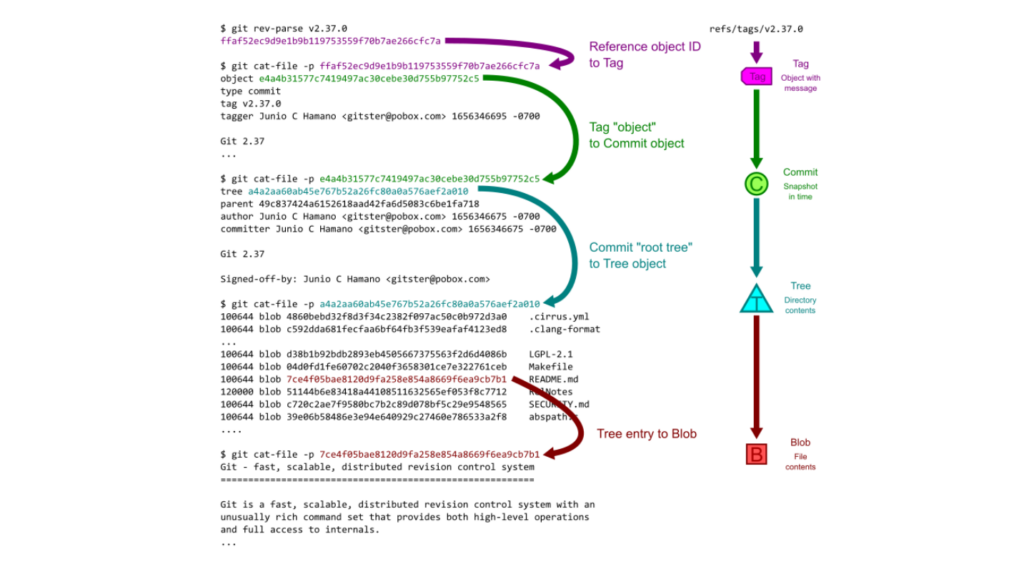
Img src: GitHub
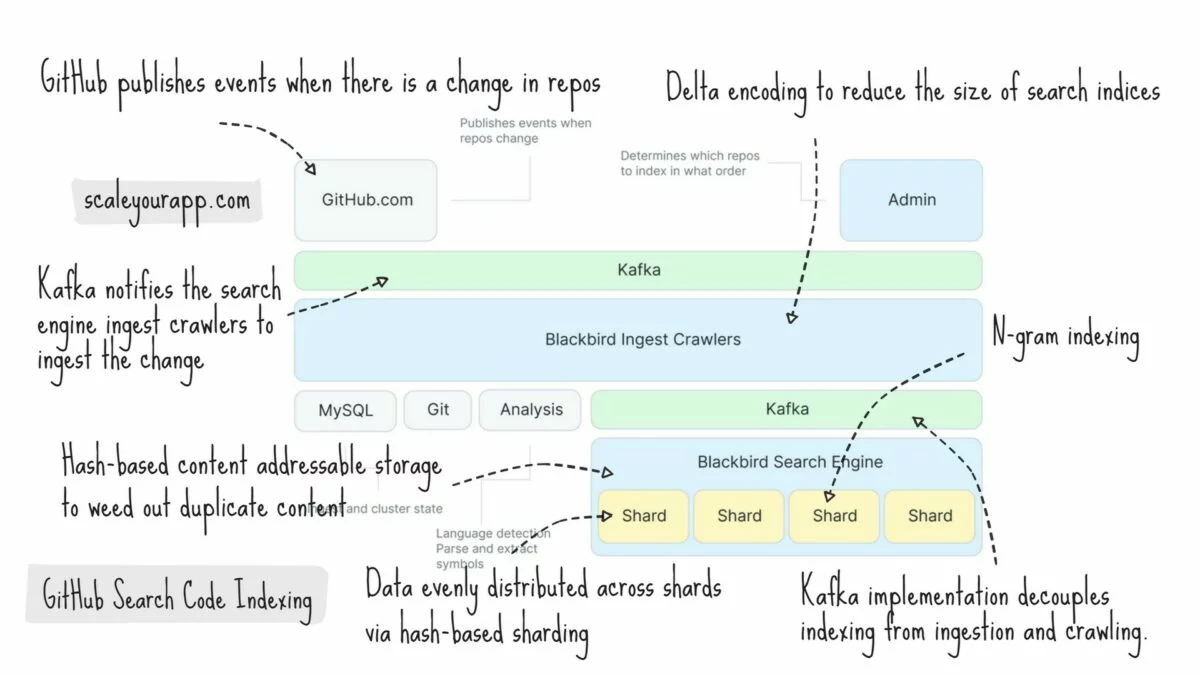
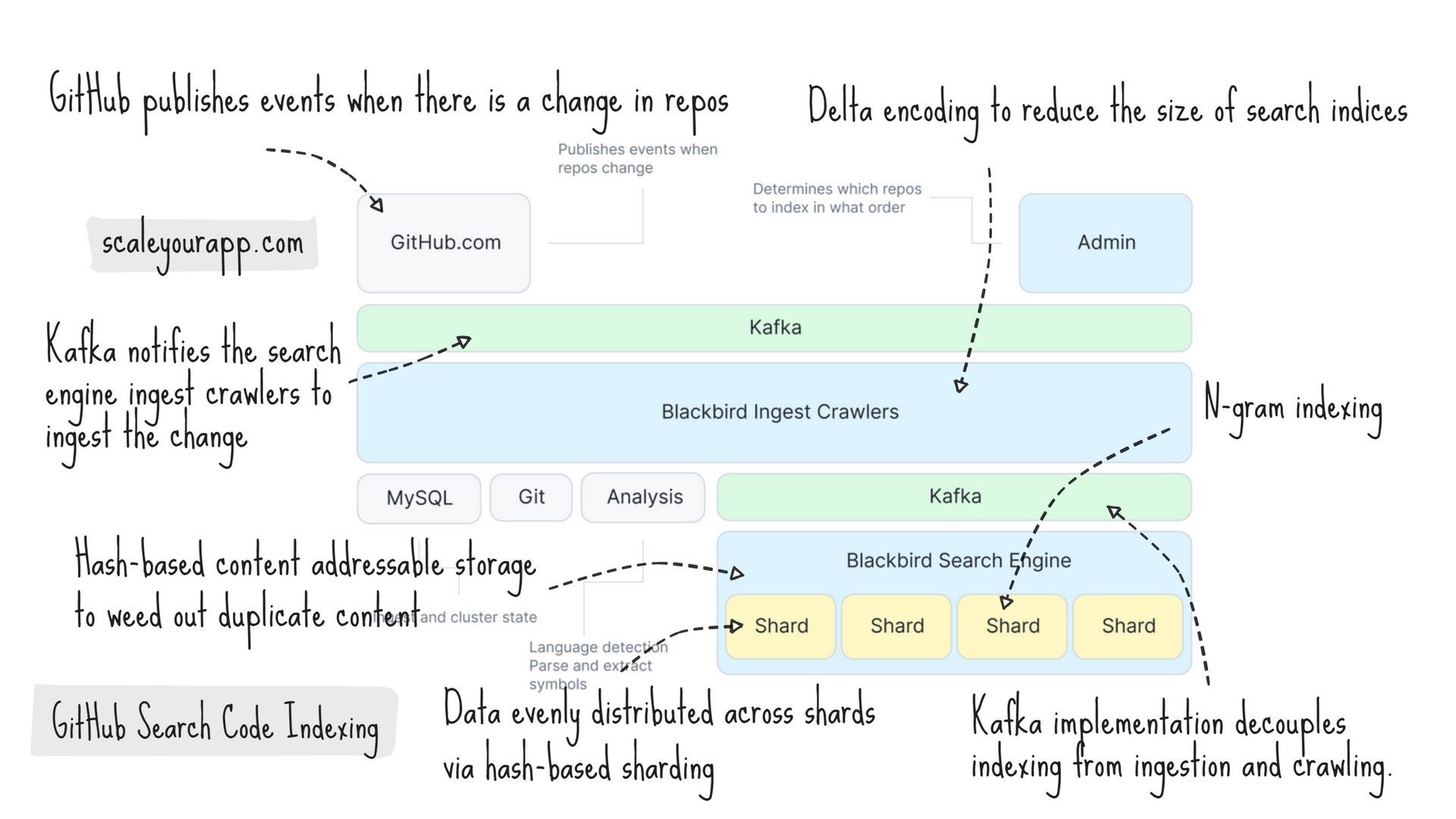
Ingesting & Indexing Code
Below is a high-level diagram of how code is ingested and indexed.
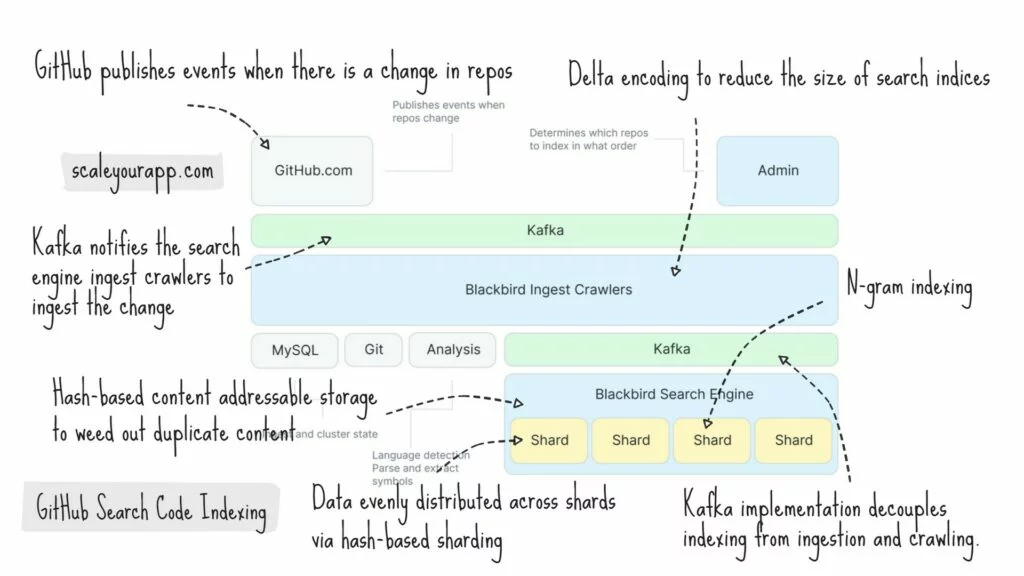
Img src: GitHub
GitHub publishes events when there is a change in repos. The event via Kafka notifies the search engine ingest crawlers to ingest the change. The crawlers extract symbols from code, create documents, and, via Kafka again, store documents in shards.
The system leverages delta encoding to reduce the size of search indices by storing only the changes in the code as opposed to the entire file. This speeds up the indexing and querying process, averting unnecessary computation of the complete file, in a system where the content is constantly changing.
The search engine optimizes the order in which the files are initially ingested to make the most out of delta encoding.
The indexing shards build n-gram indices with documents and run compaction to club smaller indices into larger ones for efficient querying before flushing the content to disk. The second Kafka implementation decouples indexing from ingestion and crawling.
The indexing pipeline has the capacity to publish around 120,000 documents per second and indexing 15.5 billion docs takes around 36 hours. However, the delta indexing reduces the number of documents to be crawled by over 50%, which brings down the indexing time to 18 hours.
Optimizing Ingest Order & Making the Most of Delta Encoding
To determine the optimal ingest order and to be able to tell how similar one repository is to another in terms of its content, they invented a new probabilistic data structure called geometric filter.
Probabilistic data structures leverage randomization and approximation to store and query data efficiently with some possibility of error. They are useful in memory-bound cases where some level of accuracy can be traded off for reduced memory and improved performance. Some examples are bloom filter, count-min sketch, hyperlog, and skip lists.
Geometric filter constructs a graph where vertices are repositories and edges are weighted with the similarity metric. A minimum spanning tree of this graph is calculated and a level order traversal is performed to get an ingest order to make the best use of delta encoding.
System Design Learnings In this Case Study
Storing duplicate data efficiently with content addressable storage
Hash-based content addressable storage is a great way to churn out duplicate data when storing massive volumes of data.
Object storage like AWS S3, Google Cloud Storage, Azure Blob Storage, etc., are associated with storing hash-based data since they store data in a key-value pair, with the key being a unique hash of the content of the data. With this approach, the duplicate copies will create the same hash; thus, only the original copy needs to be stored in the database with duplicate instances pointing to the same storage location.
In case we intend to use a different database that does not create unique hashes of the content, we can create a hash in our code at the application level before storing it in the database.
Hash-based sharding to distribute data across shards
There are multiple ways to shard data across nodes in a cluster, such as range-based sharding, key-based sharding, round-robin sharding, directory-based sharding, random sharding, hash-based sharding, geographic region-based sharding and so on.
GitHub evenly shards data by Git blob object ID, which is a customized hash-based sharding. Blob object IDs are unique hashes generated from the content of the object.
Hash-based sharding ensures the data is distributed amongst shards uniformly based on a hash function. This facilitates efficient data access and retrieval. Queries are uniformly spread across the cluster nodes as opposed to converging on a few hot nodes.
If new nodes are added or removed from the cluster, hashing is adjusted, ensuring minimal data redistribution across shards. Slack uses the consistent hashing technique to ensure it minimizes data rebalancing on the addition and removal of nodes in the cluster. I have done a case study on it here. Check it out here.
Trees for storing hierarchical data
Tree data structure fits best for storing hierarchical data. Git leverages it to store the repo file hierarchy. Trees naturally model the parent-child relationships and make it easy to navigate, search and sort the hierarchical data with minimal latency.
File systems with directory structures, database indexes (B-tree, AVL tree), compression algorithms (Huffman tree), leverage trees for efficiency.
Object store fits best for storing unstructured data
There are primarily three types of cloud storage: file, block and object. Object storage fits best for storing unstructured data with a unique key.
Besides code, GitHub stores images, documentation, PDFs and such. This kind of data is unstructured. Hence, the object store fits best for this use case.
With object stores, data can be easily accessed over HTTP and shared via content delivery networks—streaming services leverage object storage to store heterogeneous data like video, audio files, images, etc.
Using an event queue/message broker to decouple system modules
GitHub leverages Kafka to decouple crawling and indexing modules. Using a message broker/event queue is a standard architectural approach to decouple microservices.
This facilitates a loosely coupled and flexible system design. The event queue acts as an adapter between the system modules without requiring them to be ready to process events simultaneously, facilitating non-blocking asynchronous communication.
I explore real-world architectures to understand the architectural and system design concepts web-scale companies leverage to scale, stay available, fault-tolerant and keep the latency low.
Here is the former case study: Exploring Slack’s real-time messaging architecture. Check it out.
If you wish to take a deep dive into the fundamentals of designing a large-scale service, I have discussed these concepts and more in my Zero to Mastering Software Architecture learning path comprising three courses I have authored intending to educate you, step by step, on the domain of software architecture, cloud infrastructure and distributed system design.
This learning path offers you a structured learning experience, taking you right from having no knowledge on the domain to making you a pro in designing web-scale distributed systems like YouTube, Netflix, ESPN and the like. Check it out.
Information source: GitHub Engineering
I am Shivang. Here is my X and LinkedIn profile. Feel free to send me a message. If you found the content helpful, consider sharing it with your network for more reach.
I’ll see you in the next post. Until then, Cheers!


Follow Me On Social Media