
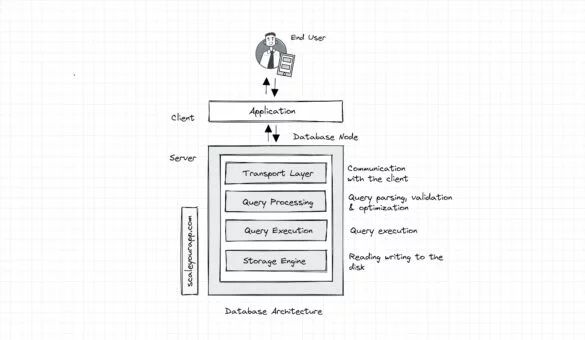
Database Architecture – A Deep Dive – Part 1
This article is a deep dive into the internal architecture of databases/DBMS (Database Management Systems). I’ll begin with a standard architecture relational databases have; will then take a peek into the architectures of a couple of real-world SQL databases and then, in the subsequent articles,...
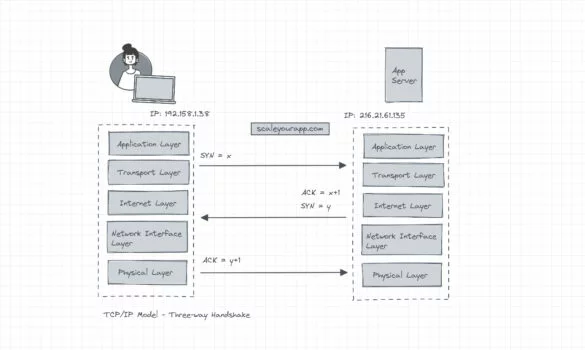
IP layers and the TCP/IP model – A deep dive
This blog post takes a deep dive into the intricacies of communication over the web with the IP (Internet Protocol), its layers involved and the TCP/IP protocol suit. By the end of the post, you’ll have a good insight into how machines communicate/exchange data over...
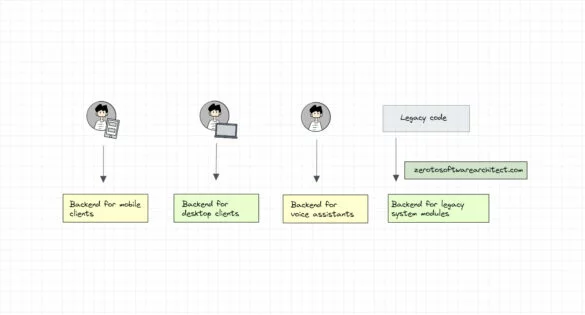
Leveraging the Backends for frontends pattern to avert API gateway from becoming a system bottleneck
In this system design series, I discuss the intricacies of designing distributed scalable systems and the related concepts. This will help you immensely with your software architecture and system design interview rounds, in addition to helping you become a better software engineer. Here is the first post...
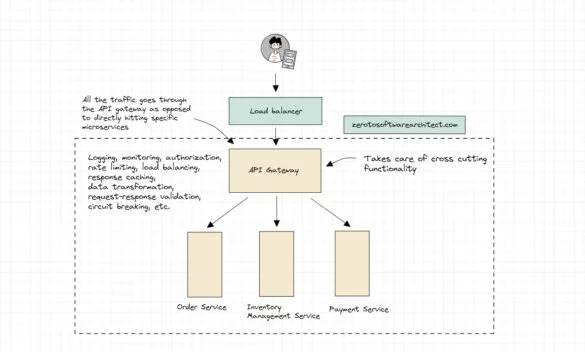
Understanding API Gateway and the need for it
In this system design series, I discuss the intricacies of designing distributed scalable systems and the related concepts. This will help you immensely with your software architecture and system design interview rounds, in addition to helping you become a better software engineer. Here is the first...
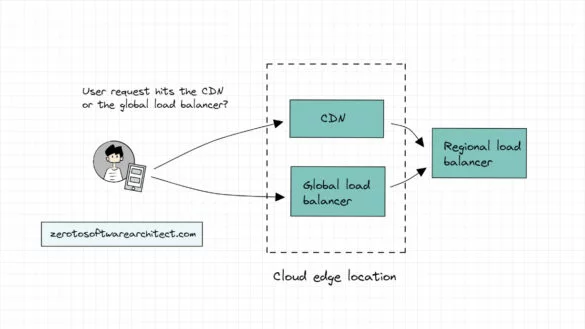
CDN and Load balancers (Understanding the request flow)
In this system design series, I’ve started on this blog, I discuss the intricacies of designing distributed scalable systems and the related concepts. This will help you immensely with your software architecture and system design interview rounds, in addition to helping you become a better...
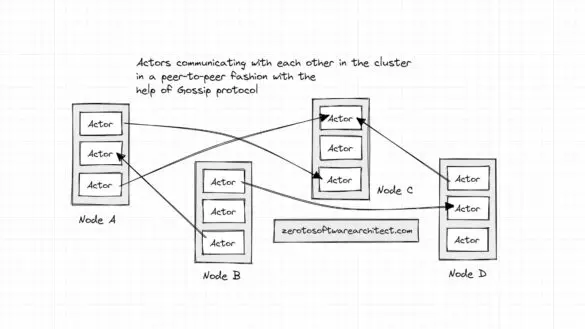
How Actor model/Actors run in clusters facilitating asynchronous communication in distributed systems
This blog post is a continuation of my previous post, in the system design series, on understanding the actor model to build non-blocking, high-throughput distributed systems. If you haven’t read it, I suggest giving it a read. Various Actor model frameworks, like Akka, ProtoActor, Actix,...
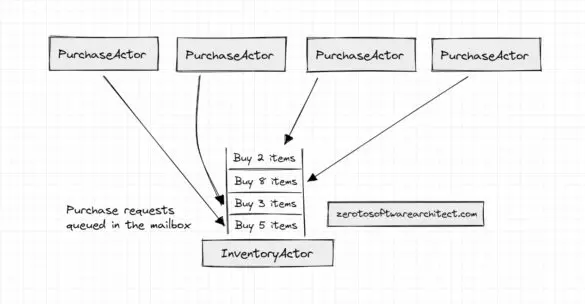
Understanding the Actor model to build non-blocking, high-throughput distributed systems
This is the fourth post in the system design series where I discuss the intricacies of designing distributed scalable systems and the related concepts. This will help you immensely with your software architecture and system design interview rounds, in addition to helping you become a better...

Technical Consultant: How can I become one? Explained with an example
This write-up offers insight into technical consulting. You’ll understand what a technical consultant is, the skills required to be one and how you can become one. So, without further ado. Let’s get started. What is a technical consultant? A technical consultant, an IT consultant or...

IT consultant: How do I become one? Explained with a real-world use case
This article takes a deep dive into the world of IT consulting. I’ll discuss what an IT (Information Technology) consultant is, their responsibilities, the skills required, how you can become one and more. So, without further ado. Let’s get started. What does an IT consultant...
Software architecture course – From zero to mastering the fundamentals
If you are looking for a course on software architecture that’ll help you get a grip on the domain. Let me tell you about the Zero to Mastering Software Architecture learning track that I’ve authored, consisting of three courses that helps you learn the domain...
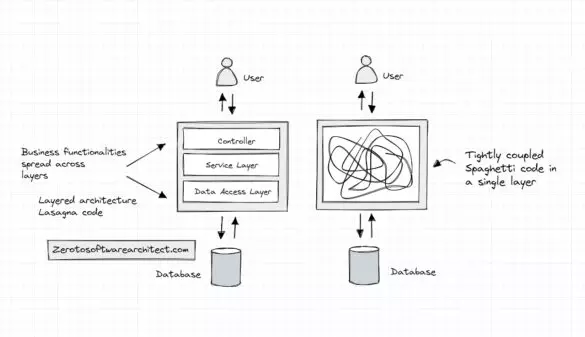
Spaghetti code explained with a real-world use case
What is the Spaghetti code? Spaghetti code also referred to as the big ball of mud, is code without a definite structure and resembles spaghetti. This form of code is tightly coupled, hard to maintain, and refactor and a nightmare for the devs working on...
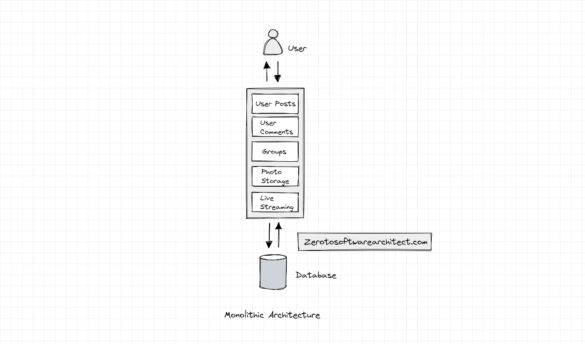
Monolithic architecture simplified
This write-up takes a deep dive into monolithic architecture. We will understand what it is and why implement it. What is monolithic architecture? An application has a monolithic architecture if it contains the entire application code in a single codebase. A monolithic application is a...


Follow Me On Social Media