
State of Backend #2 – Disney+ Hotstar Replaced Redis and Elasticsearch with ScyllaDB. Here’s Why.
To get the content delivered to your inbox, you can subscribe to the newsletter at the end of this post. Here is the previous issue.
Disney+ Hotstar Replaced Redis and Elasticsearch with ScyllaDB to Implement the ‘Continue Watching’ Feature. Here’s Why:
The continue watching feature is an essential part of any OTT streaming service that enables users to continue watching the videos they left off earlier. The feature also allows a user to pause a video on a certain device, say a laptop and resume it on their mobile right from where they left off.
Disney+ Hotstar streaming platform initially implemented the feature with the help of Redis, Elasticsearch and Kafka.
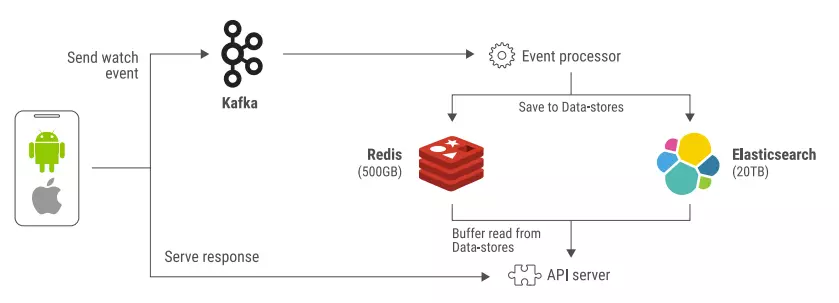
When a user watches a video, an event is triggered to Kafka, where it is processed and persisted in Redis and Elasticsearch. When the user navigates to the home page, the page displays the videos (fetching the data from Redis) that the user hasn’t completed yet.
The Redis cluster held 500 GB of data (ranging from 5 to 10 KB per event) and the Elasticsearch 20 TB.
Here are the data models for Redis and Elasticsearch:
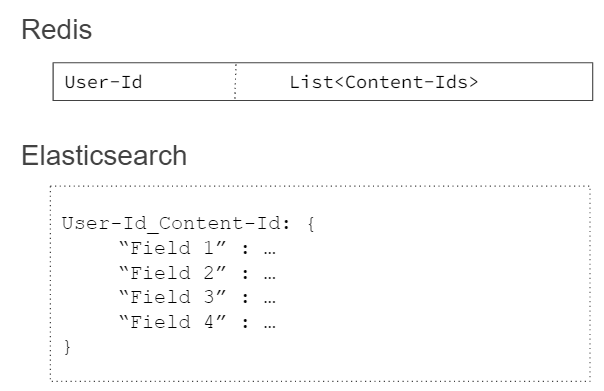
Though it isn’t explicitly stated in the article I am assuming on opening the home page the UI would fetch data from Redis which is a list of videos with their ids at very low latency.
And when the user would click on a certain video to watch, the UI would now send a request to Elasticsearch to fetch the video details such as the timestamp, streaming resolution set explicitly by the user, etc.
The Issue With this Architecture
The Hotstar engineering team had to work with two different data models (Redis: Key-value, Elasticsearch: Document) for the feature. This led to scaling challenges. It became increasingly difficult and costly to manage the data; their data doubled every six months, and both Redis and Elasticsearch clusters had to be scaled separately. This required a lot of maintenance and manual effort.
Also, the Elasticsearch search latency was quite high (upto 200 milliseconds) compared to Redis.
Disney+ Hotstar users watch an average of 1 billion minutes of video every day. The platform processes approx. 100 to 200 GB of data daily to ensure the “Continue Watching” feature works accurate for the users.
For this, they needed a database that could handle write-heavy workloads (what Cassandra specializes in). Besides this, they also needed a scalable solution that could scale as the request volume increased by 10 to 20 times in a minute.
Hotstar eventually picked ScyllaDB (Database-as-a-Service) to work with one data model (wide-column) having two tables.

The User Table stores the list of videos that need to be populated in the continue watching section of the UI. And the User-Content Table holds the details of those videos.
The transition enabled them to achieve sub-millisecond latencies while the engineering team was off the hook of infrastructure administration tasks.
Why Not Cassandra?
ScyllaDB is an open source NoSQL wide-column data store designed to achieve higher throughputs and lower latencies than Cassandra (performance benchmark).
Best Practices Of Preparing Your Monolith for Transition to Microservices
An informative article by Semaphore lists different ways to make the transition from a monolith to a microservice architecture as smooth as possible, including using monorepos, feature flags, automated tests (unit, integration, acceptance), building a test pyramid, using HTTP reverse proxies and API Gateway to segregate the traffic.
Monorepos
A monorepo is a code repository containing multiple projects (which may or may not be related) run by different teams. Several big tech leverage the monorepo approach, such as Google, Facebook, Twitter, Microsoft, Uber, etc.
Google stores billions of lines of code in a single repository using a homegrown version-control system. Its codebase includes approx. one billion files with a history of approx. 35 million commits.
Each day the repo serves billions of file read requests with approx 800K QPS during peak traffic and at an average of 500K QPS on any regular day.
Facebook’s monorepo is many times larger than the Linux Kernel, with thousands of commits a week across hundreds of thousands of files.
A couple more instances: Working with a monorepo at Microsoft. Uber moved from a monorepo to multi repos and back.
Monorepos and Multirepos lead to different development workflows in organizations. Some prefer to stick with monorepos; others do not, as the monorepo approach has both pros and cons.
Monorepos increase the code visibility across teams. This leads to better collaboration and cross-team development. Dependency management gets simpler. It’s easy to enforce code quality standards when all the code sits in one place. In a single commit, a developer can update several modules or projects.
At the same time, as the size of the monorepo grows, management becomes hard; the performance of git commands and IDE slumps. Testing the whole repo with every code commit becomes challenging. If the master breaks, every team gets impacted. Maintaining ownership of files becomes complicated and such. So, as always, there is no silver bullet.
One might pick the approach (monorepo or multi repo) based on their use case.
Here is a website that lists the right tools to work with monorepos.
IDE-style Auto Complete For Your Terminal
Fig (open-source) adds IDE-style autocomplete to your existing terminal to help you move faster. It works with your current terminal and shell, loading up once and staying entirely local. Supports 300+ CLI tools.
Azure Static Web Apps Service Lets You Go From Code Commits to Global Deployment In No Time
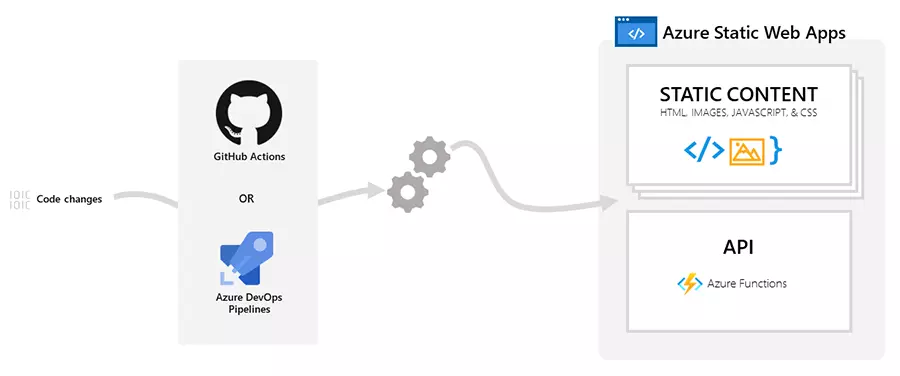
Static Web Apps is an Azure service that automatically builds and deploys static apps to Azure from a code repository based off code changes.
{kind=link}
Azure interacts directly with GitHub to monitor a certain branch and every time it has a commit, a build is automatically run and changes are deployed to Azure. With this service, static resources are separated from the web app and served from edge points across the world via a serverless API which cuts down latency significantly.
If you’ve found the content interesting, consider subscribing to my newsletter to get the latest content delivered right to your inbox.



Follow Me On Social Media