
{kind=link}
The network file system is a distributed file system protocol. It’s an open protocol that specifies message formats on how a client and a server should communicate in a distributed environment.
NFS being an open protocol enables third parties to write their own implementations of it with multiple vendors today offering their own versions of the network file system.
Before deep diving into NFS, I’ll provide a quick insight into the distributed file system since to understand NFS, we need to understand the distributed file system.
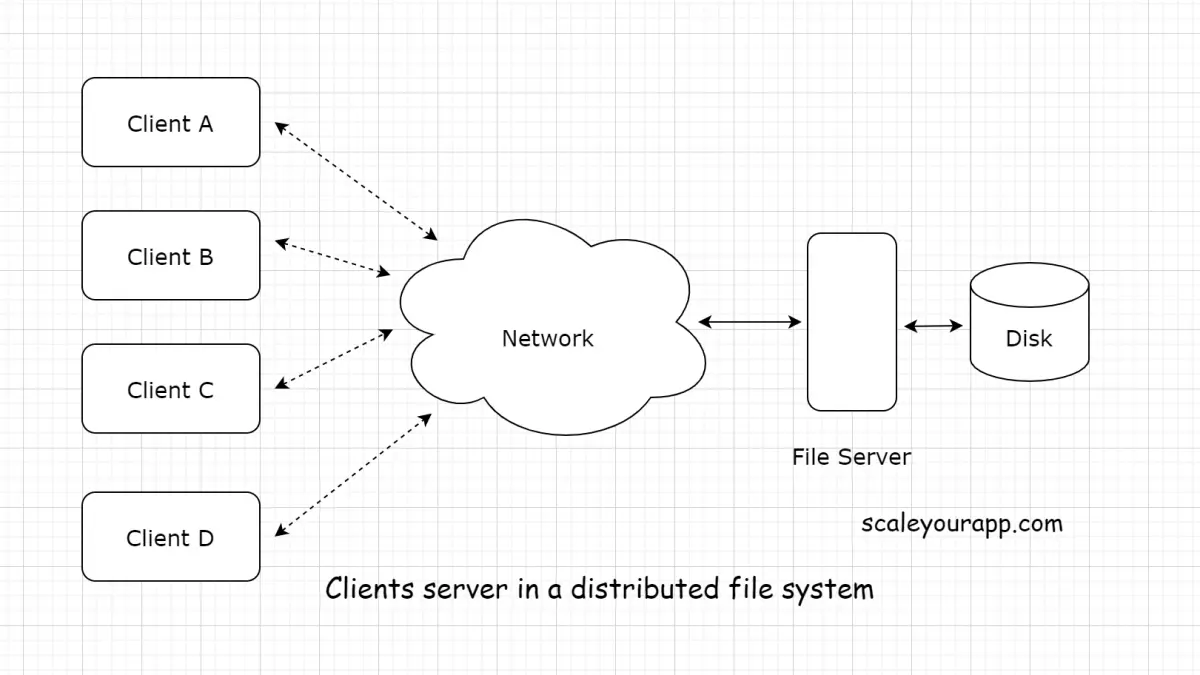
Distributed file system
In a distributed file system, one or a few servers serve multiple clients. The server stores the data on the disk and the clients fetch the data from the server via the network.
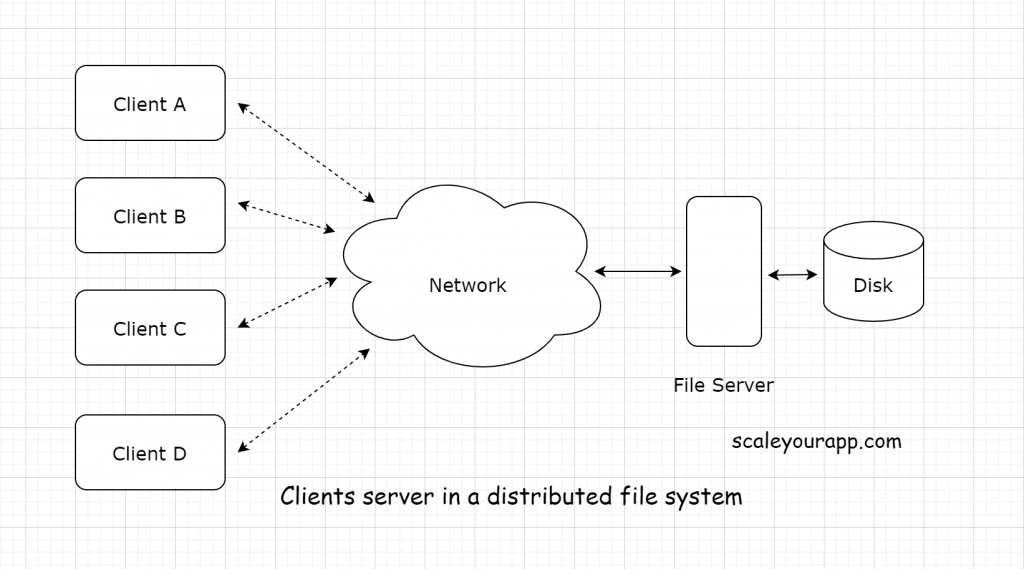
With the help of a distributed file system, the clients can access the data residing on the server disks remotely as if the data lived in their local disks.
Why not store the data in the local disks of clients that would avert the network latency during the data fetch operations? Why keep it in the server centrally?
Saving data in a single or a few servers enables it to stay consistent. Imagine clients holding their respective data and performing regular updates to it locally. This would make data largely inconsistent across the network. Every client will hold its own version of the data, which is what we definitely don’t want.
When the data is consistent, it can be easily shared across clients without any fuss. Also, it can be backed up easily when residing in a few servers as opposed to a significantly larger number of clients. Additionally, holding the data centrally in a server makes it more secure.
In a typical client-server distributed file system, both the client and the server contain the file system. The file system on both ends in a distributed file system enables the client to read and update the data on the server as if being done on the local client disk.
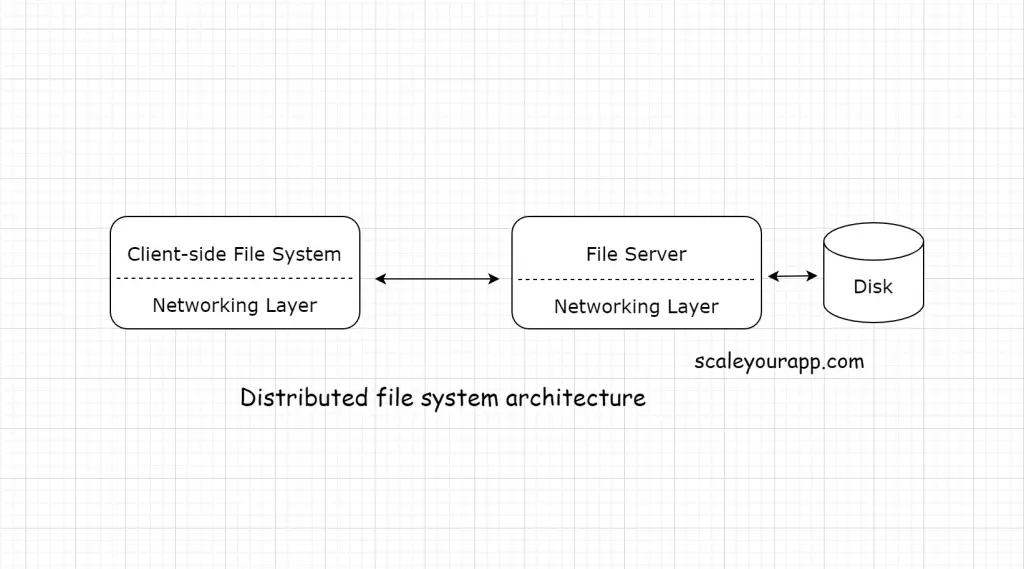
How?
Here is how it works: the client fires system calls, such as open, close, read, update a file, etc., to the client-side file system. In turn, the client-side file system sends a request to the server-side file system.
When the client wants to read a file, the client-side file system issues a read request to the server. The server reads the data from the disk and returns the response to the client-side file system.
The client-side file system holds the response data in its buffer/local memory and provides the data to the client.
Now, if the client would want the same data within a stipulated time, the client file system will serve the data from the buffer cutting down the network traffic significantly.
This was an overview of the distributed file system, now, let’s understand the network file system.
Network file system
The primary focus in the development of NFS was quick and simple server crash recovery. As a result, the communication protocol between the client and server was designed stateless just like in a REST API communication.
In NFS, the server holds no information of the client at any point. Every time the client sends a request, the request contains all the information that the server needs to return the requested data. There is no shared state between the client and the server. This makes server crash recovery uncomplicated.
How, exactly?
Imagine a scenario where the client and the server share some state during a conversation. The client sends a request to the server for a certain file with an id X. The server processes it, returns the response and crashes.
The file id that the server held is lost. And then it comes back up again before the client issues a second request for another file, related to the initial file with id X, without giving the file id X, hoping the server would understand the context.
But since the server crashed, it lost the original file id and is confused now.
Here is another scenario: since a file in a server is accessed and updated by multiple clients, a client has to send separate open and close file system call requests to the server to inform it that the client is done editing the file and can be accessed by other clients in the network.
Now, if a client crashes during the file edit, the server doesn’t know what to do. Does it keep the file locked, wait for the client to come back online, or allow other clients to update it?
The best bet in this scenario is to not carry over the state in different request-response cycles. In a stateless protocol, the server would hold no information on the client. Every request response is treated as a new one.
So, on the client crash, the client can retry the request anew when it comes back up again. While the original request would be discarded by the server.
This is why stateless request-response cycles are implemented in a network file system. Every client request contains all the information that the server needs to provide the response, making things less complicated.
Now, let’s understand how is this stateless protocol implemented.
If you wish to master the fundamentals of software/web architecture, application deployment infrastructure along with distributed systems design starting right from the bare bones, check out the Zero to Software Architect learning track that I’ve authored. This unique learning track offers you a structured learning experience making you a pro in designing web-scale distributed systems like YouTube, Netflix, ESPN and the like.
NFS Network file system design – Stateless protocol
A key element in understanding network file system design is a file handle. A file handle uniquely identifies the file or the directory a particular operation will run on. This makes it an essential component of a stateless NFS client request.
A file handle, in turn, consists of three components: a volume identifier, an inode number, and a generation number.
The volume identifier identifies the volume in the disk. The inode number specifies what file within that particular volume is being accessed. Every file has a unique inode number. An inode number holds a generation number. Whenever an inode number is reused for an operation, the generation number is incremented to mark the new operation distinctly.
Idempotent requests
The requests in the NFS are idempotent. This means the effect of multiple duplicate requests will be the same as the original request. The system is designed in a way that duplicated requests don’t end up leaving it unstable.
This enables the clients to retry requests multiple times if they don’t receive the response within a stipulated time.
And there can be multiple reasons behind clients not receiving a response: server crash, network dropping the request and so on. In these scenarios, the network file system enables the client to retry the request.
Client-side caching
The network file system focuses on client-side caching to cut down all unnecessary network calls to improve its performance.
Clients in an NFS cache the response from the server to avoid re-sending the requests for the data they have already requested earlier. Also, the writes in the file are made on the client side and the updated file is then sent to the server as opposed to being edited directly on the server. This improves the write performance of the network since the server is free to deal with other requests while the clients perform the file writes locally.
Though client-side caching improves the network performance significantly, it has a side-effect: a cache consistency problem.
Cache inconsistency problem in the network file system
Imagine a scenario where a client, let’s call it A, reads a file X in the network and caches it in its local memory. Another client B performs an update to that file X on the server and caches it. Here we have two versions of the same file: one which the client A holds and another on the server and with client B.
And then there comes another client C, that wants to access the same file X from the server. I believe you can sense the storm brewing.
Now client C pulls the file, performs some writes, caches it and updates it on the server. At this point, clients A, B and C all have different versions of the same file. This is the cache inconsistency problem.
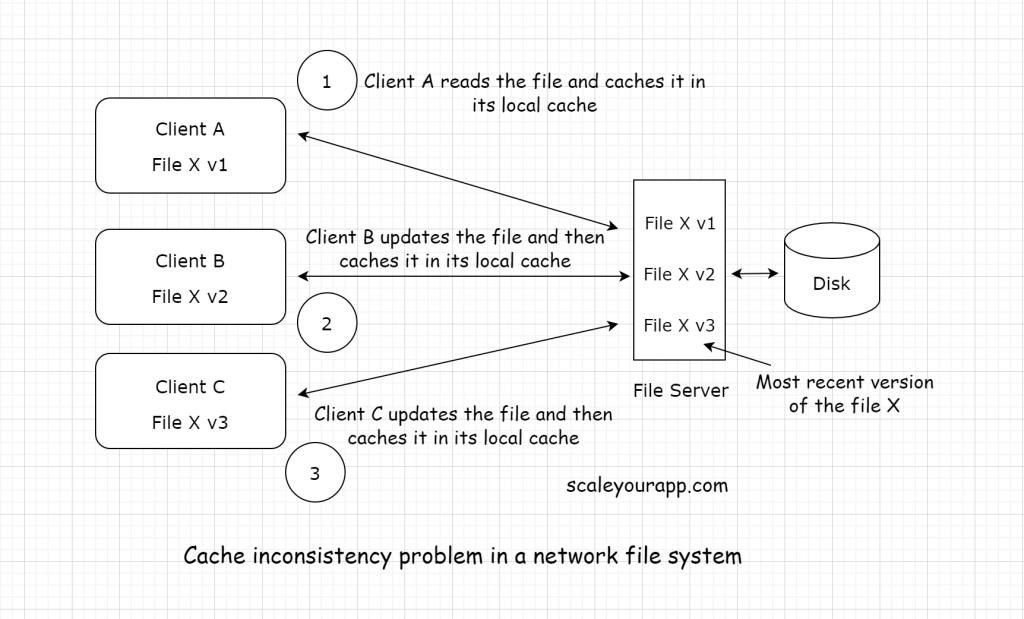
Dealing with cache inconsistency problem
To deal with the cache inconsistency problem, the clients need to verify if the data they have cached is consistent with the data on the server.
If not, the cache needs to be invalidated and the updated data should be fetched again from the server.
For this, the client has to check with the server every time it intends to use data stored in its local cache. However, this would defeat the whole purpose of local caching since the client has to send a request to the server every time it wants to use its cache.
However, if the client checks with the server for data consistency at stipulated intervals continually, it would avert the need to verify with the server every time a client intends to use data stored in its local cache. Even this technique will exert some additional load on the network and also does not eradicate the cache inconsistency issue by cent percent.
Thus client-side caching is more of a design tradeoff and largely depends on the frequency of writes the data has.
Synchronous operations
All the write operations abiding by the NFS protocol are synchronous. After the client completes the data modification, it can assume that the data has been written to stable storage.
Stable storage means storage that is resilient to software crashes or power failure. This is generally achieved by replicating the disks or using RAID (Redundant Array of Independent Disks).
Performance in the network file system
Let’s discuss the factors affecting the performance of a network file system:
Caching
We’ve discussed caching above in the article, how NFS leverages the client and the server-side caching to cut down the server and disk load, respectively.
Before sending a write request to the server, a client performs multiple edits/writes locally, storing them in its local cache and then sends a final write request to the server cutting down the network load starkly.
We can also augment the caching capacity on both the client and the server to further improve the performance of the network.
Augmented caching on the server will avert the need to send I/O requests to the disk often.
Proxy caching
In a network file system, a proxy server can be set up in front of the origin server to intercept all the requests from the clients.
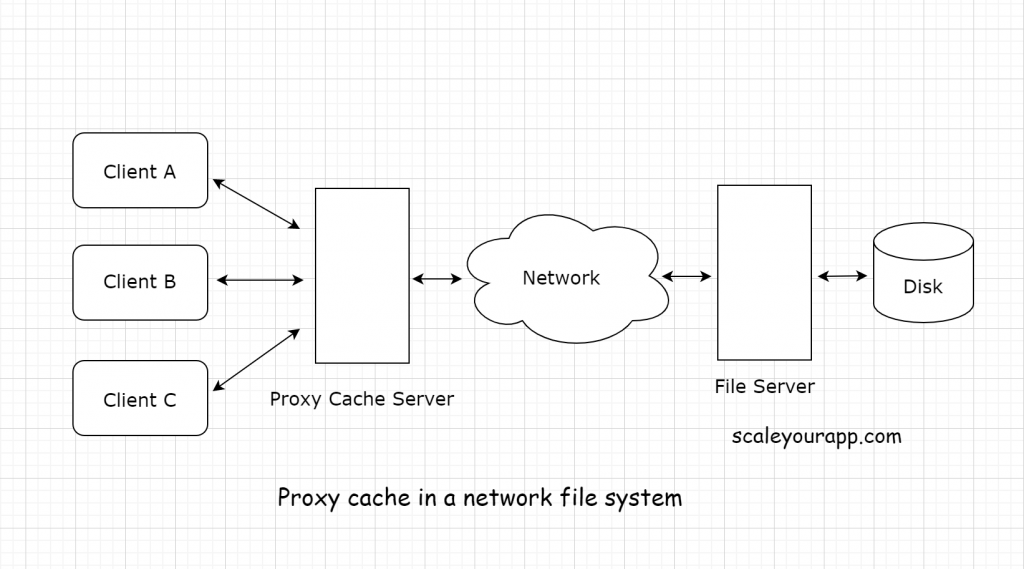
Now the clients, instead of hitting the origin server, will hit the proxy server. The proxy server, in turn, caches the frequently and commonly accessed data from the clients to respond to their requests averting the load on the origin server.
CPU
The compute power of both the client and the server in the network file system directly affects the rate of request-response processing/throughput in the network. With augmented CPU power, the server can process a larger number of client requests in a stipulated time.
Network configuration and bandwidth
A poorly configured network could reduce the throughput significantly. The network should be tolerant of lost packets, server time-outs, etc.
If you found the content helpful, check out the Zero to Software Architect learning track, a series of three courses I have written intending to educate you, step by step, on the domain of software architecture and distributed system design. The learning track takes you right from having no knowledge in it to making you a pro in designing large-scale distributed systems like YouTube, Netflix, Hotstar, and more.
This pretty much sums up network file systems. If you found the content helpful, consider sharing it with your network for more reach. I am Shivang, you can read about me here.
References:
Sun microsystems network file system
NFS Illustrated by Brent Callaghan



Follow Me On Social Media