
{kind=link}
In this blog post, I explore Slack’s real-time messaging architecture with a discussion on the architectural and system design concepts they leverage to scale and keep the latency low.
The study will help us understand the intricacies of real-world web-scale architectures, enhancing our system design knowledge notably.
With that being said, let’s get started.
Slack’s Real-time Messaging Architecture
Slack sends millions of messages daily across millions of channels in real-time across the world. A Slack channel serves as a dedicated space for communication and collaboration among team members. Channels in Slack can be created for any project, topic or team.
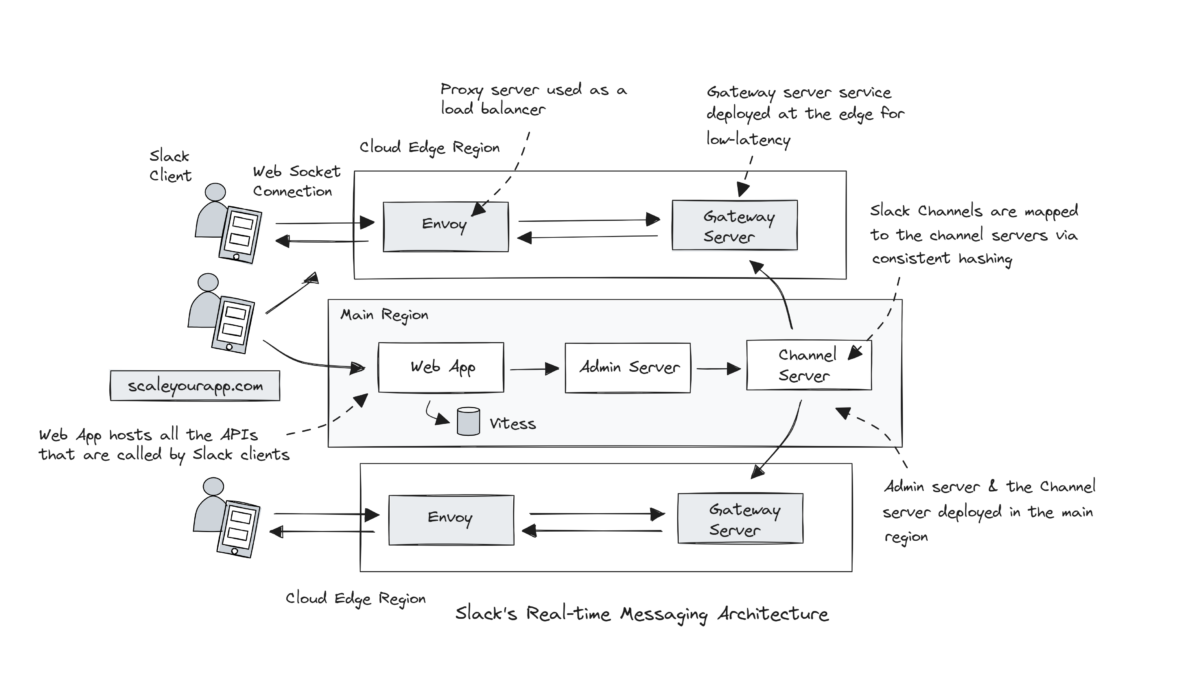
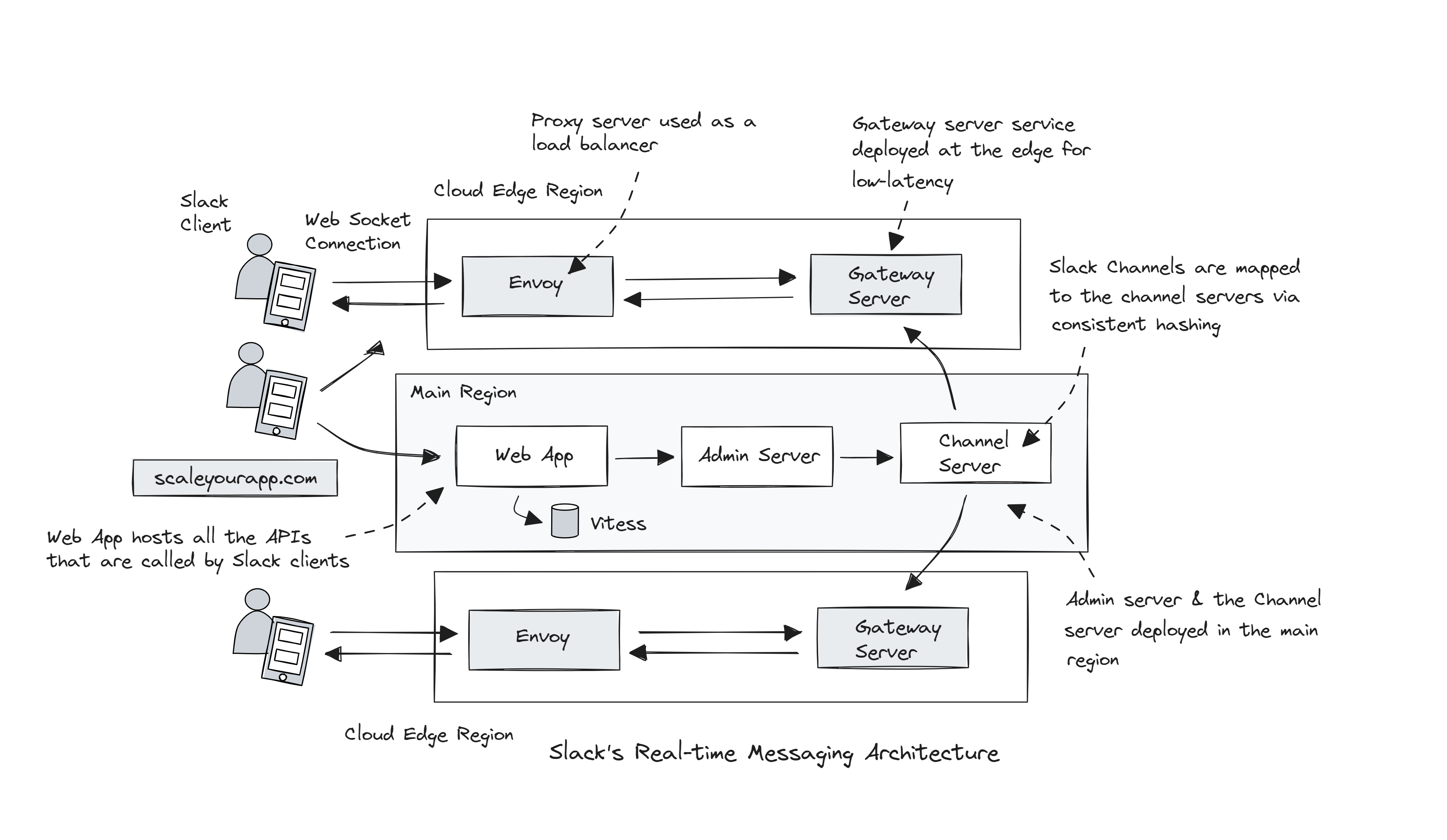
The core Slack services, aka Servers, are written in Java. They are Channel Servers, Gateway Servers, Admin Servers and Presence Servers.
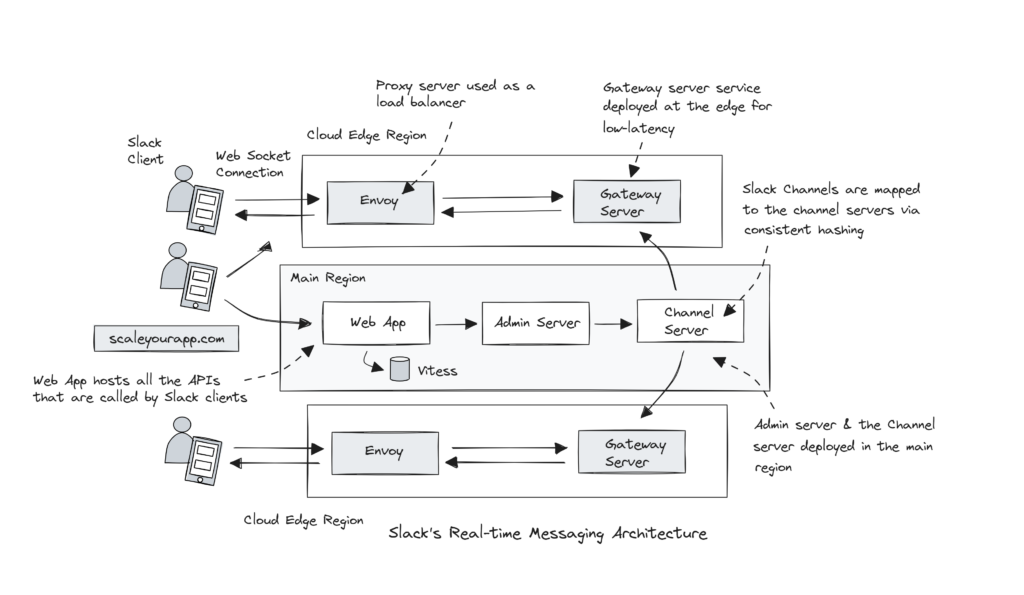
Image src: Slack
Channel Servers
Slack’s Channel Servers (CS) are stateful and in-memory. They hold channel information in-memory. Every Channel Server is mapped to a subset of Slack channels based on consistent hashing. At peak times, approx. 16 million channels are served per host.
The channel ID is hashed and mapped to a unique server. Every Channel Server host receives and sends messages for the respective mapped channels.
Consistent hash ring managers manage the consistent hash ring for the Channel Servers. They replace the unhealthy Channel Servers pretty quickly with the new Channel Server ready to handle traffic within 20 seconds.
Two key things to note here:
1. The Channel Servers are stateful. They hold channel information in-memory. Why stateful and in-memory? Isn’t this a scalability bottleneck? If a Server node handling a certain client request with their specific information stored in-memory goes down, other cluster nodes can’t replace that node without the client realizing that the server went down.
2. The traffic is routed to different Channel Server nodes via consistent hashing.
Let’s discuss the first point.
Stateful Services
Slack Channel Servers hold channel information in-memory and are stateful to deliver messages to clients quickly and efficiently. Since the backend servers store the channel information in-memory, they don’t have to poll any external storage like a database to fetch information on every client request. This enables the service to quickly return the response to the clients, keeping the latency low.
Yes, this introduces some scalability challenges, such as since the information is stored in-memory, the need for augmenting the internal server memory arises as the channels and the clients increase over time. This makes scaling horizontally challenging. In addition, each Channel Server node is vulnerable to failures and data loss. If the node goes down, there is a risk of the client data being lost.
This is a tradeoff Slack was willing to make to keep the latency low. However, not much information is given in the article on how they avert data loss, whether they use replication, take instance data backups, or use persistence storage plugged with the instances.
Leveraging Managed Cloud Services
If a business leverages managed services of a public cloud platform, the platform handles replication, backups and other necessary tasks to keep the service running, enabling the business to focus on building features as opposed to managing its infrastructure. This is the primary reason web-scale services migrate their infrastructure to public cloud platforms.
Relevant Reads:
Twitter moved a part of their workload to the Google Cloud to free their resources of the effort that went into managing the on-prem infrastructure at the Twitter scale.
Evernote Engineering originally managed their on-prem servers and network. But with the increasing popularity of the business, scaling the infrastructure, maintenance and upgrade became challenging. To focus on innovation and avert investment of resources in infra management, they migrated to Google Cloud.
Picking the Right Cloud Instance
Running in-memory memory-intensive operations ideally requires us to pick memory-optimized cloud instances. Memory-optimized instances provide a higher amount of RAM than other instance types.
Cloud platforms provide different instances, such as storage-optimized, compute-optimized, memory-optimized, regular instances and such. Based on the use case requirements and resource usage patterns, we can pick the fitting one.
Profiling, running performance tests and continuous monitoring of our stateful services help us understand the resource utilization patterns, including memory, storage and CPU consumption.
Plugging Persistent Storage to the Instances
Along with a memory-optimized instance, we can also pick a persistence storage that we can attach to our cloud instance. Persistent storage ensures data availability and durability across system reboots, application restarts and hardware failures.
Cloud providers provide persistent storage options such as AWS EBS (Elastic Block Storage), Azure Disk Storage and Google Cloud Persistent Disk to provide reliable and scalable storage for stateful services.
Stateless and stateful are two common architectural patterns for designing microservices. It’s relatively easy to scale stateless microservices in contrast to stateful. Stay tuned for my next blog post, where I’ll discuss scaling stateful microservices.
Mapping Slack Channels to Channel Servers Based On Consistent Hashing
Every Channel Server is mapped to a subset of channels based on consistent hashing, and the hash ring managers manage the consistent hash ring.
Consistent hashing is a technique that is used to distribute data or traffic across a cluster of servers, ensuring minimum data rebalancing across the cluster nodes when a few nodes go down or are added to the cluster. This becomes vital for applications that need to scale up or down based on frequently changing traffic, like in a real-time messaging app.
Slack uses consistent hashing to route channel messages to different nodes in the cluster. Each channel has a unique ID, which is used as a key to hash to assign the channel to a unique node in the cluster. This ensures the messages for a given channel are handled by the same server, ensuring consistency and minimal network consumption.
If we do not use consistent hashing and rather just regular hashing, adding or removing a few server nodes in the cluster would require recalculating hashes of all the channels. This would require a lot of data to be rebalanced between servers and disrupt the service for the users.
Consistent hashing maps both the channels and the servers on a circular hash ring, using a hash function that produces a uniform distribution of values. To have a detailed read on consistent hashing, this is a good resource.
Consistent hashing is leveraged by popular databases like Cassandra, Couchbase, VoldemortDB and DynamoDB to manage data distribution amongst nodes in the cluster.
In addition, some of the web-scale services like Spotify uses consistent hashing to distribute the load of millions of users across their servers.
Akamai uses consistent hashing to map requests to the closest edge server in the CDN.
Pinterest uses consistent hashing to store and retrieve billions of pins and boards across their distributed database.
Discord uses consistent hashing to scale to 5,000,000 concurrent users.
Consistent hashing is a valuable technique for building highly available, scalable, fault-tolerant distributed systems.
Moving on to other core Slack services:
Gateway Servers
Gateway Servers service is the interface between Slack clients and Channel Servers service. They are deployed in multiple cloud regions nearest to the end user, enabling a Slack client to quickly connect to a Gateway Server in the nearest cloud region.
Gateway Servers are again stateful and in-memory, holding user information and web socket channel subscriptions.
Presence Servers
Presence Servers are in-memory tracking the online presence of users. This service powers the green presence dots in Slack clients. The users are hashed to individual Presence Servers.
Admin Servers
Admin Servers are the interface between the Slack web app backend and Channel Servers. They are stateless and in-memory.
Service Discovery
The Channel Servers are registered in a service discovery tool called Consul. Service discovery in distributed systems or microservices architecture facilitates automatically detecting other services in the network, facilitating scalable and resilient communication between them.
In a service cluster, nodes constantly scale up and down, and their IPs and other configurations change dynamically. Service discovery ensures all services can communicate with each other without manual configuration updation.
Slack registers its Channel Servers in service discovery to keep track of the location and availability of each node. It becomes easy to manage them during auto-scaling, failures and service upgrades.
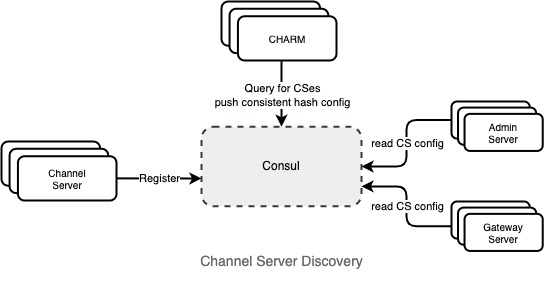
Image src: Slack
Establishing a Connection With the Backend
Every Slack client keeps a persistent connection with the backend via web sockets. Web sockets enables Slack client and the server to establish a low-latency, bi-directional communication. This makes the technology fitting for real-time apps like chat apps, online games, etc.
When the interaction between the client and the server is frequent, web sockets reduce the overhead of repeatedly establishing an HTTP connection. This helps with the reduced network bandwidth and other resource consumption. The data can be exchanged with lower latency than a regular HTTP connection being created and terminated repeatedly.
When initiating a request, the client fetches the user token and the web socket connection info from the Webapp backend. This backend, written in Hacklang, hosts all the APIs called by the Slack clients.
The information fetched from the Webapp backend includes the host names of the Gateway Server service and the token that authenticates the user to create a web socket connection.
After fetching the information, the client hits the Envoy proxy at the nearest edge region. The Edge proxy forwards the request to the Gateway Server, which fetches the user information, including all the user’s channels from the Webapp and sends the first message to the client.
The Gateway Server then subscribes to all the Channel Servers of the user based on consistent hashing. The connection is now ready to exchange messages in real time.
The Envoy proxy service is used as a load balancer for different services and TLS termination in this setup.
Two key things to observe here:
- Why is a proxy service being used as a load balancer?
- Why isn’t the Webapp deployed at the edge as opposed to being in the main region to cut down latency further?
Using Proxy Service as a Load Balancing Solution
Envoy is an open-source, high-performance, cloud-native proxy server originally developed by Lyft. Slack leverages it to handle millions of concurrent connections. It can dynamically adjust the load across a cluster of servers based on various metrics such as latency, availability, etc. and is designed for cloud-native applications and service mesh architectures.
It also supports web sockets, facilitating secure communication by performing TLS termination and encryption between the client and the server. In addition, it can integrate with Consul, the service discovery service.
Proxy services like Envoy can also be used as load balancers when there is a need to manage the incoming traffic in addition to providing additional proxy features such as caching, observability, security, etc.
If proxies can be used as load balancers, why implement dedicated load balancers?
Proxy servers aren’t an alternative to dedicated load balancers. They have distinct characteristics and use cases and offer varying features and performance levels.
For instance, if we need a proxy server in our system architecture and it can fulfill the load balancing requirements, we can deploy a proxy server to perform both functionalities.
In contrast, if we need a dedicated load balancer, we cannot replace it with a proxy service. It may not offer the range of features a dedicated load balancer has.
Why isn’t the Webapp deployed at the edge to cut down latency further?
The Webapp is not a performance-critical component of Slack’s architecture. Most real-time messaging and interaction happens through web socket connections, which are handled by the Gateway Servers. The service is deployed in the edge regions. Moving the Webapp to the edge would not significantly improve the user experience.
In addition, the Webapp interacts with other Slack’s core services that are deployed in the main region as well. Moving the Webapp to the edge would increase network latency between the Webapp and these services with an introduction in additional complexity and overhead for managing and synchronizing the data across multiple cloud regions.
Broadcasting Channel Messages to all Clients
Once the client establishes a secure web socket connection with the backend, each message sent in a channel is broadcast to all the online clients of the channel in real time.
The Webapp sends the channel message to the Admin Server service, an interface between the Webapp and the Channel Server service. The Admin Server, with the help of the channel ID, discovers the Channel Server via the consistent hash ring and routes the messages to that Channel Server.
The Channel Server sends out the message to every Gateway Server in different cloud regions subscribed to the channel. And the Gateway Server, in turn, pushes that message to every client subscribed to that Slack channel.
Key System Design Learnings from this Real-time Messaging Architecture Case Study
Microservices architecture helps with independent service development, management and deployments. The Gateway Servers are deployed in the edge regions, whereas the Webapp and the Channel Servers are deployed in the main region. In addition, based on the requirements, some services are stateless and others stateful.
Every Server has a dedicated responsibility and is implemented as a microservice that helps Slack scale individual Servers based on specific service requirements and allocate resources (infrastructure and engineering) based on the service demand.
This helps with agility and flexibility in feature development and maintenance. Teams in the organization can own specific services, make changes to them, test, debug and deploy quicker without stepping on each other’s feet.
In addition, if a certain Server faces issues or downtime, it doesn’t impact other Slack Servers. This helps with the system availability, resilience and fault tolerance.
Though microservices are not the solution to every architectural scalability problem, tradeoffs are involved when picking the right architecture (microservices, monolithic, modular monolith, hexagonal architecture, etc).
When implemented, microservices bring along a lot of architectural and maintenance complexity, such as inter-service communication, service discovery, distributed system management, and so on. Monolith architecture in contrast is relatively simple to work with.
Picking the right architecture requires a thorough application use case analysis. There is no silver bullet.
Different categories of cloud instances (storage-optimized, compute-optimized, memory-optimized, etc.) can be leveraged along with their add-ons as per the fitting use case.
Consistent hashing helps with the data or traffic distribution across a cluster of servers, ensuring minimum data rebalancing across the cluster nodes. The technique is used by a bunch of web-scale services and distributed systems to scale.
A proxy server can also be leveraged as a load balancer, given we already use it in our architecture for the proxy server use cases, and it fulfills the application load balancing requirements. This cuts down the complexity of managing a proxy server with a dedicated load balancer.
Persistent connections reduce the overhead of repeatedly establishing HTTP connections between the client and the server if their interaction is frequent and lasts long.
With multi-regional cloud deployments, edge deployments are leveraged to minimize the latency as much as possible.
If you wish to take a deep dive into the fundamentals of designing a large-scale service, I have discussed all these concepts and more in my Zero to Software Architecture Proficiency learning path comprising three courses I have authored intending to educate you, step by step, on the domain of software architecture, cloud infrastructure and distributed system design.
This learning path offers you a structured learning experience, taking you right from having no knowledge on the domain to making you a pro in designing web-scale distributed systems like YouTube, Netflix, ESPN and the like. Check it out.
If you found the content helpful, I run a newsletter called Backend Insights, where I actively publish exclusive posts in the backend engineering space encompassing topics like distributed systems, cloud, application development, shiny new products, tech trends, learning resources, and essentially everything that is part of the backend engineering realm.
Being a part of this newsletter, you’ll stay on top of the developments that happen in this space on an ongoing basis in addition to becoming a more informed backend engineer. Do check it out.
Related read: Facebook Real-time Chat Architecture Scaling With Over Multi-Billion Messages Daily
Information source: Slack real-time messaging architecture.
Enhance your distributed systems knowledge and system design skills with these resources.
I am Shivang. Here is my X and LinkedIn profile. Feel free to send me a message. If you found the content helpful, consider sharing it with your network for more reach.
I’ll see you in the next post. Until then, Cheers!


Follow Me On Social Media