
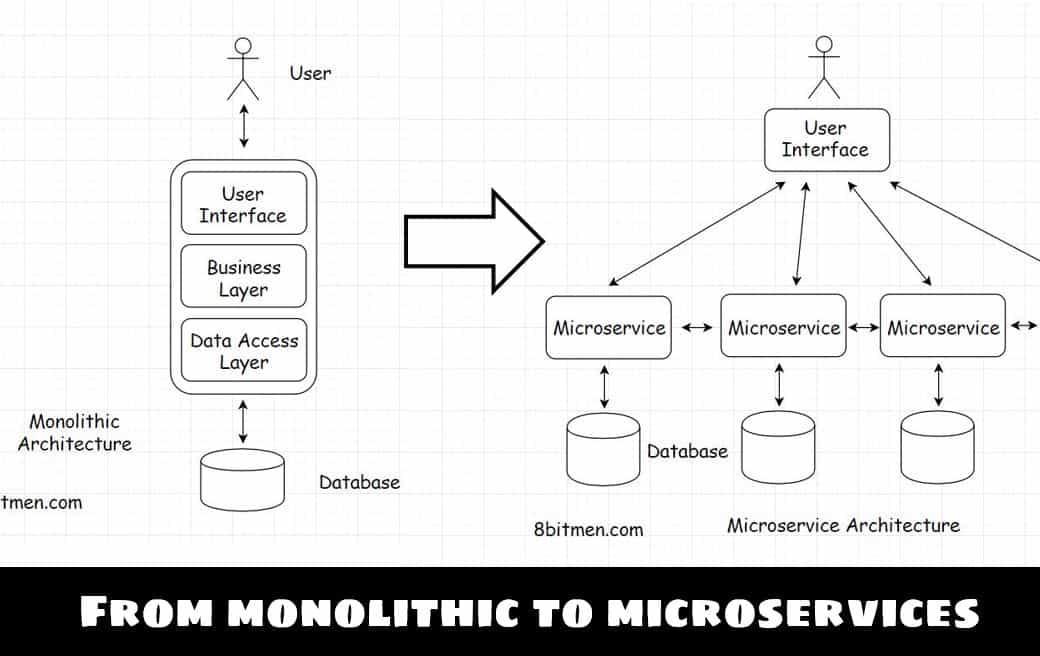
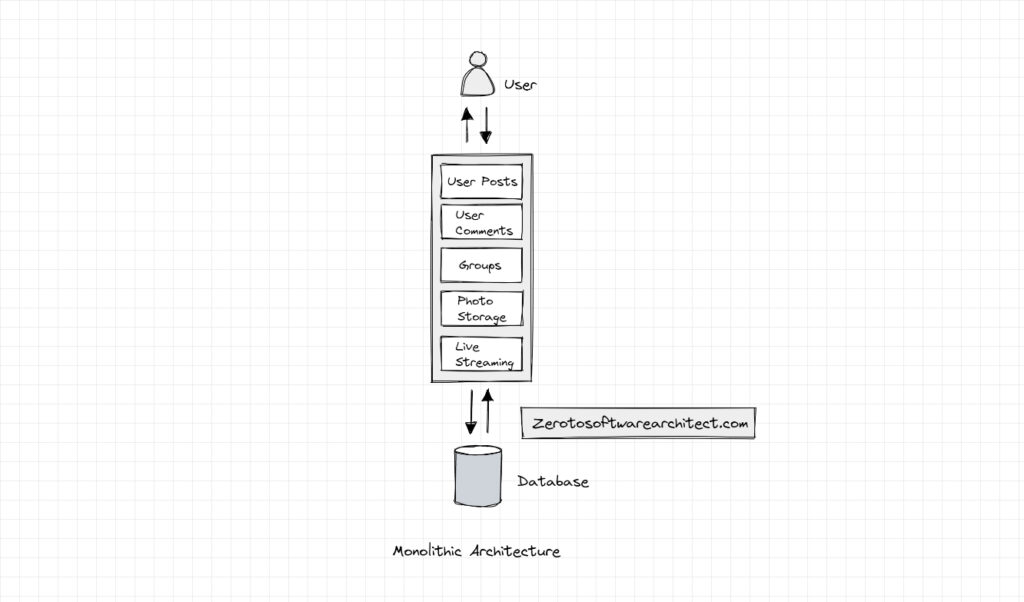
Uber started its service from San Francisco with a monolithic repo. The solo repo held the business logic for matching drivers and riders, running background checks, taking care of the billing and the payment and all the other related functionalities.
Distributed Systems
For a complete list of similar articles on distributed systems and real-world architectures, here you go
As the service got popular, the engineering team faced issues typical with monolithic repos. The issues of scalability, tightly coupled components, the entire codebase had to be redeployed for one tiny change in the code and so on.
Also, there was always this risk of cascading impact of the code change on the existing functionalities. Single repo implementations needed serious regression testing after deployments. Adding new features was cumbersome. All of these issues needed more developer resources.
The team decided to break free by transitioning to a distributed microservice architecture. Every service would take the onus of running a specific feature. Things would get loosely coupled. Teams could take ownership of repos. It was easier to add new features and make code changes without the risk of breaking everything.
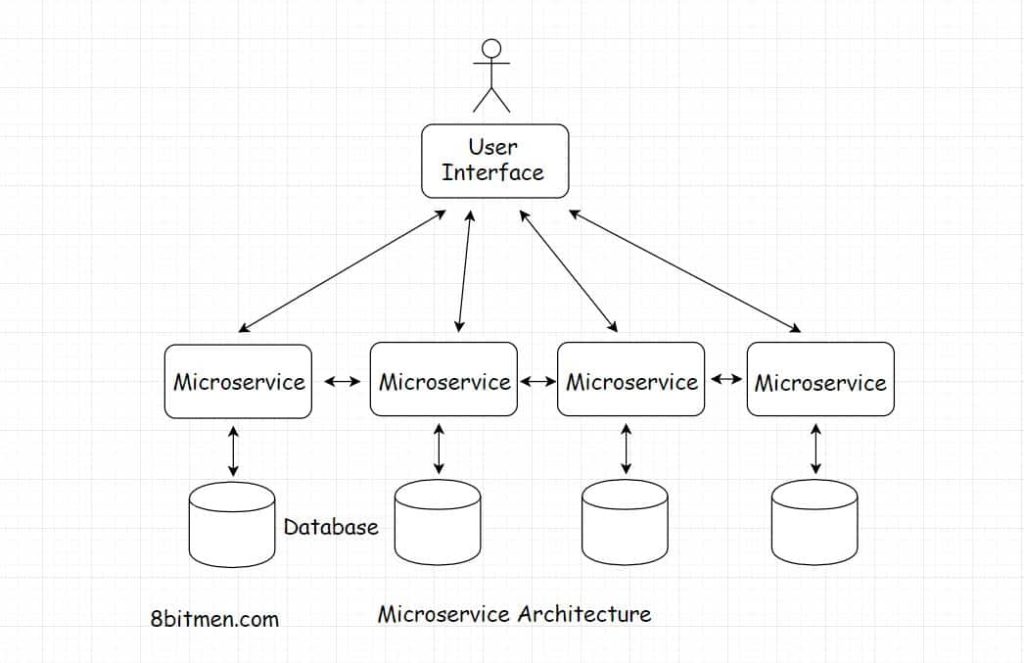
Also, with different services, it would be possible to leverage the power of a variety of technologies. The team would not be constrained with writing features using only a single tech.
The architectural transition resulted in 500+ microservices. But since everything in the software development universe is a trade-off, there is no silver bullet, no perfect tech or design. These services required a lot of resource investment in infrastructure management.
These microservices needed a standardized infrastructure to communicate with each other and implementation of a lot of additional functionalities such as authentication and authorization for every service, type-safety, validation, taking care of the logs, distributed service tracing, fault-tolerance, handling client-side timeouts, retry policies, service outages, service discovery, a standardized testing approach, cross-language support, a contract for communication to which all the services & the clients consuming the services could adhere to and so on.
For this, a lot of custom functionality had to be written from the ground up.
If you wish to understand how microservices communicate with each other in a distributed environment, how large-scale services are designed and much more, check out the Zero to Software Architect learning track (consisting of three courses) that I’ve written discussing web architecture in great detail.
Cross-Service Communication
Interface definition language IDL is a specification that provides a standard, a contract for cross-service communication. There are many IDL libraries and frameworks available but commonly used ones in the industry are Apache Thrift, Google Protocol Buffer, etc.
Thrift is used by Facebook. In not so recent past, I did write some code using the Protocol Buffer Library in a large-scale travel e-commerce project for cross-service communication. Protocol Buffer enabled me to serialize the Java object and wire it across to another service.
These IDL frameworks facilitate the serialization of structured data and transmission/storage of that data over the network in a neutral, platform-independent format. Error-free serialization and de-serialization is a tricky thing and these libraries take care of all the intricacies of it, helping the developers focus on the business logic. Thus saving us a big chunk of our time.
Also, as distributed systems have become more mainstream, there is a debate in the developer community regarding the performance of REST in a distributed environment and if they should revert to more lightweight fast RPC Remote procedure frameworks.
What do you think of the difference between a REST and an RPC call? Under what scenarios should we use the RPC or a REST-based API?
This Google cloud blog article is an insightful read on it. And here is a discussion on RPC vs REST on StackOverflow.
Coming back to the Uber architecture. They picked Apache Thrift for cross-service communication. Thrift provides type safety by binding the service to strict contracts. Services and the client are aware of what inputs and outputs to expect. The data types and the service interfaces are defined in a simple definition file to facilitate seamless communication. Thrift averts the need to write boilerplate code over and over & enables us to focus on the business logic, as I stated earlier.
The Uber engineering team also wrote fault tolerance libraries from the ground up just like Netflix’s Hystrix & Twitter’s Finagle.
Information source for the blog post.
This is pretty much it, folks. If you found the content helpful, consider sharing it with your network for better reach. I am Shivang, you can find me on LinkedIn here. For more articles on real-world distributed systems, visit this page on the blog. Until next time, Cheers.



Follow Me On Social Media