
{kind=link}
Database Architecture – Part 2 – NoSQL DB Architecture with ScyllaDB (Shard Per Core Design)
In the first post of database architecture, I discussed the internal architecture of databases/database management systems, taking a peek into the architectures of MySQL and CockroachDB databases.
In another article, a continuation of that article, I discussed how modern cloud servers run parallel compute to crank out maximum efficiency from the underlying hardware and how large-scale distributed services leverage those architectures to scale. Parallel processing architectures are critical to understanding the internals of NoSQL databases.
In this article, I discuss the internal architecture of NoSQL databases, taking a peek into the ScyllaDB shard per core architecture.
With that being said. Let’s get started.
NoSQL Database Architecture
Different NoSQL databases have different architectures to address varying workload requirements. Check out part one of database architecture to read more on this.
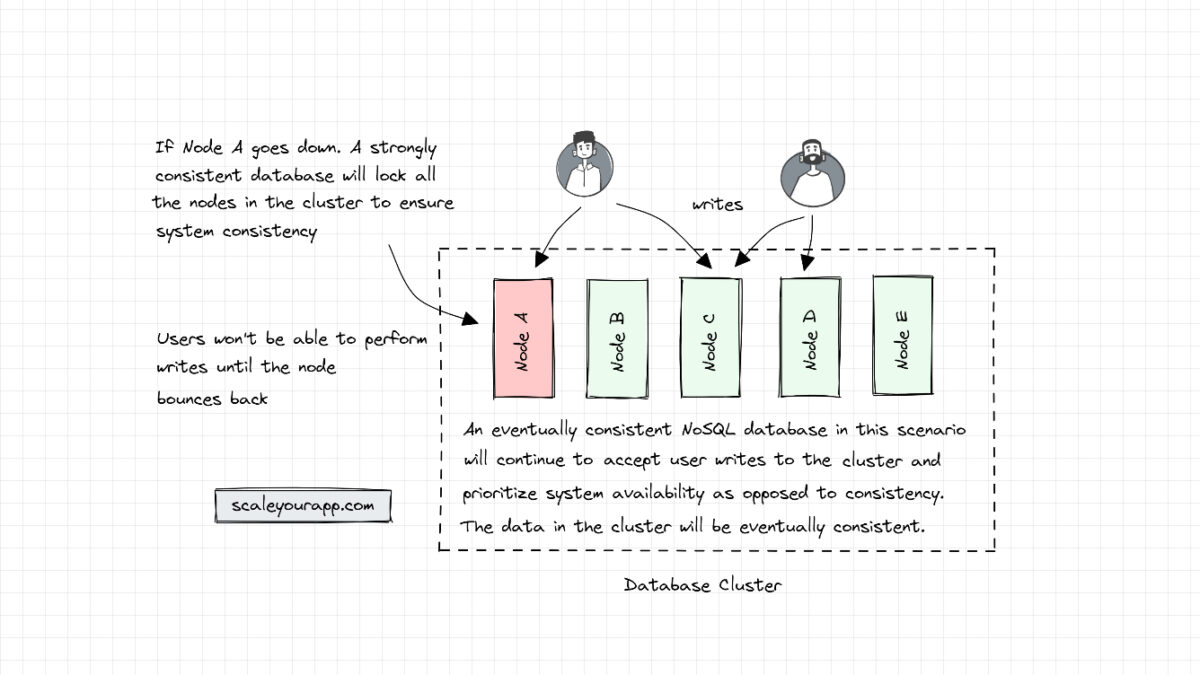
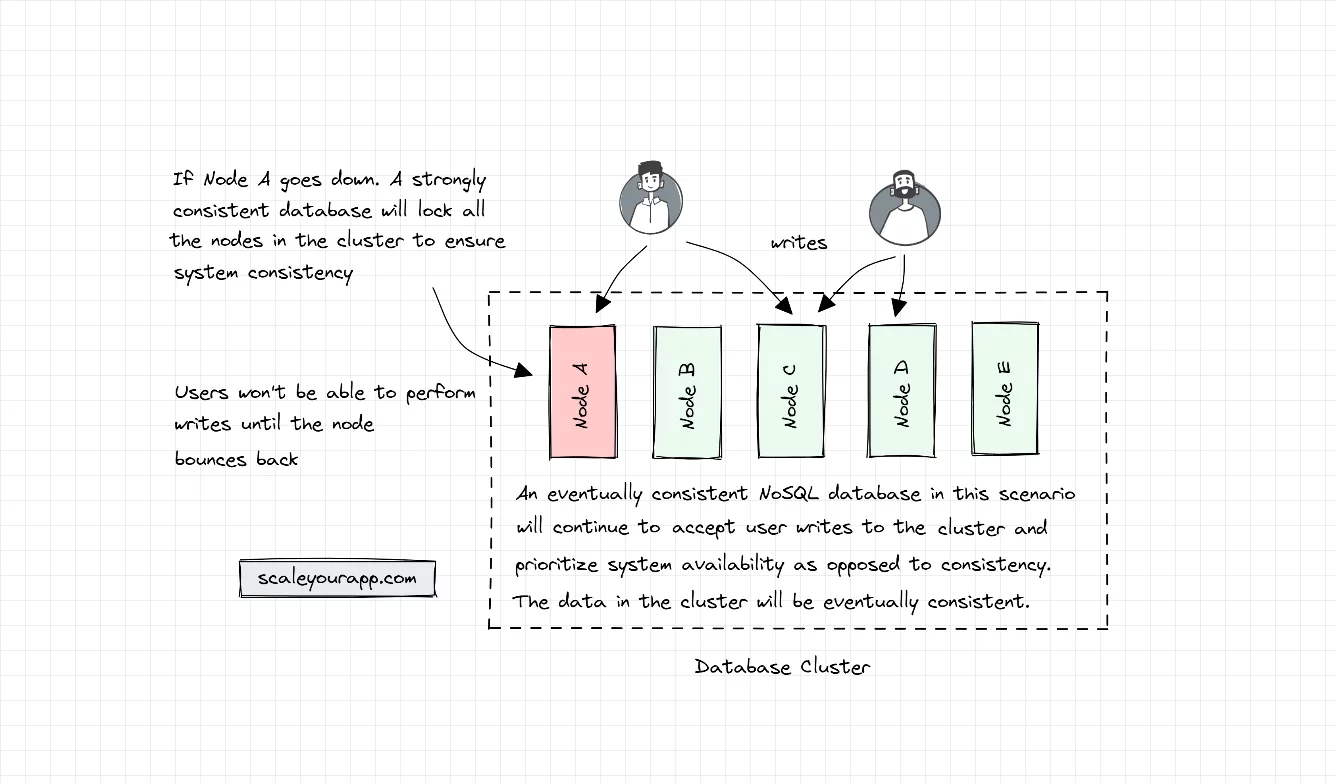
The most prominent difference between SQL and NoSQL databases is NoSQL databases are horizontally scalable on the fly. This is primarily because they favor availability over consistency (CAP Theorem). In contrast, SQL databases, supporting strongly consistent ACID transactions, prioritize consistency over availability. They lock the nodes in the cluster to maintain a consistent state at any point.
If you wish to master databases, get a fundamental understanding of concepts like relational and non-relational databases, when to pick which, eventual consistency, strong consistency, different types of databases (relational, document-oriented, key-value, wide-column, graph, etc.), what use cases fit them, how applications and databases handle concurrent traffic, how we manage database growth dealing with petabytes of data, how they manage data consistency when deployed in different cloud regions and availability zones around the globe and much more, check out the Zero to Software Architecture Proficiency learning path I’ve authored. I wish I had something similar to learn from in the initial years of my career.
Let’s look at ScyllaDB’s architecture to understand how it facilitates high-write throughputs with its shard per core design.
ScyllaDB Shard Per Core Architecture
ScyllaDB is written in C++ based on its underlying Seastar framework. It has a highly asynchronous, shared-nothing design and is optimized for modern cloud multiprocessor multicore NUMA cloud hardware to run millions of operations per second at sub-millisecond average latencies.
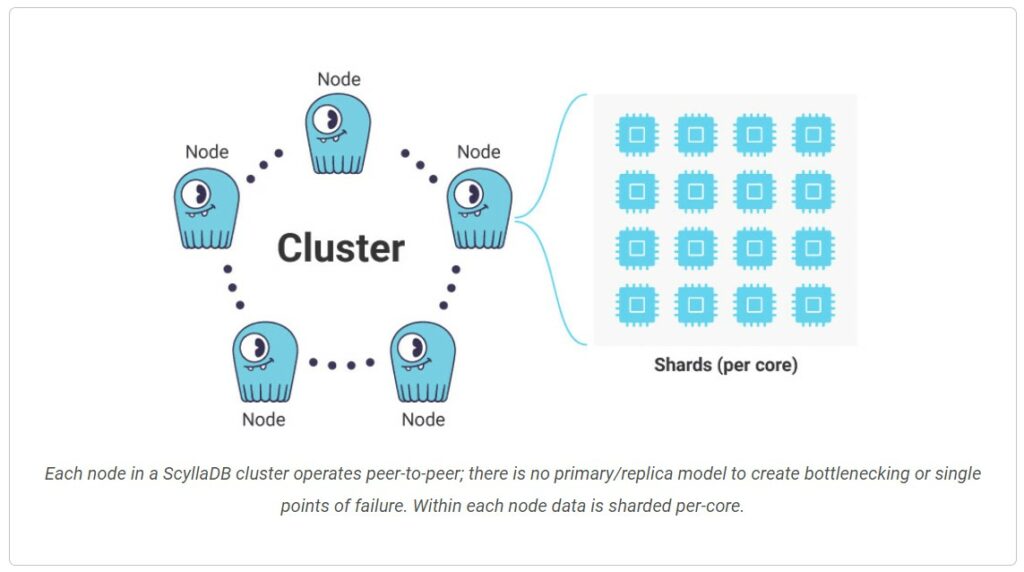
In this architecture, individual database shards are assigned to dedicated CPU cores. The data in a node is split into shards and every shard is allotted a dedicated CPU core, RAM, disk and other resources following a shared-nothing design. This facilitates parallel processing and reduces data contention amongst CPU cores since every shard has a dedicated CPU core. Resource-hungry queries of a certain shard cannot impact other cores. This results in better resource utilization and a notable improvement in query performance and throughput.
The Need For Shared Nothing Design In Cloud Instances
In the current state of cloud compute hardware, the performance increases on the clock speeds of individual CPU cores have hit the cap.
Clock speed is the number of cycles a CPU completes in one second. Each clock cycle equates to a unit of work a CPU can perform. So, the higher the clock speed, the more performant a CPU is.
There is a limit to which the clock speed can be notched up due to heat generation, physical hardware limitations and other reasons.
Thus, to increase the performance of a system, multiple cores are used in conjunction to execute tasks parallelly. This requires locking and coordination amongst the cores, which causes contention and bottlenecks.
To tackle this, ScyllaDB maps shards to individual cores with dedicated RAM, disk, etc., to avoid contention. The data between the CPU cores is passed via explicit message passing as opposed to sharing common memory.
How Are Shards Assigned to CPU Cores?
Assigning shards to cores involves careful planning to ensure optimal utilization of the cluster resources. For this, the cluster compute consumption is monitored and analyzed, which involves monitoring CPU utilization, memory and disk usage, network bandwidth consumption, etc.
This helps us determine what cores in certain nodes have the available bandwidth and what data can be assigned to them.
Besides this, dynamic load balancing is leveraged to evenly distribute shards across CPU cores based on resource availability. If the cores’ compute utilization hits the cap, more nodes get added to the cluster.
The database queries are designed keeping the underlying cluster architecture in mind. Simulating production traffic and benchmarking helps identify the bottlenecks in the system. To ensure smooth execution, the cluster is continually monitored and alerts are put in place if a certain core or a number of them face performance issues.
Operating systems and container orchestrators allow specific processes to be processed by specific CPU cores via affinity settings. I’ll discuss this in a separate article.
When a query hits a database node, the DB query planner figures out the right shard or shards to which the query needs to be sent. Once the shard is determined, the query is processed by the CPU cores mapped to those shards.
Mapping shards to CPU cores is a complex task that requires a deep understanding of the underlying infrastructure, distributed systems, workload requirements, query optimization and resource requirements.
If you found the content helpful, I run a newsletter called Backend Insights, where I actively publish exclusive posts in the backend engineering space encompassing topics like distributed systems, cloud, application development, shiny new products, tech trends, learning resources, and essentially everything that is part of the backend engineering realm.
Being a part of this newsletter, you’ll stay on top of the developments that happen in this space on an ongoing basis in addition to becoming a more informed backend engineer. Do check it out.
Folks, this is pretty much it. I’ll continue writing about the internal architectures of different databases in future posts. If you found the content helpful, consider sharing it with your network for more reach.
I am Shivang. You can read about me here. I’ll see you in the next post.
Until then. Cheers!


Follow Me On Social Media