
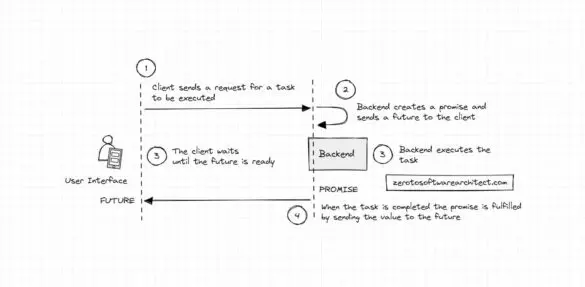
‘Futures and Promises’ – How Instagram leverages it for better resource utilization
Futures and Promises is a concept that enables a process to execute asynchronously, improving performance and resource consumption. It can be applied in multiple contexts, such as in request-response in a web service call, long-running computations, database queries, remote procedure calls, interservice communication in distributed...
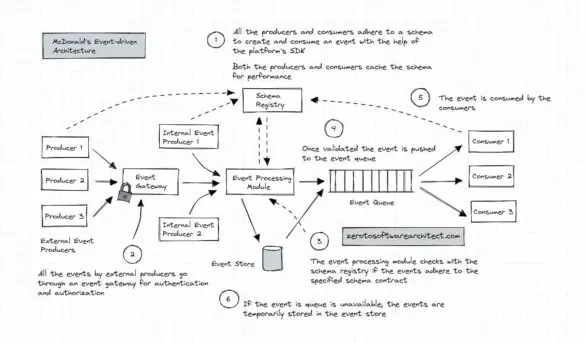
McDonald’s Event-Driven Architecture – A Gist
McDonald’s uses events across their distributed architecture for use cases such as asynchronous, transactional and analytical processing, including mobile-order progress tracking and sending marketing offers like deals and promotions to their customers. As opposed to building event streaming solutions for every individual or a set...
State of Backend #2 – Disney+ Hotstar Replaced Redis and Elasticsearch with ScyllaDB. Here’s Why.
To get the content delivered to your inbox, you can subscribe to the newsletter at the end of this post. Here is the previous issue. Disney+ Hotstar Replaced Redis and Elasticsearch with ScyllaDB to Implement the ‘Continue Watching’ Feature. Here’s Why: The continue watching feature...
State of Backend #1- Distributed Task Scheduling with Akka, Kafka and Cassandra
This is the first issue of the newsletter I’ve kickstarted for insights into the backend engineering space encircling topics like distributed systems, databases, data engineering, system design, architecture, scalability and the like, also the latest tools and technologies in the space. To get the content...
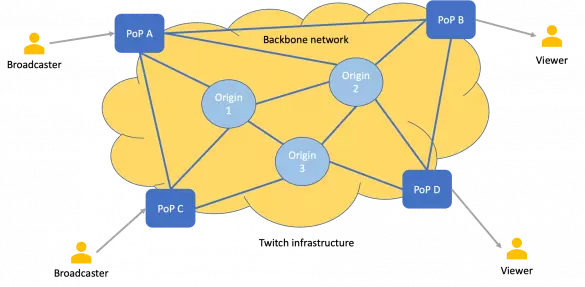
Live Video Streaming Infrastructure at Twitch
Twitch engineering developed a scalable, HA live streaming solution to enable broadcasters on their platform live stream their gameplay with minimum latency. The live streaming solution (developed by Twitch) is also made available as a Service to the world through AWS IVS (Interactive Video Streaming)...
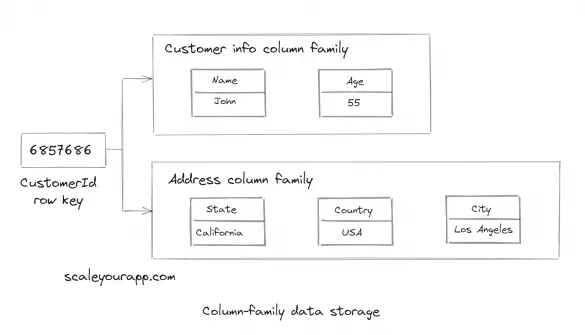
Wide-column Database, Column Databases – A Deep Dive
Wide-column, column-oriented and column-family databases belong to the NoSQL family of databases built to store and query massive amounts of data, aka BigData. They are highly available and scalable, built to work in a distributed environment. Most of the wide-column databases do not support joins...
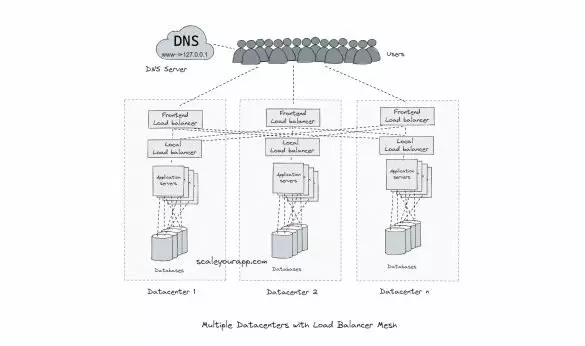
What Do 100 Million Users On A Google Service Mean? – System Design for Scale and High Availability
Imagine a simple service with an API server and a database. Now when this service is owned by Google, the traffic is expected to be in the scale of 100 million users. That means: 10 billion requests/day 100k requests/second (average) 200k requests/second (peak) 2 million...
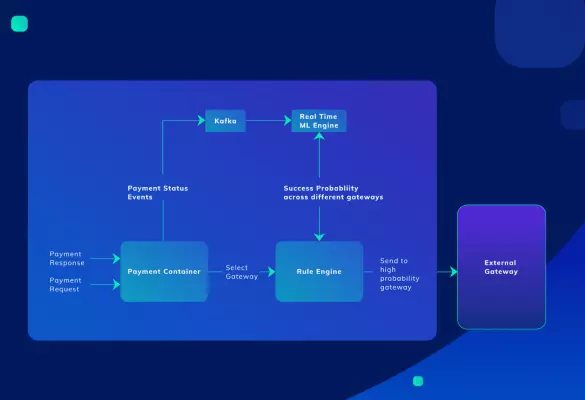
How Razorpay handled significant transaction bursts during events like IPL
Razorpay is India’s leading payment-gateway service that offers a suite of products to businesses to accept, process and disburse payments enabling them to establish an online presence. They dealt with an interesting problem: the problem of sudden transaction bursts during events such as the Indian...
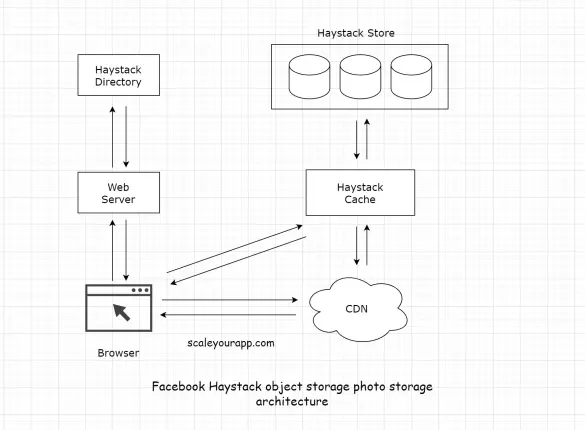
Facebook’s photo storage architecture
Facebook built Haystack, an object storage system designed for storing photos on a large scale. The platform stores over 260 billion images which amounts to over 20 petabytes of data. One billion new photos are uploaded each week which is approx—60 terabytes of data. At...
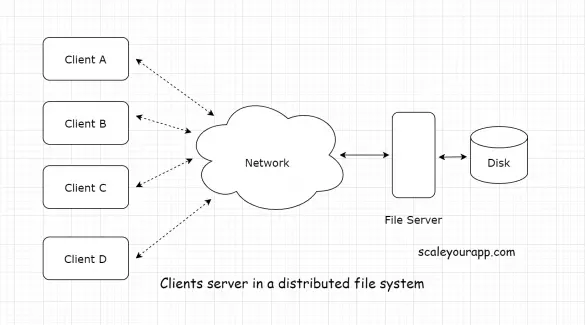
An Introduction to the Network File System (NFS)
The network file system is a distributed file system protocol. It’s an open protocol that specifies message formats on how a client and a server should communicate in a distributed environment. NFS being an open protocol enables third parties to write their own implementations of...
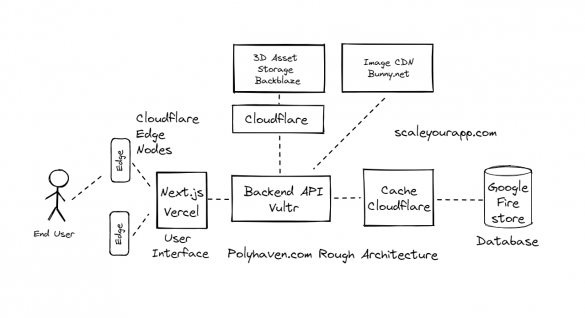
Application Hosting – How PolyHaven Manages 5 Million Page Views and 80TB Traffic a Month for < $400
Polyhaven, a 3D asset library, recently provided insightful data on how they manage to serve 5 million page views a month, consuming a bandwidth of 80 terabytes just under 400 USD. If the same amount of traffic was served from AWS S3 object storage, that would cost more than 4K USD a month. So how do...

Distributed Systems and Scalability Feed #1 – Heroku Client Rate Throttling, Tail Latency and more
What does 100 million users on a Google service mean? 10 billion requests/day100k requests/second (average)200k requests/second (peak)2 million disk seeks per second (IOPS) How are these served?100 million users need (at peak) 2 million IOPS at 100 IOPS per disk, that’s 20k disk drives at...


Follow Me On Social Media