
{kind=link}
Parallel Processing: How Modern Cloud Servers Leverage Different System Architectures to Optimize Parallel Compute
Modern cloud servers leverage several system architectures to process data parallelly, which increases throughput, minimizes latency and optimizes resource consumption. In this article, I’ll discuss those system architectures and we’ll get an insight into how distributed services leverage these architectures to scale.
With that being said. Let’s jump right in.
Shared Memory Architecture
In shared memory architecture, all the processors in an instance share a common memory which is RAM. In this architecture, all processors read and write to the same memory location. This facilitates efficient communication and data sharing between them, resulting in performant task execution.
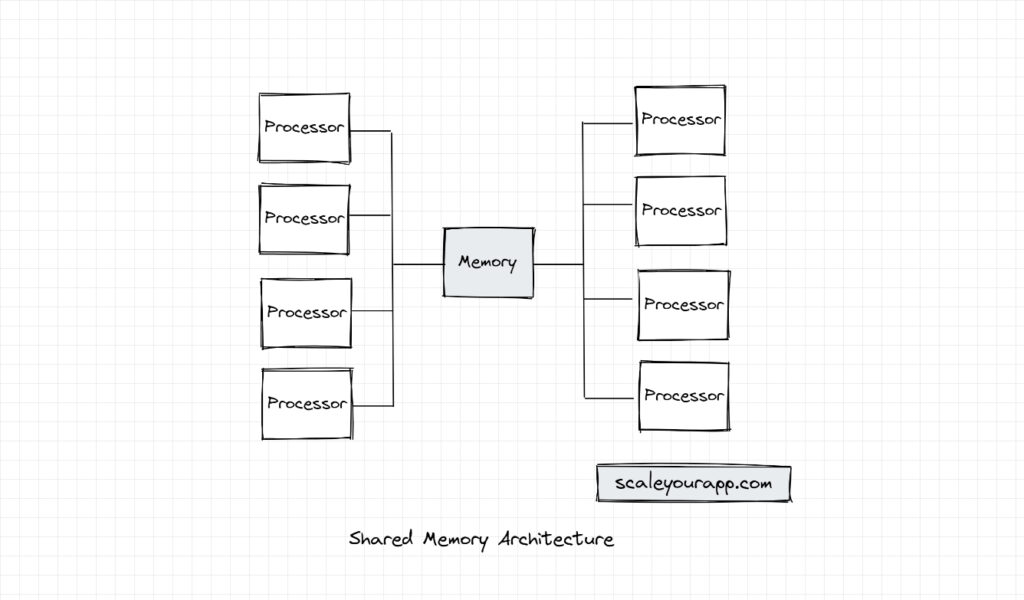
To facilitate efficient data sharing between the processors, shared memory systems implement effective synchronization strategies to avoid data inconsistency and race condition issues. Most shared memory systems work with an optimum number of processors in a cloud instance since sharing memory between a large number of processors could cause contention. I’ve discussed contention in shared memory architecture further down the article when I discuss the types of shared-memory architectures.
Though a number of processors in a node working in conjunction could cause contention, this architecture is performant in contrast to shared disk and shared-nothing architectures, since the data isn’t explicitly needed to be passed over a network, which would add additional latency to the service. All the processors, execute tasks with the help of the main memory of the node.
In shared memory architecture, the data is processed and cached in the main memory as opposed to being fetched and written to a disk (which is slow). This makes it fitting for use cases where data needs to be processed and fetched as quickly as possible, for instance in real-time low-latency trading systems, in-memory databases, containerized deployments, etc.
In-memory databases leverage shared memory to store data in a format that facilitates quick reads and writes. This cuts down the query response latency starkly in comparison to disk-based databases.
Shared Memory Architecture In Modern Cloud Instances
As discussed above, in high-performance compute cloud instances, the shared memory architecture helps improve the performance starkly, cutting down the task execution time and subsequently reducing the compute costs.
High-performance hardware has a configurable number of cores that communicate via a shared memory via a high-speed memory bus. The workloads that run on these instances leverage parallelization algorithms to optimize the task execution. The size of the shared memory in these instances is mostly determined by the number of cores leveraged and the workload requirements.
For the record: node, instance and server mean the same thing and are used interchangeably. Workload in cloud speak is the application deployed on a single node or a cluster of nodes.
In microservices and containerized deployments, shared memory helps in efficient accelerated inter-process communication, in addition to helping the VMs share physical resources.
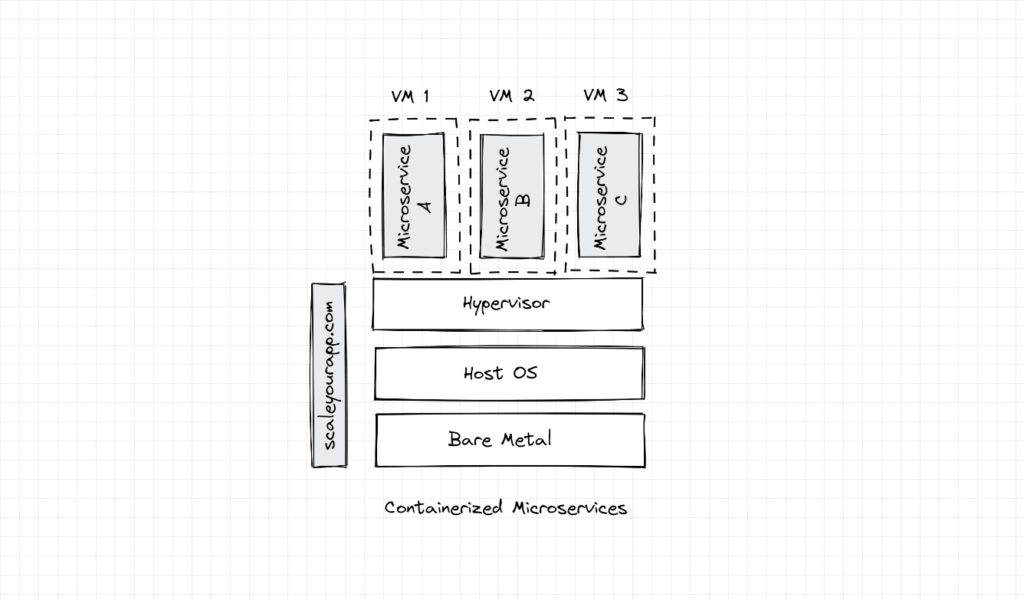
As opposed to dedicating memory to every VM, with shared memory architecture, resources can be pooled and shared amongst the VMs, facilitating optimum hardware utilization, in addition to offering memory flexibility in case of increased workload memory requirements, and caching data when the VMs have similar memory access patterns.
If you wish to understand the underlying infrastructure on which distributed services are deployed, how services are deployed in different cloud regions and availability zones globally, how multiple server nodes in a cluster communicate with each other, how microservices scale in containers, code deployment workflow and much more, check out my cloud computing fundamentals course here.
This course is a part of the Zero to Software Architecture Proficiency learning path, I authored to help you master the fundamentals of software architecture, cloud infrastructure and distributed system design, starting right from zero.
Shared-memory architectures are of a couple of types: Uniform Memory Access (UMA) and Non-Uniform Memory Access (NUMA) architecture. I’ll discuss them after I discuss the shared disk and shared nothing architecture.
Shared Disk Architecture
In a shared disk architecture, all processors access the same disk but have dedicated memories, i.e., RAMs (Random Access Memories).
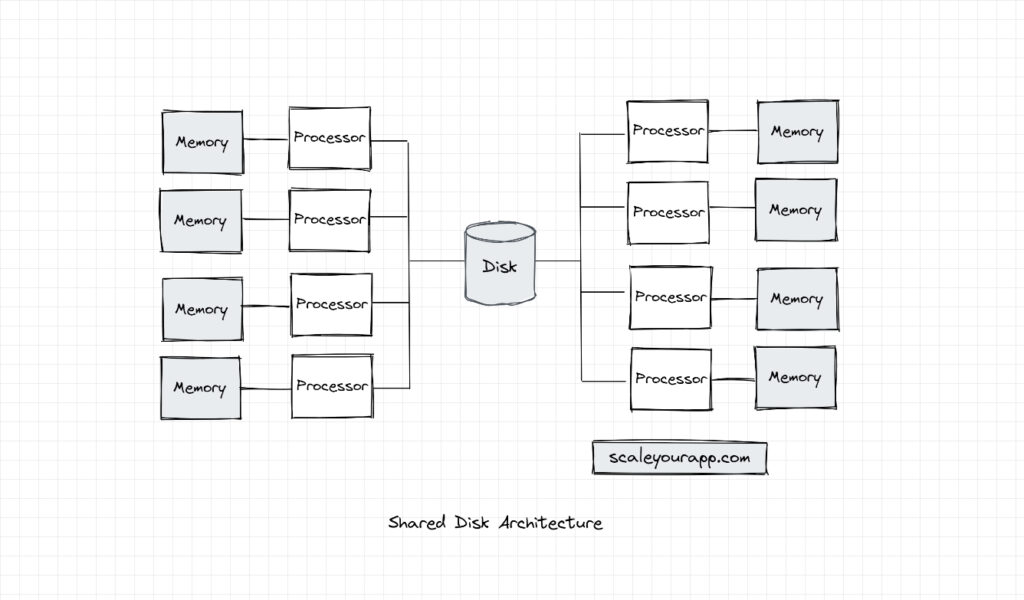
This architecture brings in a certain level of fault tolerance in the system. In case the memory of a certain processor fails, it doesn’t throw a wrench into the gears. Other processors have access to their memories and the disk. Also, the memory bus is less of a bottleneck in the system since every processor interacts with their dedicated memory. This allows a higher number of processors to be added to the system in contrast to shared memory architecture, where all the communication happens through a central memory bus which could be a bottleneck.
However, the disk in this architecture is still a single point of failure. If it fails, the task execution takes a halt.
In comparison to shared memory architecture, the shared disk architecture is a distributed architecture that facilitates communication across multiple nodes in a cluster as multiple nodes with processors access common cluster storage concurrently. The shared memory architecture, in contrast, suits effective communication between multiple processors sharing a common memory in a single node.
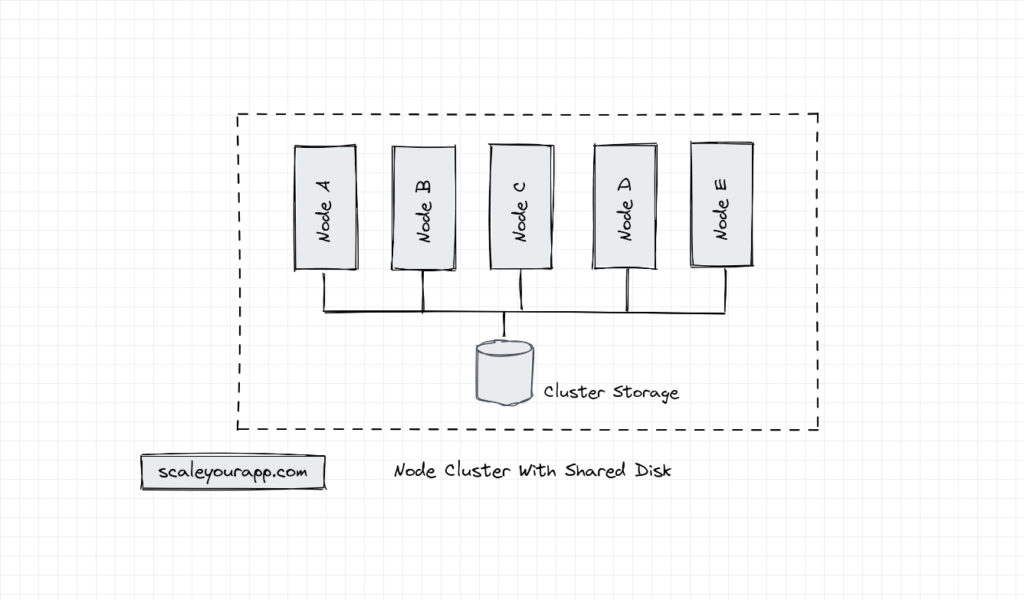
Some real-world use cases of shared disk architecture are database clustering, where multiple nodes in a database cluster access a common dataset; data warehousing, where multiple nodes in a cluster execute data processing tasks parallelly and CDNs, where multiple distributed edge servers access a common dataset.
Moving on to shared nothing architecture.
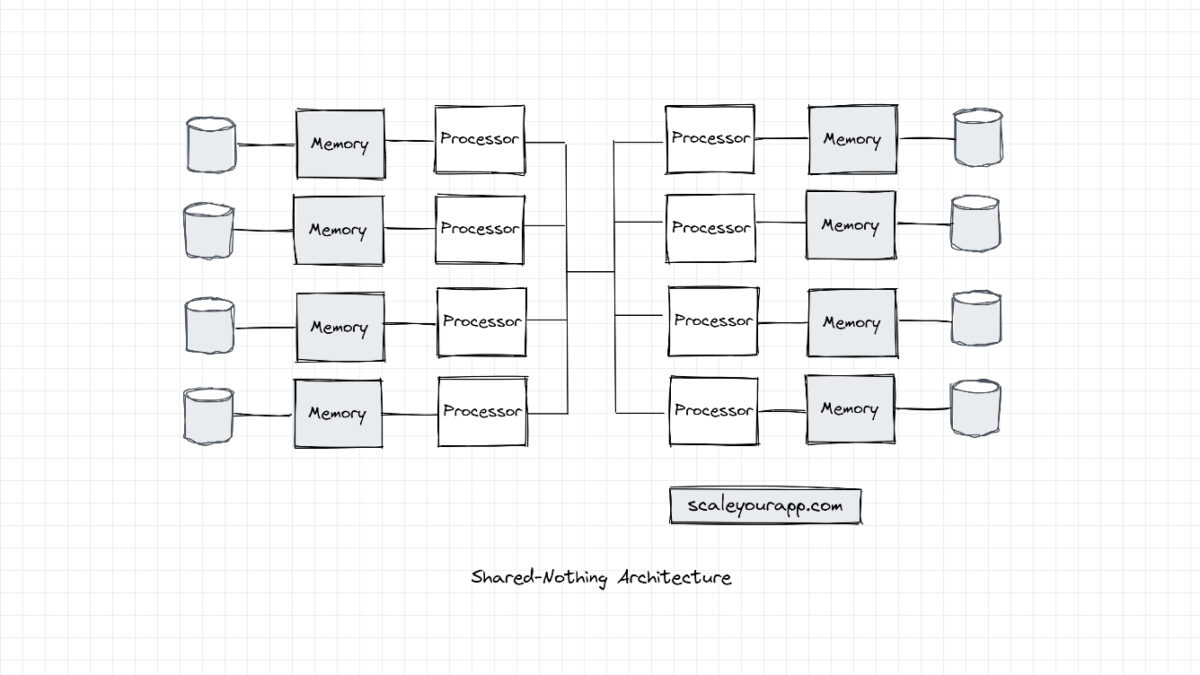
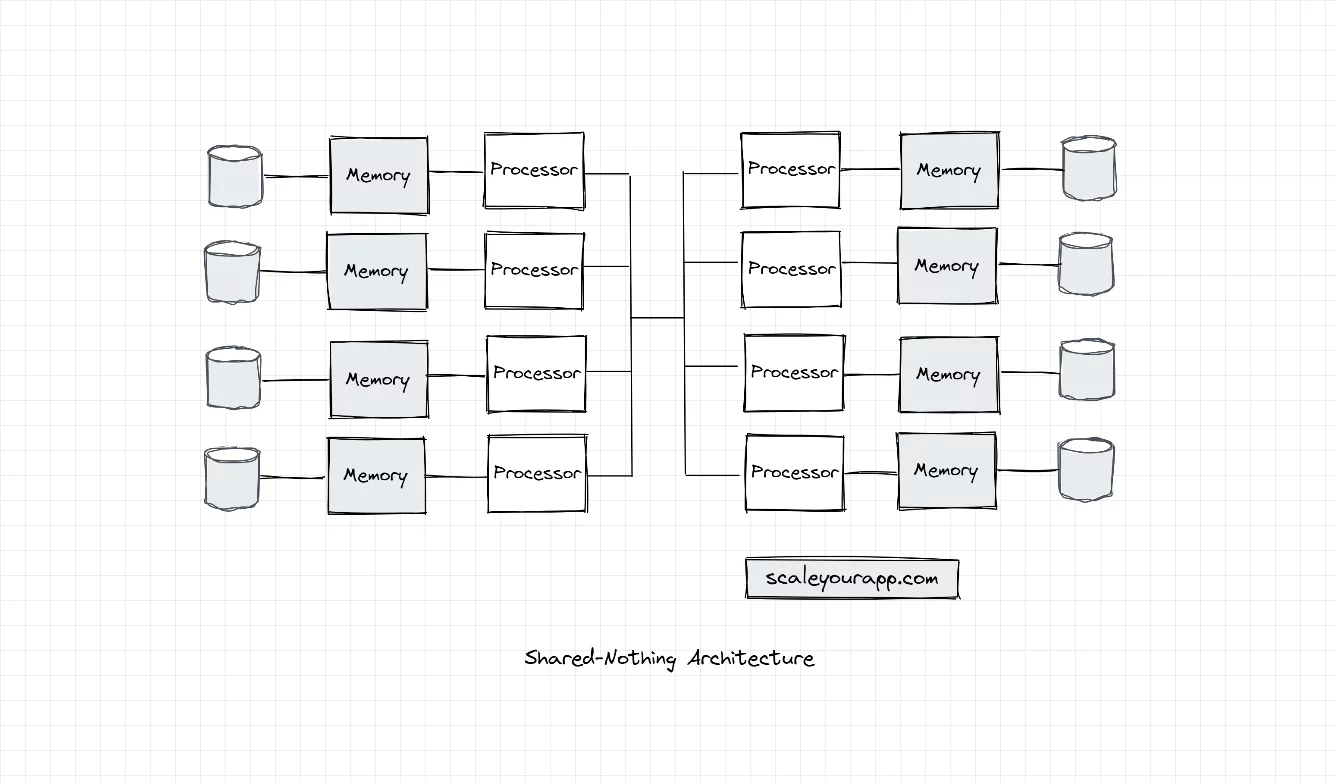
Shared Nothing Architecture
In shared-nothing architecture, as the name implies, the processors don’t share any memory or disk. The system is a cluster of independent nodes communicating over a performant network.
Each node in the system acts as an independent entity coordinated by a distributed node coordinator. An example of a distributed node coordinator, in large-scale services, is Zookeeper or it can be any specific software managing the nodes in the cluster, like a DBMS, like Vitess, Hadoop, etc.
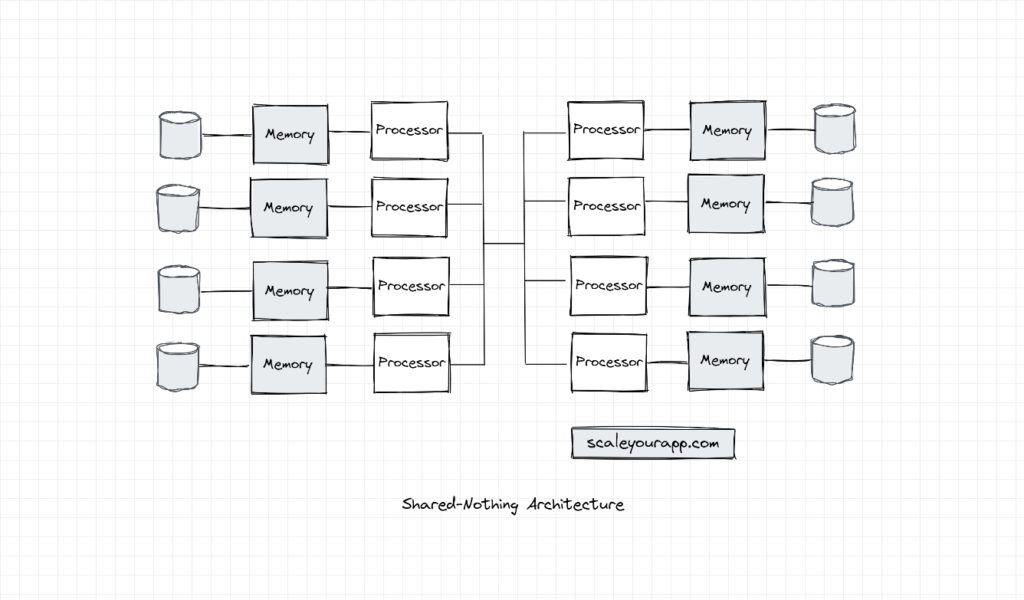
In this architecture, each node/processing unit processes and stores a portion of data in the cluster. They work in conjunction to execute a bigger task by splitting it into smaller tasks and executing it individually managed by a cluster coordinator, as I stated above.
The cluster coordinator handles failure cases, cluster load balancing, distributed deadlock scenarios, distributed transactions, communication across the cluster and so on.
The upside of shared-nothing architecture is it significantly increases the fault tolerance of the system, making it highly available. With it even if a few nodes go down in the cluster, the system as a whole is still up, unlike in the case of the shared disk or the shared memory architectures.
Distributed NoSQL databases leverage this architecture to scale horizontally; new nodes are added and removed from the cluster on the fly as per the requirements.
Shared-Nothing Architecture Real-World Use Cases
The shared-nothing architecture design approach helps distributed systems, specifically horizontally scalable NoSQL databases, scale by partitioning data across several nodes in the cluster, where each node manages its data independently, facilitating parallel processing and improved query performance.
Some examples of these databases are Google BigTable (I’ve discussed it here), Hadoop, ScyllaDB, CrateDB, etc.
ScyllaDB leverages shared-nothing architecture based on its underlying asynchronous programming Seastar framework. Each shard is allocated dedicated CPU, RAM, disk and other resources for efficient data processing, juicing out maximum efficiency from modern cloud hardware.
In my next post, part two of database architecture, I’ve discussed the internals of NoSQL databases. It’s a recommended read after you go through part one of database architecture.
Now, let’s get to the shared memory architecture types.
Shared Memory Architecture Types
Uniform Memory Access (UMA) Architecture
As we can infer from the name, in UMA architecture, all processors have equal access time to the shared memory. This fits best for applications that require balanced memory distribution across multiple processors.
Developers enabled by this architecture can design applications with the assumption that the processor memory access times are consistent and there is no need to implement complex memory management strategies.
Non-Uniform Memory Access (NUMA) Architecture
In NUMA architecture, processors have a dedicated local memory in addition to having access to the cluster’s shared main memory.
Again, we can infer from the name, here the memory access times of processors are non-uniform.
This architecture lies somewhere in the middle of shared memory and shared nothing architecture. Dedicated local memory for processors reflects the shared-nothing design, whereas the shared cluster memory reflects the shared memory design.
NUMA architecture enables the system to scale to quite a large number of processors. It stands out in scenarios where a large number of processors are involved. In UMA architecture, as the number of processors increases, it would become difficult to maintain uniform memory access without hurting performance.
Cloud instances with a high number of vCPUs leverage NUMA architecture to allocate virtual resources to optimize memory access. vCPUs or virtual CPUs enable virtual machines to share the processing power of a physical CPU to utilize hardware resources efficiently.
How Does the Shared Memory NUMA Architecture Compare to Shared-Nothing Architecture From a System Scalability Standpoint?
We’ve learned that the shared-nothing architecture helps us scale by enabling the nodes to process data or run compute independently. New nodes can be added to the clusters on the fly to scale as and when required. The NUMA shared memory architecture enables efficient task execution by having more processors in the system. How do both architectures compare from a system scalability standpoint?
NUMA architecture primarily helps with vertical scaling by adding more processors to a single node, augmenting its power. The shared memory architecture facilitates efficient data sharing and communication between threads and processes on the same machine with efficient memory algorithms and affinity policies. I’ll discuss affinity policies in another post.
In contrast, the shared-nothing architecture focuses on horizontal scaling by adding more nodes to the cluster for independent parallel processing. However, in this scenario, the communication between the nodes in the cluster adds a bit of latency.
Both architectures have trade-offs and it depends on the use case requirements, data access patterns, degree of parallelism required in the workload, etc., to pick the fitting one or leverage a hybrid of the two.
How Do I Know What Underlying Architecture a Certain Cloud Instance Has?
Cloud providers may not explicitly state the underlying hardware architecture of the instances they provide. Cloud instances are rather grouped based on the workload use case. However, if you look at the instance specifications, they may hint at the underlying architecture.
For instance, terms like memory-optimized, compute-optimized, storage-optimized give us an idea of the instance’s focus. An instance built for ultra-low latency high-performance compute may have a shared-memory NUMA architecture with processors with multiple cores, multithreading and efficient context-switching support. The cache would be bigger to ensure quick access to frequently accessed data.
Instances built for storing data sets in memory (memory-optimized instances) for quick processing will again leverage the shared memory architecture. The RAM capacity will be substantial and the underlying architecture will be designed to support data-intensive, high in-memory bandwidth operations.
In storage-optimized instances, the disk will be of high capacity. The hardware would be optimized for high data throughput, minimizing data transfer bottlenecks.
So, this is how the underlying architectures of cloud instances differ based on the use cases they support. Further, going through the specifications in detail will give an insight into the specifics of their hardware.
In addition, when picking the right cloud instance for our use case, it’s a good idea to perform benchmarking tests on different instance types to gauge their performance characteristics.
If you found the content helpful, I run a newsletter called Backend Insights, where I actively publish exclusive posts in the backend engineering space encompassing topics like distributed systems, cloud, application development, shiny new products, tech trends, learning resources, and essentially everything that is part of the backend engineering realm.
Being a part of this newsletter, you’ll stay on top of the developments that happen in this space on an ongoing basis in addition to becoming a more informed backend engineer. Do check it out.
Folks, this is pretty much it. If you found the content helpful, consider sharing it with your network for more reach. Check out part two of database architecture where I discuss NoSQL databases.
I am Shivang. You can read about me here. I’ll see you in the next post. Until then, Cheers!


Follow Me On Social Media