
{kind=link}
Wide-column, column-oriented and column-family databases belong to the NoSQL family of databases built to store and query massive amounts of data, aka BigData.
They are highly available and scalable, built to work in a distributed environment. Most of the wide-column databases do not support joins to scale linearly when it comes to read and write performance.
Some of the popular wide-column stores are Google Bigtable, Apache Cassandra, HBase, etc.
Before I plunge into the topic, let me give you a little heads up on the common data storage models.
Data storage models
Row-oriented
Column-oriented
Column-family
Row-oriented databases
Row-oriented databases are the traditional relational databases like MySQL and PostgreSQL that store data in rows.
For instance, here is how a row-oriented database will store the details of a customer.
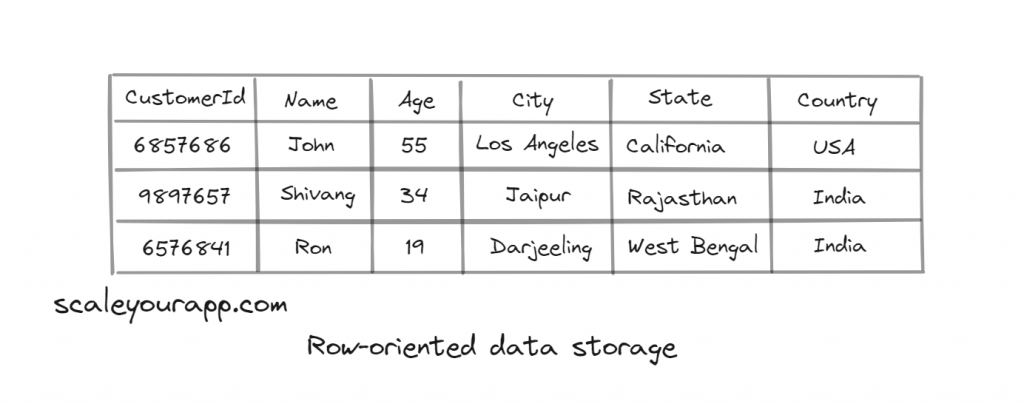
In a row-oriented database, the data is stored in rows on the disk in contiguous locations or blocks. On running a query, it’s easy to fetch an entire row of data for a particular customer since it resides in the same block.
It’s also easy to update customer data since all the data for a certain customer is stored in a single row. Even in the case of partitions, the rows are partitioned horizontally. The columns containing data of a particular customer always stay together on the disk.
This data storage model is best suited for OLTP (Online transactional processing) use cases.
Now let’s move on to column-oriented databases.
Column-oriented databases
Column-oriented databases, on the other hand, store data in columns as opposed to rows.
In this scenario, the customer ids will be stored on the disk at a certain location in one column, customer names in another column, customer city and country will be in respective columns and so on.
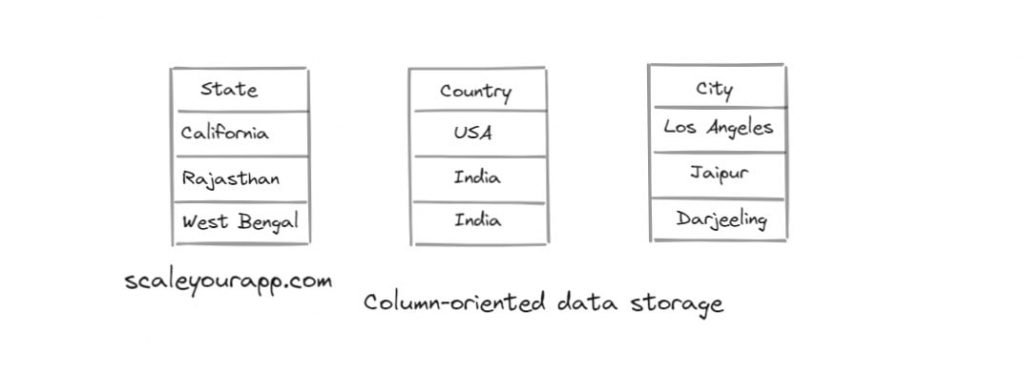
These databases are best suited for OLAP (Online analytical processing) use cases. They provide the best performance when similar data is stored in columns on the disk. Examples of column-oriented databases are Google BigQuery and Amazon Redshift.
But why do we need to store data in columns as opposed to rows?
Imagine the above customer info table having billions of rows and the business needs to run analytics on the data. Say it needs to run a query to determine the percentage of customers from a particular country.
If the data was stored in rows on the disk, the query would have to traverse a large number of disk blocks (across machines, since the data would be partitioned) to figure out the results, processing unnecessary data.
On the flipside, on saving columns on the disk, the query will only process the country column, neglecting other customer data, providing high-throughput reads. It wouldn’t have to scan through rows of customer data. Also, similar data in columns can be compressed by using techniques such as run-length encoding, requiring less storage space than row-based data.
Column-oriented databases are suited for analytical use cases where the business has to make sense of large volumes of data. However, in this scenario, if we need to add a new row of customer data, this would prove to be resource-intensive since we have to access all the columns to add a new record in them.
For writing customer data, a row-oriented database would suit best.
Both the data storage models have their pros and cons and use cases.
Wide-column database is a term for databases built for storing large amounts of data in flexible columns. Different wide-column databases have different implementations when it comes to their data storage model and clustering implementation. I’ll come to that up ahead in the article.
There is no strict, well-defined definition of the difference between a wide-column database and a column-oriented datastore.
Now, let’s move on to understanding column-family databases.
Column-family databases
Column family databases store similar columns in column families. A row in these databases typically contains multiple column families.
The most popular example of a column-family database is Google Bigtable. Let’s plunge into it, understanding its data storage model.
Google Bigtable – A column-family database
Bigtable is a distributed column-oriented database that can scale to large sizes upto petabyte-scale running across thousands of commodity servers.
If you wish to understand the cloud infrastructure that powers our apps globally, how clusters work, how petabyte-scale data is stored in the cloud with minimum latency, how are apps deployed globally on the cloud, deployment workflow, monitoring and much more, check out my platform-agnostic cloud computing course.
It can also be used with the MapReduce framework acting as a data source, also to persist the results of the large-scale parallel computation jobs.
The distributed storage system is specifically built by Google to handle structured BigData, keeping low latency in mind. Bigtable powers over sixty Google products, including Google Earth, Google Finance, Search web indexing, and Analytics.
The products have varied requirements, from throughput-focused batch processing to low-latency real-time data access by the end-users.
Speaking of its data model, the product offers dynamic control over the data layout, format, locality of data, and if data is to be served from the memory or the disk.
Bigtable is a sparse, distributed, persistent multidimensional sorted map. The key in the map constitutes a row key, a column key, and a timestamp. And the value is an array of bytes.
What does sparse mean here? Sparse means that most of the cells in the table would be zero or empty. The data model is designed keeping in mind the use cases of a Bigtable-like system. Let’s understand this with the help of an example.
Persisting a web page with Bigtable
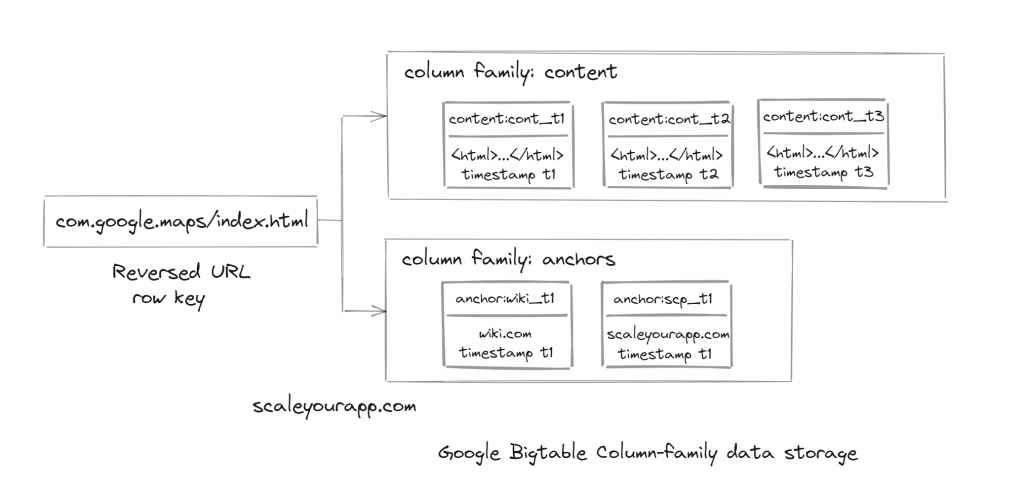
Here is a Bigtable table storing web pages. (Folks, I need your focus here, things are not so obvious with this data model.) The row key is the reversed url of the web page.
For instance, if the web page url is: maps.google.com/index.html the row key will be com.google.maps/index.html. In BigTable, pages of the same domain are stored in contiguous rows for efficient analytics. Also, the read/write of data under a single row key is atomic. This makes it easier to reason the system’s behavior during concurrent updates to the same row.
Moving on to the column. The value of the map will be stored along with the column with a timestamp. The value will contain the contents of the web page ‘maps.google.com/index.html‘
The column key, let’s name it ‘content_t1‘ for now, will have a timestamp. Now since a web page is updated from time to time, there will be several web page values with different timestamps. So, the row key will have several column keys with different values with different timestamps.
All these column keys will be grouped inside a column family, let’s call it ‘content‘
Timestamps are 64-bit integers representing time in microseconds; they can also be tweaked by the developers. They are added to avoid collisions and column keys are stored in decreasing order with timestamps (newest version first). Developers can specify the n versions to be kept in memory the rest can be garbage collected by the Bigtable.
In BigTable, the column key is named using the following syntax: column family: qualifier. When designing the data model, the column family has to be created before persisting any column key.
Also, the web page maps.google.com/index.html will contain several links to other external domains on the web. We will create separate columns for that with timestamps and house them under a different column family ‘anchors‘.
This is how data is stored in column family databases. I hope you get the idea.
Hopping back to our customer info table example.
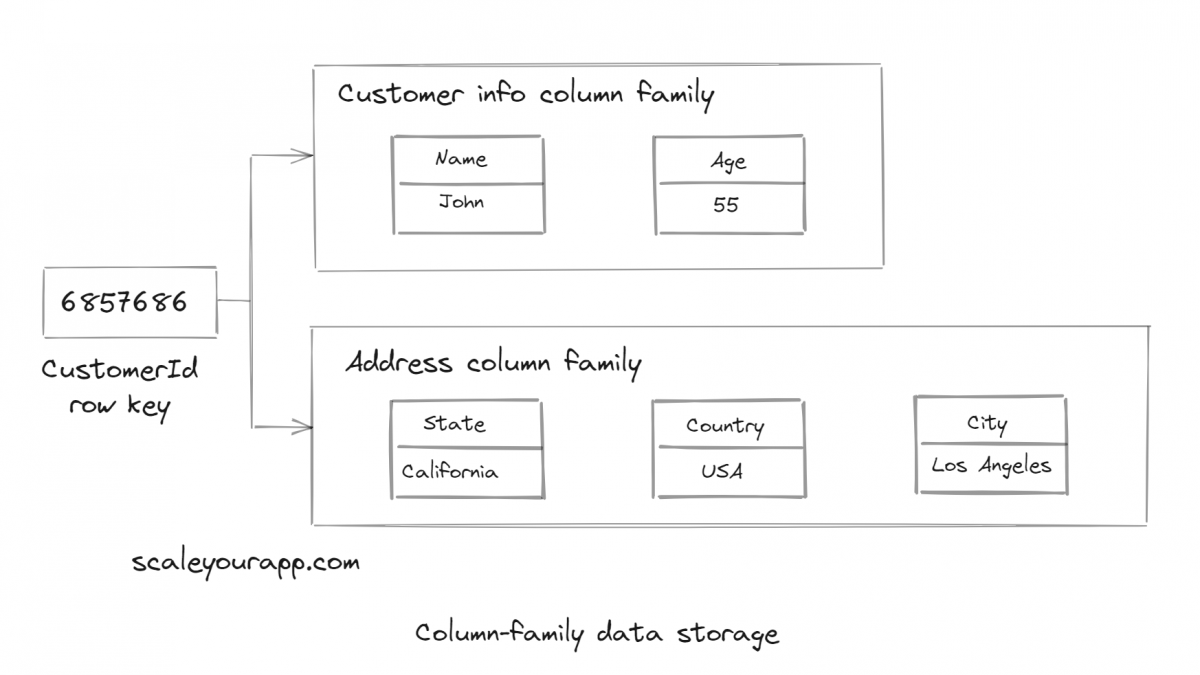
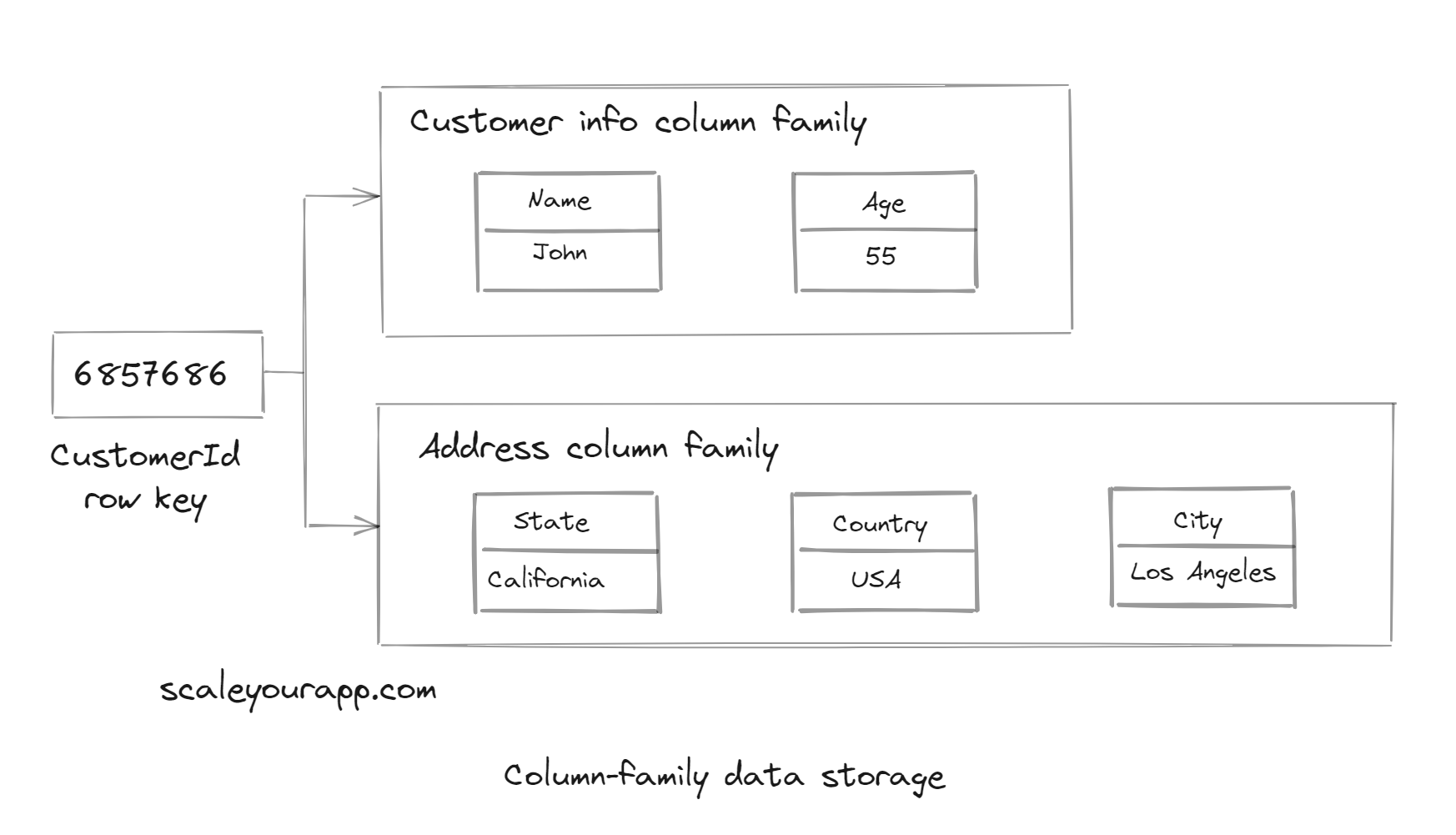
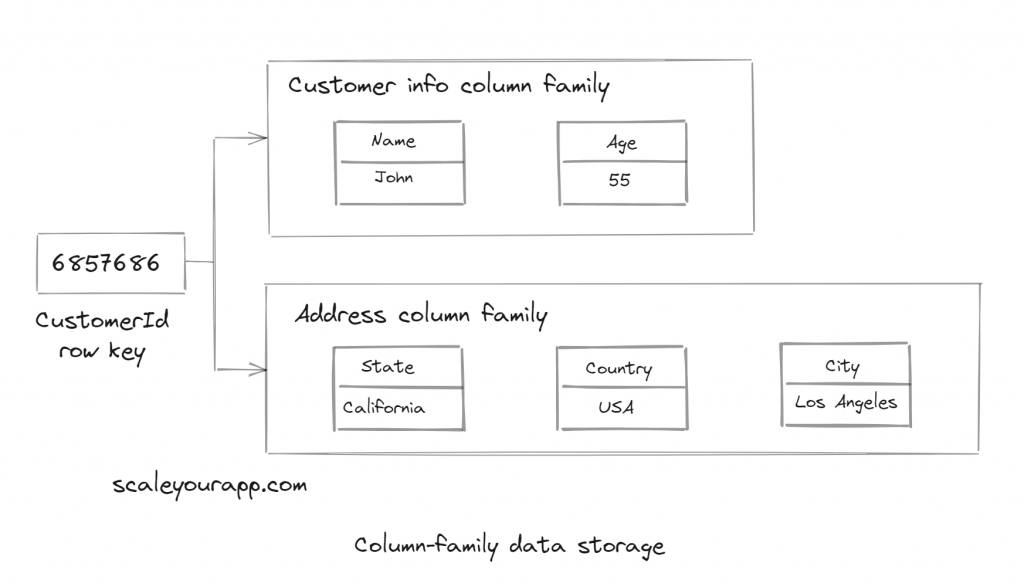
Column-family data storage model
Applying the similar BigTable column-family data storage model here, we will have the CustomerId as the row key. And then, we can have two column families, CustomerInfo and Address, containing respective columns. We can also add timestamps to the columns based on our requirements.
Architectures in Column Family Databases
Two commonly used architectures in distributed (column-oriented and column-family) databases meant for handling big data are: multiple node type (implemented by HBase) and peer to peer type (implemented by Cassandra)
Multiple Node Type: HBase
HBase, modeled after Google BigTable, uses the master-slave architecture consisting of name nodes and data nodes. Zookeeper facilitates coordination between different nodes.
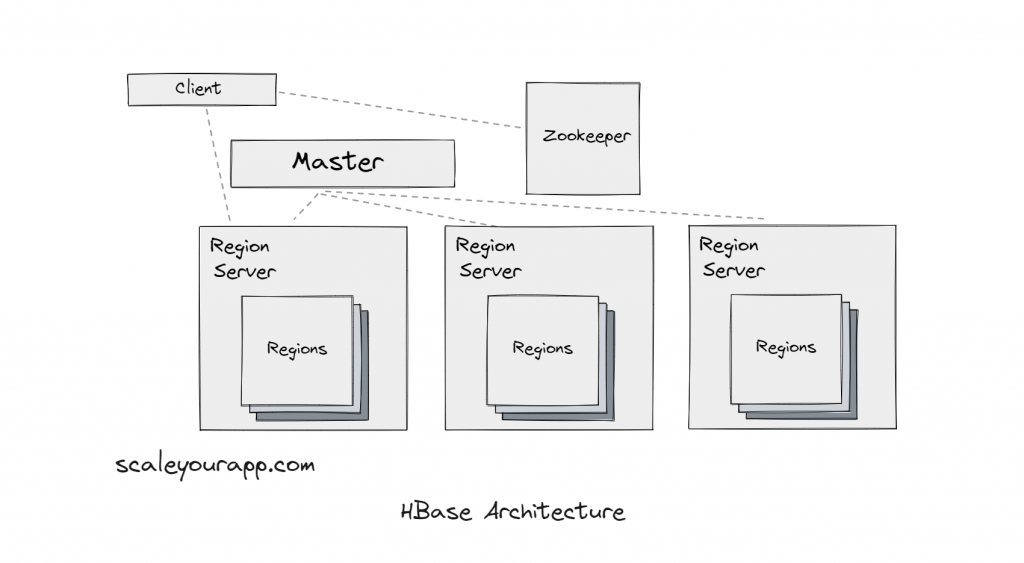
Initially, data in HBase is stored in a single region, but as the volume grows, it is partitioned into different regions managed by region servers. The master node keeps an eye on the region servers. To read data, the client sends a request to the Zookeeper server to figure out the region server for the respective data.
Peer-to-Peer: Cassandra
On the other hand, Cassandra (primarily used for write-intensive operations) uses a peer-to-peer architecture with only one type of node.
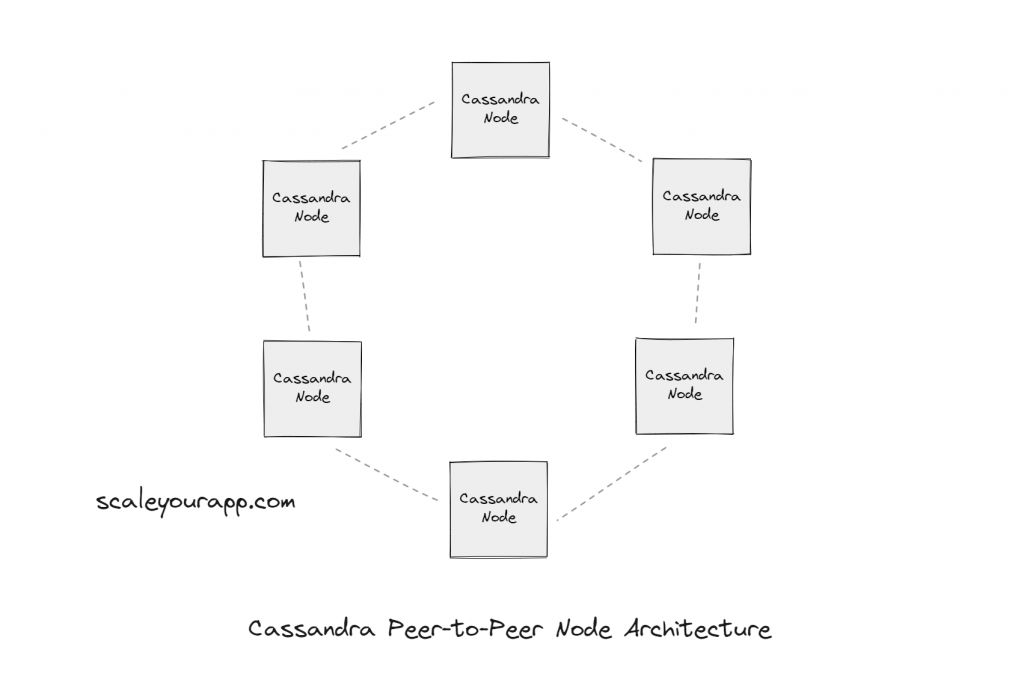
Instead of a hierarchical structure, Cassandra implements a peer-to-peer model where all nodes in the architecture are the same and run the same code.
This facilitates architectural simplicity, no single point of failure, and addition and removal of nodes on the fly. The Cassandra cluster, with the help of different protocols, ensures: each node has the updated data, sharing of node state in the cluster, ensuring write-data is stored in other nodes if the node that should receive the write is offline.
These are very simplified explanations of the HBase and Cassandra implementation. In the future posts I’ll delve deep into them.
This write-up is an excerpt from my Web Architecture 101 course. For detailed learning on databases and other components in web architecture. Check it out here.
Reference:
Bigtable: A distributed storage system for structured data
If you found the content helpful, I run a newsletter called Backend Insights, where I actively publish exclusive posts in the backend engineering space encompassing topics like distributed systems, cloud, application development, shiny new products, tech trends, learning resources, and essentially everything that is part of the backend engineering realm.
Being a part of this newsletter, you’ll stay on top of the developments that happen in this space on an ongoing basis in addition to becoming a more informed backend engineer. Do check it out.
Distributed Systems
For a complete list of similar articles on distributed systems and real-world architectures, here you go


Follow Me On Social Media