
This write-up is an insight into distributed cache. It addresses the frequently asked questions on it such as: What is a distributed cache? What is the need for it? How is it architecturally different from traditional caching? What are the use cases of distributed caches? What are the popular distributed caches used in the industry? and so on.
So, without further ado.
Let’s get started.
Distributed Systems
For a complete list of similar articles on distributed systems and real-world architectures, here you go
Before getting to distributed caching let’s have a quick insight into caching. Why do we use cache in our applications in the first place?
1. What Is Caching And the Need For It?
Caching means saving frequently accessed data in memory, that is in RAM, instead of the hard drive. Accessing data from RAM is quicker than accessing it from the hard drive.
When it comes to web applications, caching reduces the application latency by notches. And this is because it has all the frequently accessed data stored in RAM, it doesn’t have to talk to the hard drive and compute results every time the user requests certain data. This behavior speeds up our applications significantly.
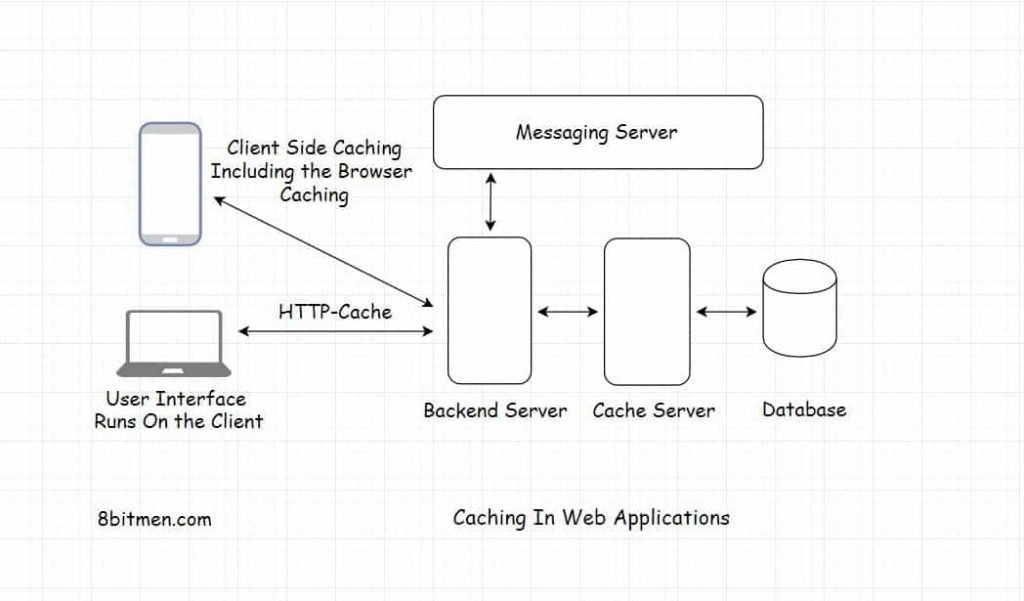
The cache component in addition to serving frequently accessed data also intercepts the user write requests and updates the database at stipulated intervals as opposed to doing it in real-time. This cuts down the load on it starkly.
This flow/behavior may not be required in most cases but helps get rid of database bottlenecks in certain specific scenarios. The database is hit with significantly less number of requests. This also helps cut down the database cloud costs when the application is write-heavy.
And it’s not just with the database, caching can be leveraged at different places and with different components in an online service to make the service performant.
Let’s explore this a bit more.
2. Getting the Application Compute Costs Down With Caching
Deploying a cache is comparatively cheaper in comparison to the database persistence costs. Database read-write operations are expensive.
There are times when there are just too many writes on the application, for instance, in massively multiplayer online games.
Data that is of low priority can be just written to the cache and periodic batch operations can be run to persist data to the database. This helps cut down the database costs by a significant amount.
Well, this is how I brought down the deployment costs for my application deployed on the cloud. Now that we are clear on what caching is. Let’s move on to distributed caching.
3. What Is Distributed Caching And the Need For It?
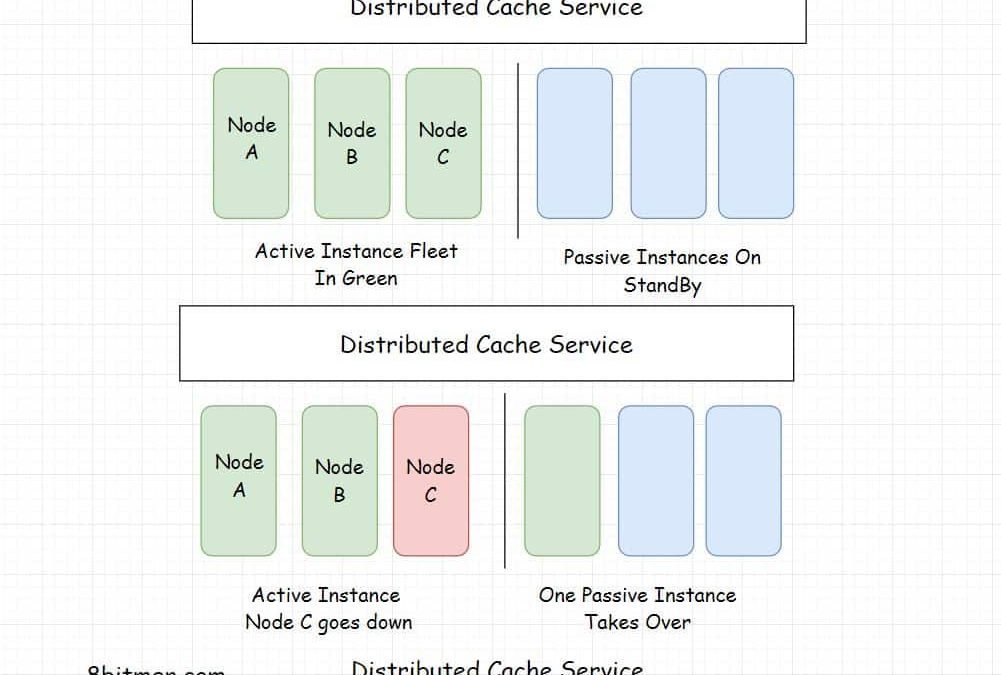
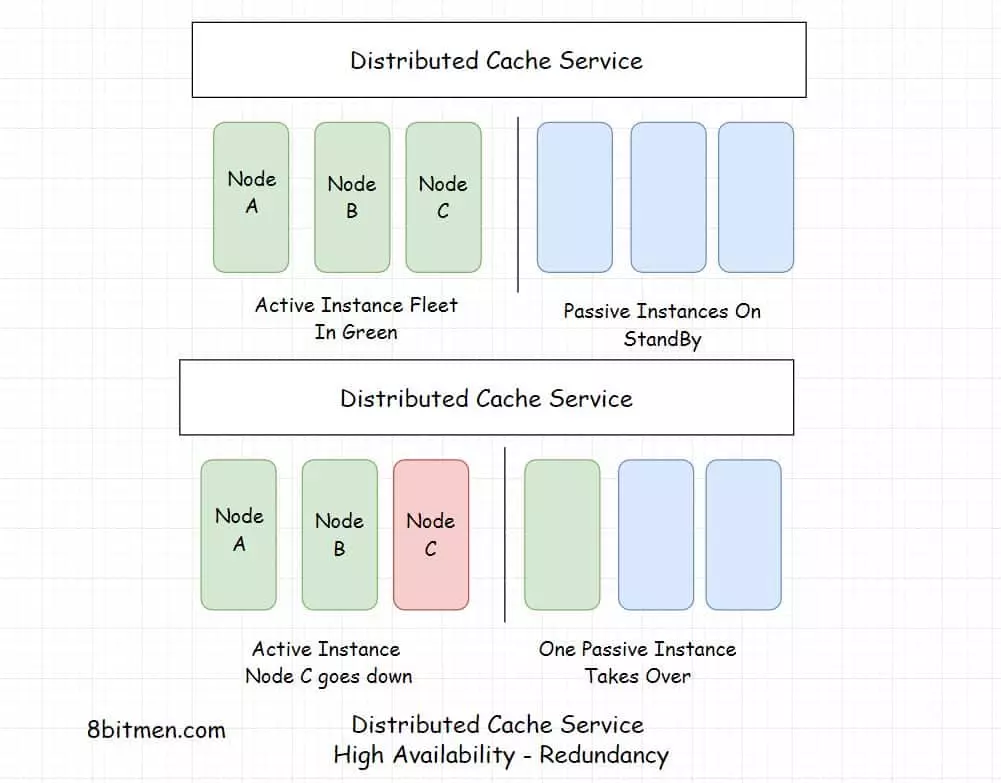
A distributed cache is a cache that has data spread across several nodes in a cluster in addition to across several clusters across several data centers across the globe.
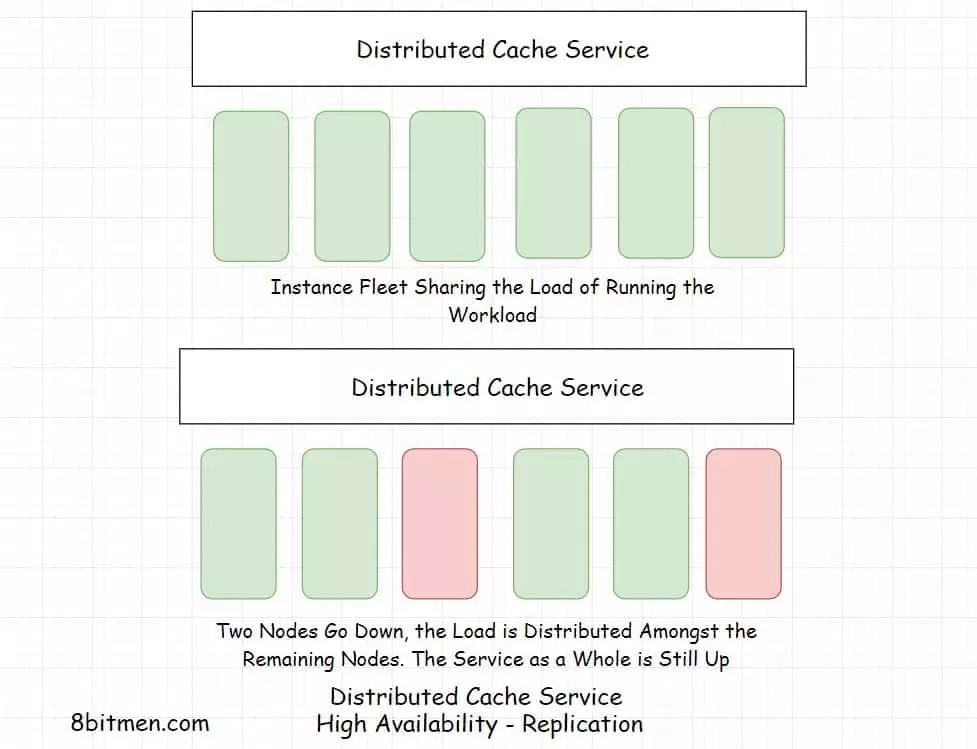
Being deployed on multiple nodes helps with horizontal scalability, instances can be added on the fly as per the demand. Distributed caching is primarily used by businesses due to the ability to scale on demand and be available.
Scalability, high availability and fault tolerance are crucial to large-scale services. They are distributed across multiple nodes with good redundancy.
Leveraging distributed systems in building scalable cloud-native applications is the norm. This is solely due to their ability to scale and be available.
Google Cloud uses Memcache for caching data on its cloud platform. Redis is used by internet giants for caching, as a NoSQL datastore and other use cases.
Systems are designed distributed in nature to scale inherently. They are designed in a way that their compute and storage capacity can be augmented on the fly. This is the reason a distributed cache with the ability to scale horizontally is preferred in large-scale distributed services.
4. Distributed Cache Use Cases In Online Services
Listed below are a few use cases of distributed cache:
Database Caching
The cache layer in front of a database saves frequently accessed data in-memory to cut down latency and load on it. With caching implemented possibilities of a DB bottleneck is greatly reduced.
Storing User Sessions
User sessions are stored in the cache to avoid losing the user state in case any of the instances go down.
In case an instance goes down, a new instance spins up, reads the user state from the cache and continues the session without having the user notice anything.
Cross-Module Communication And Shared Storage
In memory distributed caching is also used for message communication between different microservices running in conjunction.
The cache saves the shared data which is commonly accessed by all the services. It acts as a backbone of microservice communication. Distributed caching in certain use cases is also used as a NoSQL key value primary application datastore.
In-memory Data Stream Processing And Analytics
As opposed to traditional ways of storing data & then running analytics on it (batch processing), with distributed cache we can process data and run analytics on it in real-time.
Real-time data processing is helpful in multiple scenarios such as anomaly detection, fraud monitoring, fetching real-time stats in an MMO game, real-time recommendations, payments processing and so on.
5. How Does A Distributed Cache Work?
A distributed cache under the covers is a distributed hash table that maps object values to keys spread across multiple nodes. The cache manages the addition, deletion and failure of nodes in the cluster continually as long as the service is online. Distributed hash tables were originally used in the peer to peer systems.
Speaking of the standard cache design, caches evict data based on the LRU (Least Recently Used) policy and typically leverage a linked list to manage the data pointers. The pointer of the data frequently accessed is continually moved to the top of the list/queue. A queue is implemented using a linked list.
The data which is not so frequently used is moved to the end of the list and eventually evicted.
Linked list is a fitting data structure where we require too many insertions, deletions and updates in the list. It provides better performance in contrast to arrays.
Regarding concurrency there are several concepts involved such as eventual consistency, strong consistency, distributed locks, commit logs and such.
If you wish to have a deep dive into how distributed systems manage concurrency and more, check out my distributed systems design course here.
Distributed caches often work with distributed system coordinators such as Zookeeper. They facilitate communication in the cluster helping maintain a consistent state amongst the cache nodes.
6. Caching Strategies
We have different caching strategies for different use cases such cache aside, read through, write-through and write-back.
Let’s find out what they are and why we need them.
Cache Aside
This is the most common caching strategy. In this approach, the cache works along with the database with an aim to reduce the hits on it as much as possible. The data from the database is lazy loaded in the cache.
When the user sends a request for certain data. The system first looks for it in the cache. If present, it’s returned. If not, the data is fetched from the database, the cache is updated and is returned to the user.
This strategy works best with read-heavy workloads. Works best with the sort of data that is not frequently updated. For instance, user profile data in a portal. Their name, account number, and so on.
The data in this strategy is written directly into the database, not through the cache. This means there is a possibility of data inconsistency between the cache and the database. To avoid this the data in the cache has a TTL (Time To Live). After TTL expires, the data is invalidated from the cache.
Read-Through
This strategy is similar to the cache aside strategy with subtle differences. In the cache aside strategy the application has to fetch information from the database, if it is not found in the cache. This logic has to be explicitly coded. The developers have to write logic for cache management and synchronization with the database explicitly to ensure data consistency.
But in the read-through strategy, the cache sits inline with the database and stays consistent with the database. The cache library takes the onus of maintaining consistency with the database. This simplifies the application code with the cache management code abstracted by the framework.
So, if we need control over cache management we would go with the cache aside strategy. And can move forward with the read-through approach if we are happy with the cache management code abstracted away.
The data in both strategies is lazy loaded in the cache. Only when the user requests it.
So, for the first time when information is requested, it results in a cache miss, the backend has to update the cache while returning the response to the user. However, the developers can pre-load the cache with the information which is expected to be requested most by the users.
Write-Through
In this strategy, every piece of information written to the database goes through the cache. Before the data is written to the DB, the cache is updated with it.
This maintains strong consistency between the cache and the database though it adds a little latency during the write operations as data is to be updated in the cache additionally. This works well for use cases where reliability and durability of data is crucial. For instance, transactional systems, like stock trading, banking applications, etc.
This strategy is used with other caching strategies to achieve optimized performance.
Write-Back
I’ve discussed this approach already up above in the article 🙂 It helps optimize costs significantly.
In the write-back caching strategy the data is directly written to the cache as opposed to the database. And the cache after some delay as per the business logic writes data to the database.
If there are quite a heavy number of writes in the application, developers can reduce the frequency of database writes to cut down the load and compute costs.
However, there is a risk of data loss in this approach. If the cache fails before the DB is updated, the data might get lost. Again this strategy can be used with other caching strategies to make the most out of these.
Well, Folks! This is pretty much it. If you found the content helpful, share it with your network for more reach.
Check out the Zero to Software Architecture Proficiency learning path, a series of three courses I have written intending to educate you, step by step, on the domain of software architecture and distributed system design. The learning path takes you right from having no knowledge in it to making you a pro in designing large-scale distributed systems like YouTube, Netflix, Hotstar, and more.



Follow Me On Social Media