
{kind=link}
Twitch engineering developed a scalable, HA live streaming solution to enable broadcasters on their platform live stream their gameplay with minimum latency.
The live streaming solution (developed by Twitch) is also made available as a Service to the world through AWS IVS (Interactive Video Streaming) that would enable other businesses leveraging AWS to integrate interactive streaming services with their apps or websites.
AWS IVS is a fully managed live streaming solution that takes care of ingestion, transcoding, packaging, and delivering live content to the end viewers.

Key points from the Twitch infrastructure:
They have hundreds of thousands of concurrent live broadcasters on their platform. The streams have five different quality levels to adapt to the viewers’ network conditions.
The stream also has a buffer of a few seconds to download the video on the viewer’s device ahead of time to make the stream run smoothly.
Over the years, Twitch has managed to reduce the streaming latency from 15 to 3 seconds. Under best network conditions, for instance, in Korea, the latency is reduced to 1.5 seconds.
Why is latency important in live steams? Can’t the video be buffered and played like a regular video?
The lesser the time it takes from when a streamer waves at the camera to when their viewers see that wave on the screen, the better is the user experience on the platform. Reduced latency enables a more real-time interaction between the streamers and the viewers.
When the streamer starts their stream, their video is transcoded by Twitch servers. Transcoding (system written in C/C++ and Go) converts the stream into multiple formats to be played on the viewer’s device under different network conditions. The transcoded formats are then distributed across the data centers and PoPs (Point of Presence) running on multiple geographic locations worldwide, ensuring proximity to the viewer’s location.
Transcoding is computationally expensive. Initially, Twitch transcoded only two to three percent of the channels. But with the hardware-based transcoder built in-house, they have brought down the costs significantly, allowing them to scale and transcode every video upload to their servers.
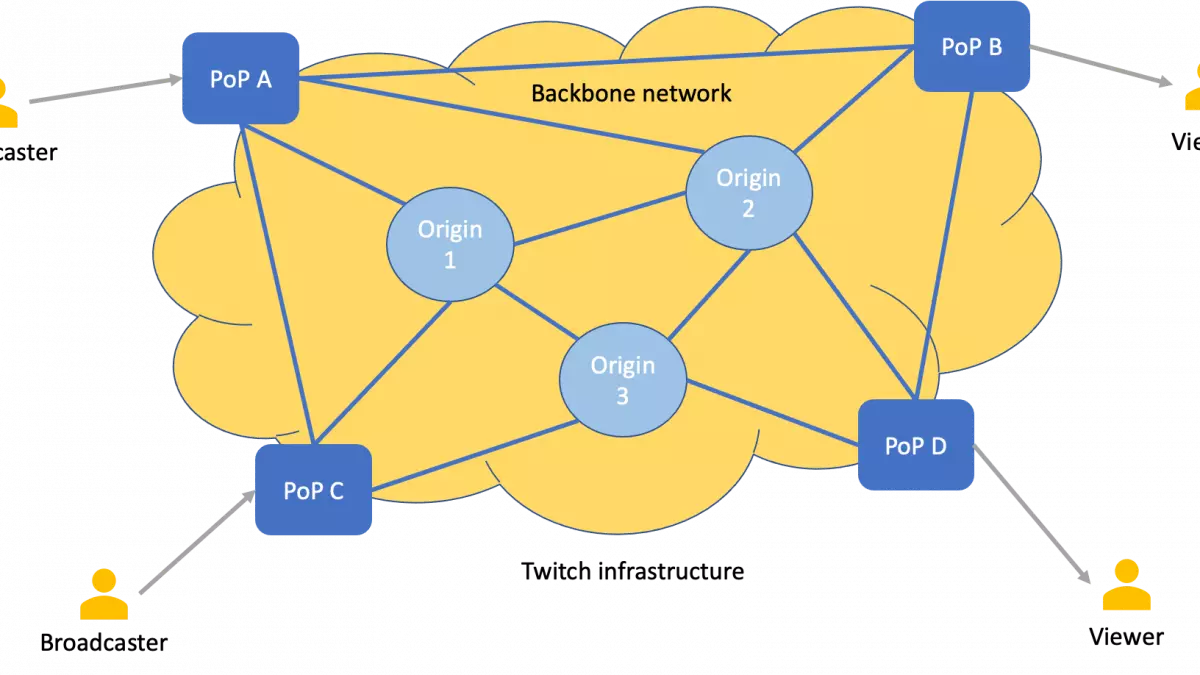
Speaking of the physical infrastructure, to ensure smooth streaming, they’ve partnered up with the local ISPs and have several PoPs (Point of Presence) powered by the backbone network that connects them with the data centers.
If you wish to understand PoPs, and other cloud fundamentals in-depth, including how cloud infrastructure deploys and scales our apps globally and more, check out my platform-agnostic Cloud Computing 101 course.
Viewers from around the world download the videos from PoPs. The intelligent network ensures the streamer’s channels are replicated across Twitch’s network in proximity to their viewers. Replicating all the channels across their network would be overkill.
Replication of data is done based on a metric called reach, which determines the percentage of people with a certain quality of internet access and the quality of streaming they would get from the platform. The approach is not too precise but gives a high-level idea that helps Twitch design its infrastructure to optimize the quality of service and deployment costs.
The live video streams received at the PoPs are moved to the origin data centers for processing and distribution across the Twitch network. Origin data centers take care of computation heavy processes such as video transcoding.
Originally, Twitch started with a single origin data center where it processed the live video streams. The PoPs ran HAProxy and routed the streams to the origin data center. As the platform gained traction and the number of data centers increased it brought along a few challenges with the HAProxy approach.
The PoPs, due to HAProxy configuration, statically sent live video streams to only one of the origin data centers. This led to the inefficient utilization of the infrastructure resources.
It got difficult to handle the unexpected traffic surge during key online events.
PoPs couldn’t detect overloaded or faulty origin data centers and still sent traffic their way as opposed to routing it to other data centers.
In order to deal with these challenges, they retired HAProxy and developed Intelligest—an ingest routing system to intelligently distribute live video traffic from the PoPs to the origins.
The Intelligest architecture consists of two components: Intelligest media proxy running in each PoP and Intelligest Routing Service (IRS) running in AWS.
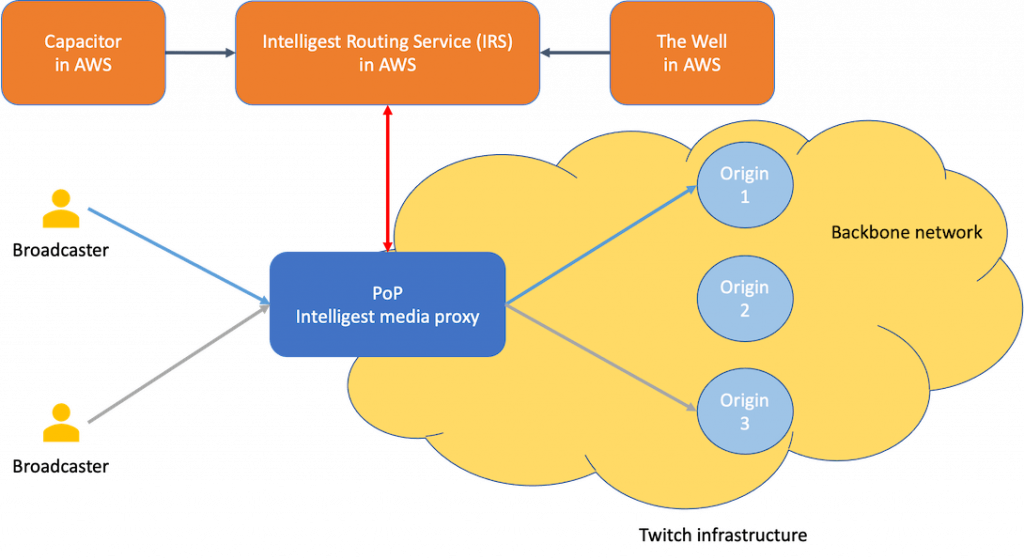
The media proxy, with the help of IRS, determines the right origin data center to send the traffic to, overcoming the challenges faced with HAProxy.
IRS has further two sub-services, the Capacitor and the Well. The Capacitor monitors the compute resources available in every origin data center and the Well monitors the backbone network bandwidth availability. With the help of these, IRS can determine in real-time the infrastructure capacity. This has enabled Twitch achieve high availability in their infrastructure.
If you’ve found the content interesting, consider subscribing to my newsletter to get the latest content delivered right to your inbox.
Information source: Twitch engineering

Distributed Systems
For a complete list of similar articles on distributed systems and real-world architectures, here you go


Follow Me On Social Media