
{kind=link}
How Actor model/Actors run in clusters facilitating asynchronous communication in distributed systems
This blog post is a continuation of my previous post, in the system design series, on understanding the actor model to build non-blocking, high-throughput distributed systems. If you haven’t read it, I suggest giving it a read.
Various Actor model frameworks, like Akka, ProtoActor, Actix, etc., have cluster implementations with subtle differences. In this write-up, I’ll give an insight into how Akka runs actors in clusters in a non-blocking way.
Actors in distributed clusters
We know from the previous post that the actor model is natively asynchronous, with the entire communication happening with the help of the exchange of messages. In the actor model, things are designed to work inherently in a distributed environment.
For instance, a local message between actors within a JVM and a remote message to be sent to another actor running in a different cluster will look the same. There will be no inherent design differences, with the fundamental communication mechanism being the same.
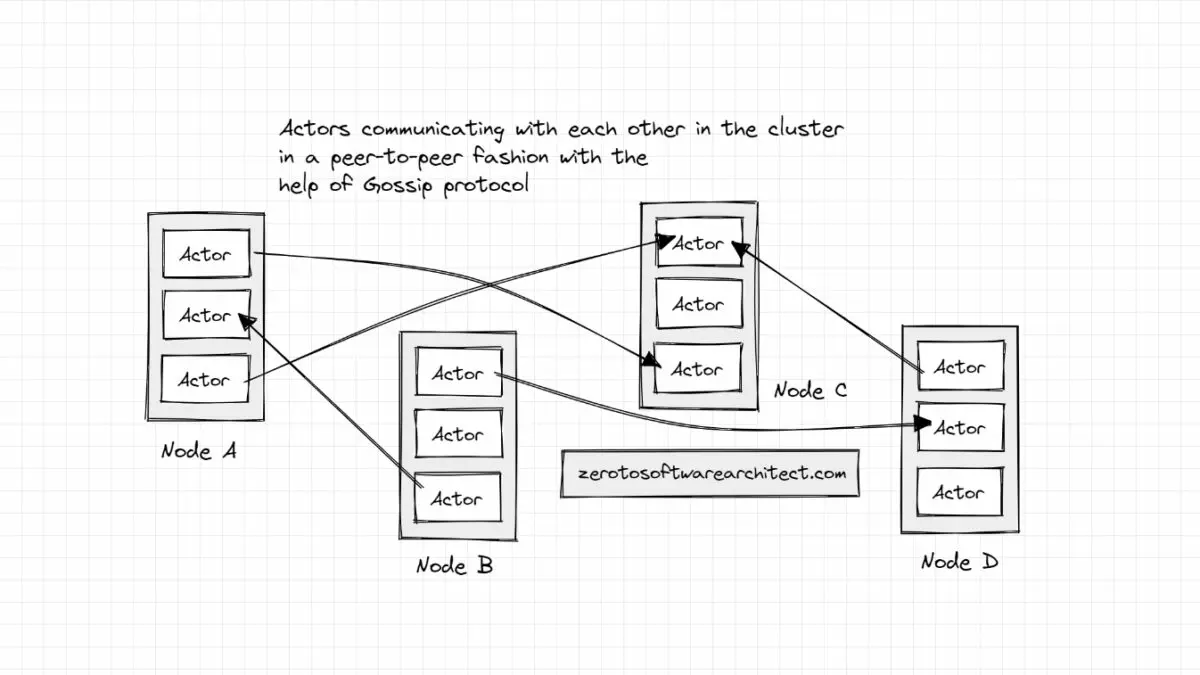
In Akka, the actors in the distributed system communicate with each other in a peer-to-peer fashion with the help of the Gossip protocol that enables every actor to communicate with each other independently without forming any system bottleneck.
The Gossip protocol is a peer-to-peer communication protocol that facilitates information sharing in a distributed system. It runs periodically in a cluster or a group of clusters spreading information amongst nodes like gossip so that all the nodes know what is happening in the cluster or the distributed system. Apache Cassandra leverages this protocol to manage state in its clusters.
Although actors are inherently designed to run in a distributed environment, keeping closely collaborating actors in the same JVM is a good practice to dodge network latency and ensure message delivery reliability.
If you wish to understand how nodes work together in distributed clusters maintaining a consistent state across, how applications are deployed across the globe in different cloud regions and availability zones for better availability and scalability, the infrastructure on which our applications run and more, check out my platform-agnostic Cloud Computing 101 course that helps you master the fundamentals of the domain. This is also the second course in my Zero to Software Architect learning track that takes you right from zero to becoming a pro in designing real-world distributed applications.
A distributed system comprising multiple clusters with multiple nodes running is inherently volatile, with the possibility of any node or a few nodes going down at any moment. In case of a few nodes going down, actors sending messages to offline nodes could impact the system’s consistency.
To tackle this, messages are routed to actors with the help of cluster-aware routers. These routers route the messages to actors with a routing algorithm and the knowledge of the current state of the cluster.
There also exists an actor registry that spans clusters helping actors discover other actors in the system they intend to collaborate with. The actors can be looked up in the registry with the key they registered with to the registry.
Handling Exceptions in a resilient fashion
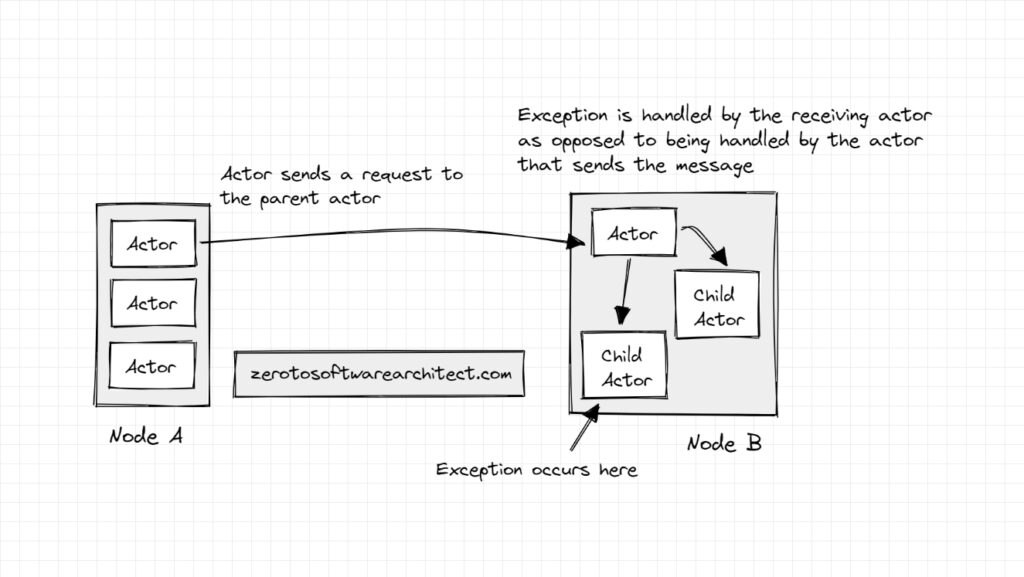
When an actor sends a message to another actor, the sender actor doesn’t have to handle the exception thrown by the receiving actor if any issue arises during the message request processing. Well, this is not the case in a typical object-oriented system. In OOP code, typically, the calling method has to either deal with the exception thrown in the called method or propagate it up the call stack.
But in the case of distributed actors, the parent receiving actor (considering the receiving actor has a hierarchy with child actors) deals with the exception since it best knows how to deal with it. It may also restart the child actor (that encountered an exception) to reprocess the message. All the sender actor gets is a simple message of the request being successful or failed. This ensures better system resiliency.
In addition to this, given the fundamental system behavior is asynchronous and non-blocking in nature, the sender actor doesn’t wait for the message from the receiver. However, it expects it. If it doesn’t receive the message may be due to network failure, it has a fallback mechanism ready.
Following it, it may resend a message to itself after a specified interval and to the receiver actor.
Cluster state management
The state is managed in the cluster with the help of a key-value store like API. The keys are the unique identifiers and the values are CRDTs (Conflict-Free Replicated Data Types). The data can be accessed by the actors using this API.
The data is spread across the system either via replication or the gossip protocol. CRDTs make it possible to update nodes without distributed node coordination. The concurrent updates made to the nodes are resolved with the help of a merge function.
In my distributed systems design course, I’ve had a detailed discussion on how distributed systems handle data conflicts when deployed across the globe with the help of CRDTs, Operational transformation, clock synchronization algorithms, etc., in addition to, how distributed transactions work, discussion on different data models, database growth strategies and a lot more. The course helps you learn to design distributed systems for web-scale traffic following industry best practices and insights from real-world architectures. Do check it out.
With every request, a consistency level is provided as an argument that decides how many nodes must respond to a write or a read request. Writing to or reading from all nodes ensures the highest consistency but also has the highest latency.
We can configure the number of nodes the write has to be at least performed on to be deemed a successful write operation. Also, the write can be performed on a local cluster node and then the information can be spread across the distributed system (comprising several clusters) with the help of gossip protocol. Configuration primarily depends on the use case and the expected system behavior.

Cluster Sharding: Distributing actors across several nodes in the cluster
Actors are distributed across nodes in the cluster with the help of cluster sharding. Sharded actors are identified with their logical identifiers and messages can be exchanged between them without knowing their physical location in the cluster. This helps when the physical locations of the actors change dynamically in the cluster.
Actor sharding is achieved with the help of cluster-aware routers, I discussed above. The actors are distributed across the shards by the hash of their ids. If you wish you understand sharding, I’ve discussed it in my system design course, as well.
Actors are also deployed across data centers for redundancy and to improve the response time by running an actor closer to the client. However, communication between data centers typically has more latency and failure rate as opposed to communications happening within a data center.
Handling network partitions
Network partitions in a distributed system happen all the time. This is where the CAP theorem comes in. Due to a network partition, a set of nodes might get disconnected from other nodes in the cluster and they cannot tell if the other nodes crashed, are unresponsive due to CPU overload, or the network went down.
In this scenario, a strategy has to be in place to decide which part of the cluster should be alive and which part has to be shut down to keep things consistent. The nodes can either take this decision themselves or be managed by an external coordinator. This problem of network partition in distributed systems is commonly known as the split-brain problem.
Typically the nodes are aware of each other in a cluster with the help of a cluster coordinator that tracks the status of the nodes by sending periodic heartbeat messages to all the nodes in the cluster.
In case a split-brain issue arises, there are a few strategies that are leveraged to tackle this situation. Also, these are not specific to the actor model deployment but are rather applicable to distributed systems in general:
Static quorum
In this approach, if the number of nodes on one side of the partition is greater than or equal to the configured quorum size, the nodes on the other side of the partition get killed. This strategy works well when the cluster has a fixed number of nodes.
For instance, in an 11-node cluster, we can define the quorum size as 6. In case of a network partition, the nodes on the side of 6 will survive and the rest will be killed. However, if the nodes are split in a way where no side has the majority, this raises the risk of the entire cluster being terminated. This is a corner case and the deployment team needs to be aware of this.
Keep majority
In this approach, as opposed to a quorum size, the nodes on the majority side are retained and the rest are killed. The approach is helpful when the cluster has a dynamic number of nodes and a static quorum size cannot be set. Again, this has a risk of the entire cluster being shut down when no side has the majority. The corner cases in these split-brain handling strategies have to be handled well.
Down all
This approach hits the system’s availability but retains consistency, as it shuts down all the nodes in case of a network partition and starts a fresh cluster. This approach is advisable only when the system’s consistency is a must since it will shut down large clusters even in the case of minor network failures.
Recommended read: Network file system – A distributed file system protocol
When the network partition happens across data centers, the best bet is to wait it out and, if required, get the situation handled by site reliability engineers.
If you found the content helpful, check out the Zero to Software Architect learning track, a series of three courses I have written intending to educate you, step by step, on the domain of software architecture and distributed system design. The learning track takes you right from having no knowledge in it to making you a pro in designing large-scale distributed systems like YouTube, Netflix, Hotstar, and more.
Well, this is pretty much it. If you found the content helpful, consider sharing it with your network for better reach. I am Shivang. You can read about me here.
I’ll see you in the next blog post. Until then, Cheers.


Follow Me On Social Media