
This write-up is an insight into distributed data processing. It addresses the frequently asked questions on it such as: What is distributed data processing? How different is it in comparison to centralized data processing? What are the pros and cons? What are the various approaches and architectures involved in distributed data processing? What are the popular technologies and frameworks used in the industry for processing massive amounts of data across several nodes running in a cluster? and such.
So, without further ado.
Let’s get started.
Distributed Systems
For a complete list of similar articles on distributed systems and real-world architectures, here you go
Let’s have a quick insight into data processing before we delve into the distributed part of it.
1. What Is Data Processing?
Data processing is ingesting massive amounts of data in the system from several different sources such as IoT devices, social platforms, network devices, etc. and extracting meaningful information from it with the help of data processing algorithms. The whole process is also known as data analytics.
With it, businesses can leverage the information extracted from the raw, unstructured and semi-structured data in the terabyte, petabyte-scale to evolve their products, understand what their customers want, understand their product usage patterns, etc. With all the analytical information they can evolve their service or the product starkly.
2. What Is Distributed Data Processing? How Different Is It From Centralized Data Processing?
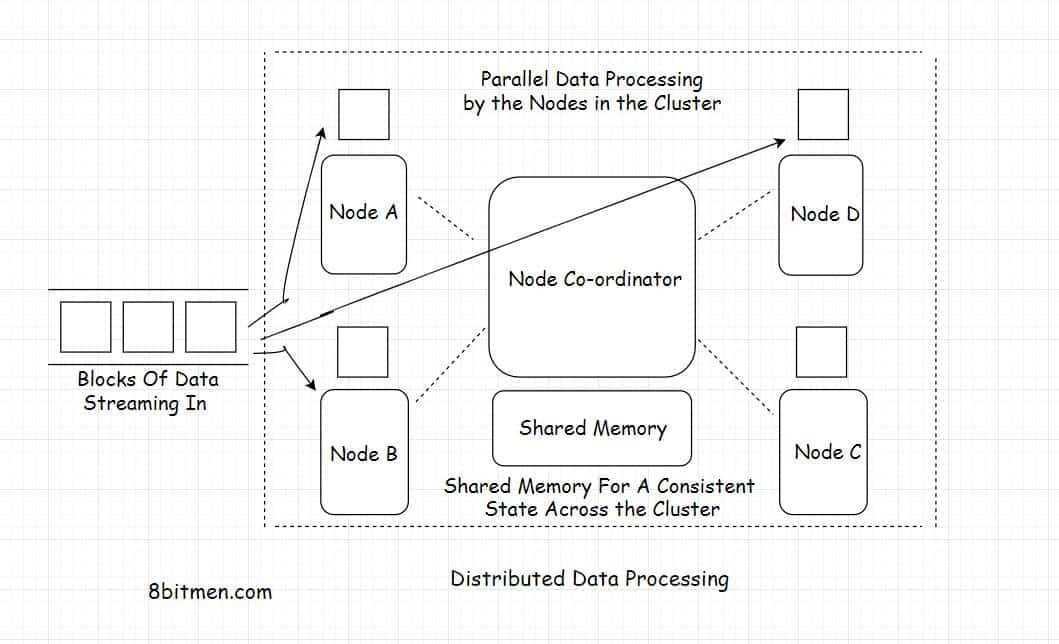
Distributed data processing is diverging massive amounts of data to several different nodes running in a cluster for processing.
All the nodes working in conjunction execute the task allotted parallelly, connected by a network. The entire setup is scalable and highly available.
What Are the Upsides Of Processing Data In A Distributed Environment?
Processing data in a distributed environment helps accomplish the task in a significantly less amount of time as opposed to when running on a centralized data processing system. This is solely due to the reason that here the task is shared by a number of resources/machines and executed parallelly as opposed to being run synchronously arranged in a queue.
Since the data is processed in lesser time, it is cost-effective for businesses helping them move fast.
Running a workload in a distributed environment makes it more scalable, elastic and available. There is no single point of failure. The workload can be scaled both horizontally and vertically. The data is made redundant and replicated across the cluster to avoid any sort of data loss.
3. How Does Distributed Data Processing Work?
In a distributed data processing system a massive amount of data flows through several different sources into the system. This process of data flow is known as data ingestion.
Once the data streams in there are different layers in the system architecture that break down the entire processing into several different parts.
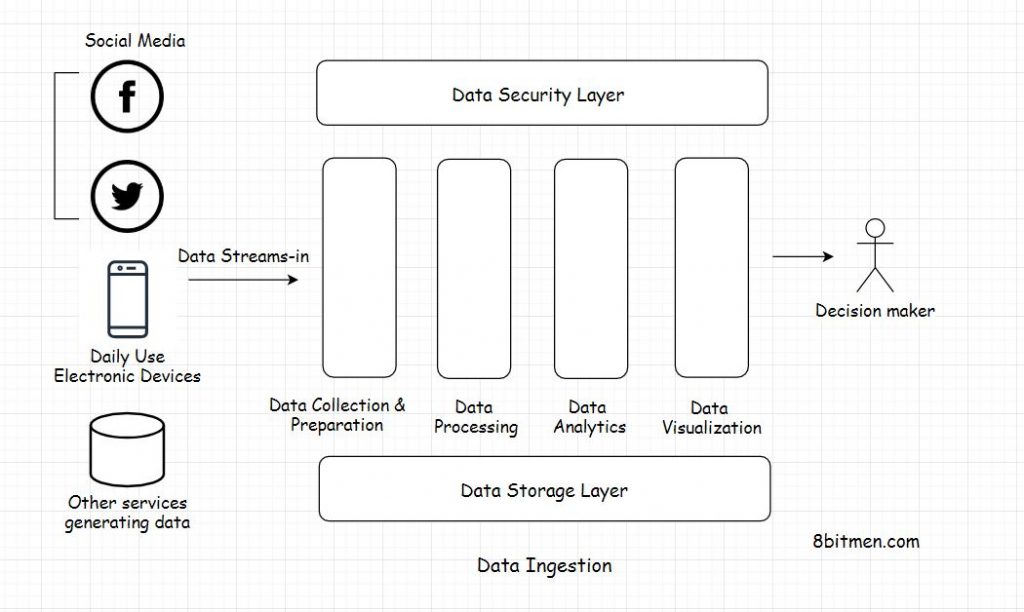
Let’s have a quick insight into what they are:
Data Collection and Preparation Layer
This layer takes care of collecting data from different external sources and prepares it to be processed by the system. When the data streams in it has no standard structure. It is raw, unstructured or semi-structured in nature.
It may be a blob of text, audio, video, image, tax return forms, insurance forms, medical bills etc.
The task of the data preparation layer is to convert the data into a consistent standard format, also to classify it as per the business logic to be processed by the system. The layer does this in an automated fashion without any sort of human intervention.
Data Security Layer
Moving data is vulnerable to security breaches. The role of the data security layer is to ensure that the data transit is secure by watching over it throughout with applied security protocols, encryption and such.
Data Storage Layer
Once the data streams in it has to be persisted. There are different approaches to doing this.
If the analytics is run in real-time on streaming data, in-memory distributed caches are used to store and manage it. On the contrary, if the data is being processed in a traditional way like batch processing, distributed databases built for handling big data are used to store the data.
Data Processing Layer
This is the layer that contains the business logic for data processing. Machine learning, predictive, descriptive, and decision modeling are primarily used to extract meaningful information.
Data Visualization Layer
All the information extracted is sent to the data visualization layer which typically contains browser-based dashboards which display the information in the form of graphs, charts and infographics.
Kibana is one good example of a data visualization tool popular in the industry.
4. What Are the Types Of Distributed Data Processing?
There are primarily two types: Batch processing and Real-time streaming data processing.
Batch Processing
Batch processing is the traditional data processing technique where chunks of data are streamed in batches and processed. The processing is either scheduled for a certain time of the day or happens in regular intervals or is random but not real-time.
Real-time Streaming Data Processing
In this, the data is processed in real-time as it streams in. Analytics is run on the data to get insights from it.
A good use case of this is getting insights from sports data. As the game goes on the data ingested from social media and other sources is analyzed in real-time to figure out the viewers’ sentiments, engagement, predictions etc.
Now, let’s talk about the technologies involved in both data processing types.
5. What Are the Technologies Involved In Distributed Data Processing?
MapReduce – Apache Hadoop
MapReduce is a programming model written for managing distributed data processing across several different machines in a cluster. It distributes tasks to machines in the cluster working in parallel, in addition to managing the communication and data transfer between them.
The Map part of the programming model involves sorting the data based on a parameter and the Reduce part involves summarizing the sorted data.
The most popular open-source implementation of the MapReduce programming model is Apache Hadoop.
The framework is used by all big guns in the industry to manage massive amounts of data in their system. It is used by Twitter for analytics, Facebook for storing big data and so on.
Apache Spark
Apache Spark is an open-source cluster computing framework. It provides high performance for both batch and real-time stream processing.
It can work with diverse data sources and facilitates parallel execution of work in a cluster.
Spark has a cluster manager and distributed data storage. The cluster manager facilitates communication between different nodes running together in a cluster whereas the distributed storage facilitates storage of big data.
Spark seamlessly integrates with distributed data stores like Cassandra, HDFS, MapReduce File System, Amazon S3, etc.
Apache Storm
Apache Storm is a distributed stream processing framework. In the industry, it is primarily used for processing massive amounts of streaming data.
It has several different use cases such as real-time analytics, machine learning, distributed remote procedure calls etc.
Apache Kafka
Apache Kafka is an open-source distributed stream processing and messaging platform. It’s written using Java & Scala & was developed by LinkedIn.
The storage layer of Kafka involves a distributed scalable pub/sub message queue that helps read and write streams of data like a messaging system. Kafka is used in the industry to develop real-time features such as notification platforms, manage streams of massive amounts of data, monitoring website activity, metrics, messaging, log aggregation and so on.
Hadoop is preferred for batch processing of data whereas Spark, Kafka and Storm are preferred for processing real-time streaming data.
6. What Are the Architectures Involved In Distributed Data Processing?
There are two popular architectures involved in distributed big data processing: Lambda and Kappa.
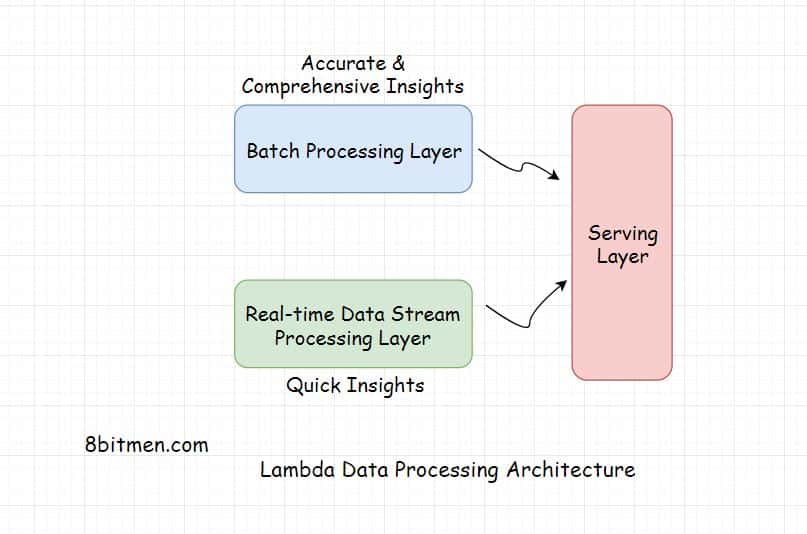
Lambda Architecture
Lambda is a distributed data processing architecture that leverages both the batch and the real-time streaming data processing approaches to tackle the latency issues arising out of the batch processing approach.
It joins the results from both approaches before presenting it to the end user.
Batch processing does take time considering the massive amount of data businesses have today but the accuracy of the approach is high and the results are comprehensive.
On the contrary, real-time streaming data processing provides quick access to insights. In this scenario, the analytics is run over a small portion of data so the results are not that accurate and comprehensive when compared to that of the batch approach.
Lambda architecture makes the most of the two approaches. The architecture typically has three layers the Batch Layer, the Speed Layer and the Serving layer.
The Batch Layer deals with the results acquired via batch processing of the data. The Speed layer gets data from the real-time streaming data processing and the Serving layer combines the results obtained from both the Batch and the Speed layers.
Kappa Architecture
In this architecture, all the data flows through a single data streaming pipeline as opposed to the Lambda architecture which has different data streaming layers which converge into one.
The architecture flows the data of both real-time and batch processing through a single streaming pipeline reducing the complexity of not having to manage separate layers for processing data.
Kappa contains only two layers: Speed, which is the streaming processing layer and the Serving, which is the final layer.
P.S. Kappa is not an alternative to Lambda. Both architectures have their use cases.
Kappa is preferred if the batch and the streaming analytics results are fairly identical in a system. Lambda is preferred if they are not.
Both architectures can be implemented using the distributed data processing technologies I’ve discussed above.
7. What Are the Pros & Cons Of Distributed Data Processing?
This section involves the pros and cons of distributed data processing, though I don’t consider the cons as cons. Rather they are the trade-offs of working with scalable distributed systems.
Let’s look into them.
Pros
Distributed data processing facilitates faster execution of work with scalability, availability, fault tolerance, replication and redundancy which gives it an edge over centralized data processing systems.
Since the system is loosely coupled, enforcing security, authentication and authorization workflows over specific modules becomes easier.
Cons
Setting up and working with a distributed system is complex. Well, that’s expected. Having so many nodes working in conjunction and maintaining a consistent shared state, things get complex.
Since the machines are distributed, it entails additional network latency which devs have to take into account. Strong consistency of data is hard to maintain when everything is so distributed.
Well, Folks! This is pretty much it. If you liked the write-up, share it with your network for more reach.
I am Shivang. You can read more about me here.
Check out the Zero to Software Architecture Proficiency learning path, a series of three courses I have written intending to educate you, step by step, on the domain of software architecture and distributed system design. The learning path takes you right from having no knowledge in it to making you a pro in designing large-scale distributed systems like YouTube, Netflix, Hotstar, and more.



Follow Me On Social Media