
Instagram architecture & database – How does it store & search billions of images
Instagram is the most popular photo-oriented social network on the planet today. With over a billion users, it has become the first choice for businesses to run their marketing campaigns on.
This write-up is a deep dive into its platform architecture and addresses questions like what technologies does it use on the backend? What are the databases that the platform leverages? How does it store billions of photos serving millions of QPS (Queries per second)? How does it search for content in the massive data it has? Let’s find out.
Distributed Systems
For a complete list of similar articles on distributed systems and real-world architectures, here you go
1. What technology does Instagram use on the backend?
The server-side code is powered by Django Python. All the web and async servers run in a distributed environment and are stateless.
The below diagram shows the architecture of Instagram:
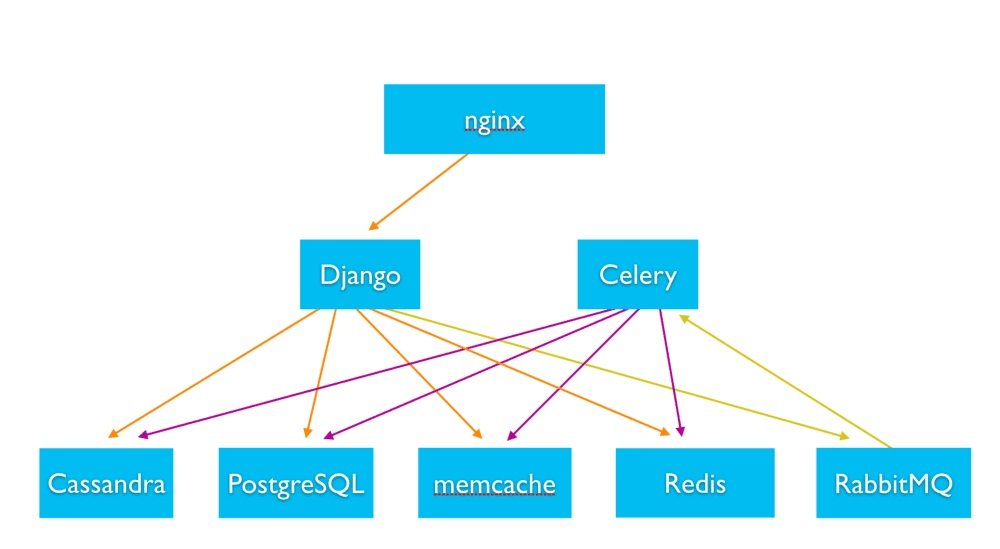
The backend uses various storage technologies such as Cassandra, PostgreSQL, Memcache, and Redis to serve personalized content to the users.
Asynchronous Behavior
RabbitMQ and Celery handle asynchronous tasks such as sending notifications to the users and other system background processes.
Celery is an asynchronous task queue based on distributed message communication, focused on real-time operations. It supports scheduling too. The recommended message broker for celery is RabbitMQ.
RabbitMQ, on the other hand, is a popular open-source message broker written using the AMQP Advanced Messaging Queuing Protocol.
Gearman is used to distribute tasks across several nodes in the system and for asynchronous task handling such as media uploads, etc. It’s an application framework for distributing tasks to other machines or processes that are more fit to execute those particular tasks. It has a gamut of applications ranging from highly available websites to the transport of database backup events.
Computing Trending HashTags On The Platform
The trending backend is a stream processing application that contains four nodes/components connected linearly.
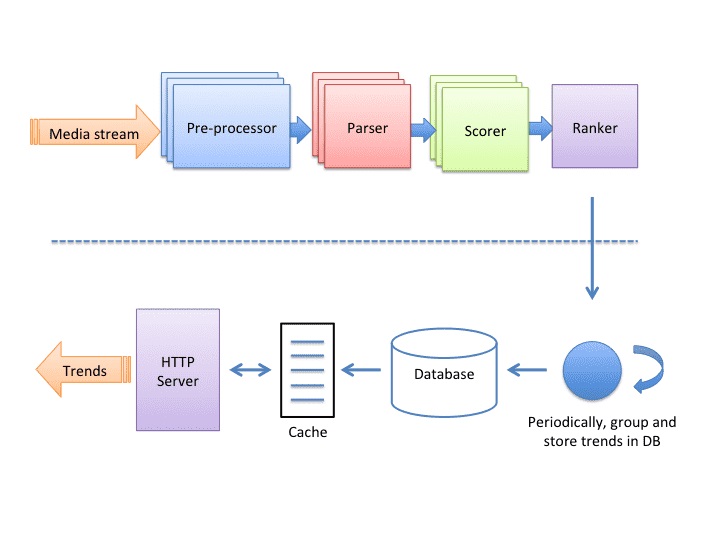
The role of the nodes is to consume a stream of event logs and produce the ranked list of trending content i.e. hashtags and places.
Pre-processor Node
The pre-processor node attaches the necessary data needed to apply filters on the original media that has metadata attached to it.
Parser Node
The parser node extracts all the hashtags attached to an image and applies filters to it.
Scorer Node
The scorer node keeps track of the counters for each hashtag based on time. All the counter data is kept in the cache, also persisted for durability.
Ranker Node
The role of the ranker node is to compute the trending scores of hashtags. The trends are served from a read-through cache that is Memcache and the database is Postgres.
Databases Used @Instagram
PostgreSQL is the primary database of the application, it stores most of the data of the platform such as user data, photos, tags, meta-tags, etc.
As the platform gained popularity and the data grew huge over time, the engineering team at Insta meditated on different NoSQL solutions to scale and finally decided to shard the existing PostgreSQL database as it best suited their requirements.
To get a deeper insight into distributed databases like how they handle concurrent traffic, data growth and such, check out my distributed systems design course – Design Modern Web-Scale Distributed Applications Like a Pro
Speaking of scaling the database via sharding and other means, this article YouTube database – How does it store so many videos without running out of storage space? is an interesting read.
The main database cluster of Instagram contains 12 replicas in different zones and involves 12 Quadruple extra large memory instances.
Hive is used for data archiving. It’s a data warehousing software built on top of Apache Hadoop for data query and analytics capabilities. A scheduled batch process runs at regular intervals to archive data from PostgreSQL DB to Hive.
Vmtouch, a tool for learning about and managing the file system cache of Unix and Unix-like servers, is used to manage in-memory data when moving from one machine to another.
Using Pgbouncer to pool PostgreSQL connections when connecting with the backend web server resulted in a huge performance boost.
Redis an in-memory database is used to store the activity feed, sessions and other app’s real-time data.
Memcache an open-source distributed memory caching system is used for caching throughout the service.
If you want to master databases and distributed system design, check out the Zero to Software Architecture Proficiency learning path comprising three courses that help you understand distributed system design, with detailed discussions on various system components and concepts starting right from zero.
Data Management in the Cluster
Data across the cluster is eventually consistent, cache tiers are co-located with the web servers in the same data center to avoid latency.
The data is classified into global and local data which helps the team to scale. Global data is replicated across different data centers across geographical zones. On the other hand, the local data is confined to specific data centers.
If you wish to understand how the cloud deploys workloads globally across availability zones and data centers, how clusters work, and more. Check out my platform-agnostic cloud computing course.
Initially, the backend of the app was hosted on AWS but was later migrated to Facebook data centers. This eased the integration of Instagram with other Facebook services, cut down latency and enabled them to leverage the frameworks, tools for large-scale deployments built by the Facebook engineering team.
Instagram’s backend code is powered by #Django #Python. #PostgreSQL is the primary #database of the application. Learn more here #distributedsystems #softwarearchitecture
Click to tweetMonitoring
With so many instances powering the service, monitoring plays a key role in ensuring the health and availability of the service.
Munin is an open-source resource, network and infrastructure monitoring tool used by Instagram to track metrics across the service and get notified of any anomalies.
StatsD a network daemon is used to track statistics like counters and timers. Counters at Instagram are used to track events like user signups, number of likes, etc. Timers are used to time the generation of feeds and other events that are performed by users on the app. These statistics are almost real-time and enable the developers to evaluate the system and code changes immediately.
Dogslow a Django middleware is used to watch the running processes and a snapshot is taken of any process taking longer than the stipulated time by the middleware and the file is written to the disk.
Pingdom is used for the website’s external monitoring, ensuring expected performance and availability. PagerDuty is used for notifications & incident response.
Now let’s move on to the search architecture.
How Does Instagram Runs A Search For Content Through Billions of Images?
Instagram initially used Elasticsearch for its search feature but later migrated to Unicorn, a social graph-aware search engine built by Facebook in-house.
Unicorn powers search at Facebook and has scaled to indexes containing trillions of documents. It allows the application to save locations, users, hashtags, etc and the relationship between these entities.
Speaking of Insta’s search infrastructure, it has denormalized data stores for users, locations, hashtags, media, etc.
These data stores can also be called documents, which are grouped into sets to be processed by efficient set operations such as AND-OR and NOT.
The search infrastructure has a system called Slipstream which breaks the user uploaded data, streams it through a Firehose and adds it to the search indexes.
The data stored by these search indexes is more search-oriented as opposed to the regular persistence of uploaded data to PostgreSQL DB.
Below is the search architecture diagram
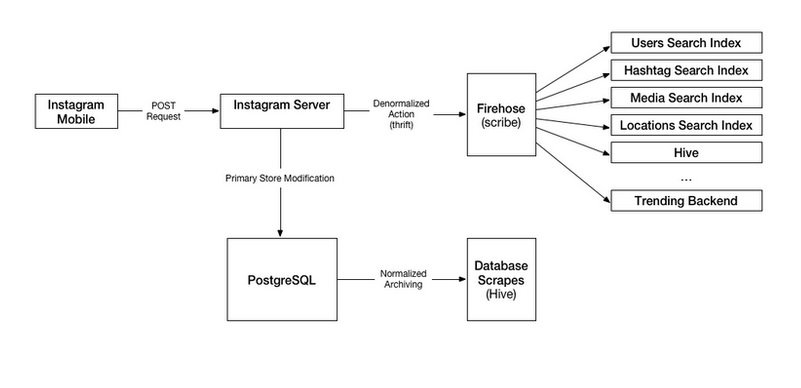
If you aren’t aware of Hive, Thrift, Scribe. Do go through this write-up what database does Facebook use? It will give you an insight into how Facebook stores user data.
Related Read: ‘Futures and Promises’ – How Instagram leverages it for better resource utilization
Instagram initially used #Elasticsearch for its search feature but later migrated to #Unicorn, a social graph-aware search engine built by Facebook in-house. #distributedsystems #softwarearchitecture
Click to tweetReferences:
Instagram search architecture
Trending on Instagram
Sharding at Instagram
If you found the content helpful, I run a newsletter called Backend Insights, where I actively publish exclusive posts in the backend engineering space encompassing topics like distributed systems, cloud, application development, shiny new products, tech trends, learning resources, and essentially everything that is part of the backend engineering realm.
Being a part of this newsletter, you’ll stay on top of the developments that happen in this space on an ongoing basis in addition to becoming a more informed backend engineer. Do check it out.
Folks, this is pretty much it. The article will be continually updated as Instagram’s architecture evolves. I am Shivang. You can catch me on LinkedIn and X here. If you found the content helpful, do share it with your network for better reach. Until the next blog post. Cheers!



Follow Me On Social Media