
{kind=link}
System Design Case Study #5: In-Memory Storage & In-Memory Databases – Storing Application Data In-Memory To Achieve Sub-Second Response Latency
In the last few write-ups on this blog, I’ve dug deep into the aspect of storing application data in-memory to reduce the service response latency.
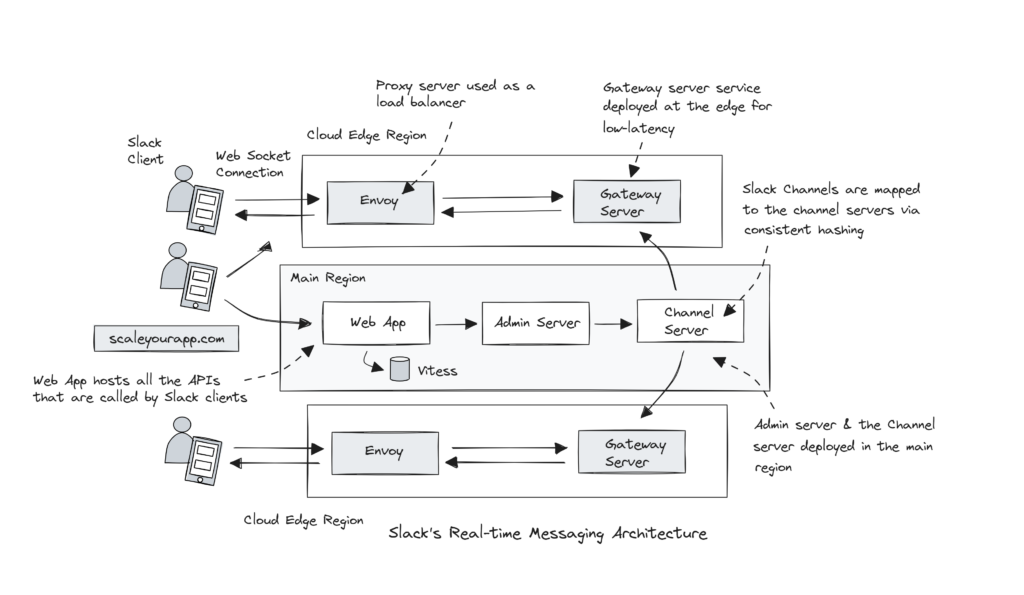
I started with a discussion on Slack’s real-time messaging architecture. Slack sends millions of messages daily across millions of Slack channels in real-time across the world. Slack’s Channel Servers (CS) are stateful and hold the channel information in-memory. At peak times, approx. 16 million channels are served per host.
The channel servers hold channel information in-memory to deliver messages to clients quickly and efficiently, ensuring minimal latency. When the data is hosted in-memory, the backend servers don’t have to poll any external storage like the database to fetch information on every client request. This enables the service to quickly return the response to the clients, keeping the latency low.
I did a detailed case study on Slack’s real-time messaging architecture here on this blog. Check it out.
Similarly, WalkMe Engineering stores large application content files in-memory to reduce the latency. Storing data in-memory averts the need to fetch content from external systems like the database or the object store to serve a request.
At WalkMe, the files were originally hosted in AWS S3 object storage service and fetching them on every user request had a significant amount of IO-latency. It took almost two minutes to download 1.5 GB from S3. Accessing the same data from memory took 20 seconds — around 600% faster.
Here is a detailed case study on the WalkMe application architecture on this blog.
Clearly, holding data in-memory cuts down the system response times by notches. Use cases like real-time ad bidding, high-frequency trading, real-time messaging systems, etc., require minimal latency to perform effectively. These system architecture use cases require us to serve data from memory as opposed to polling databases every time.
Storing & serving data from memory is great, but it makes the system stateful, which brings along scalability challenges. If the application server hosting data goes down, the data is lost. Another server in the cluster cannot replace it without the end user realizing the swap.
I’ve done a detailed discussion on stateful and stateful services here. Check it out.
In this article, I’ll discuss in-memory databases and how we can leverage them to improve our system’s performance.
What Is An In-Memory Database?
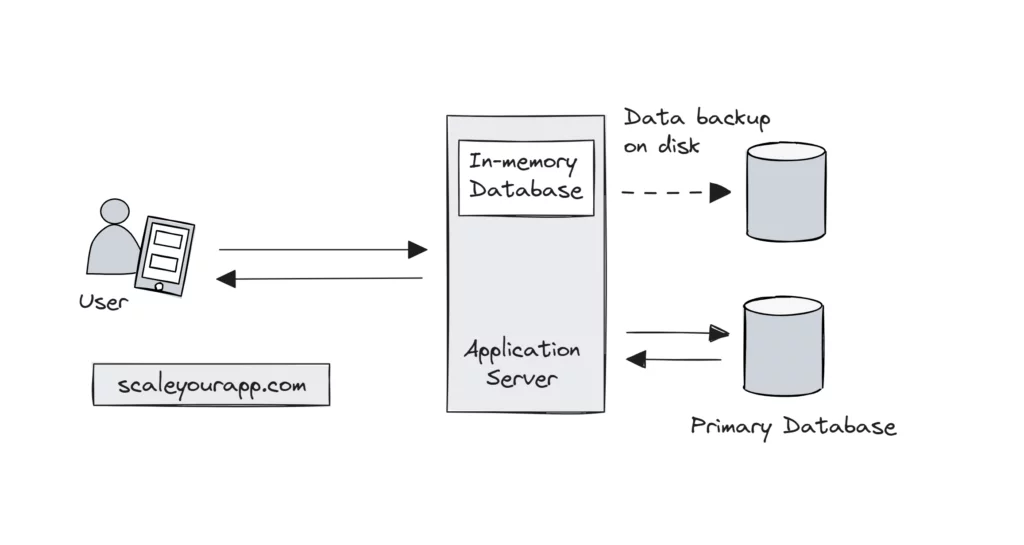
An in-memory database is a database that runs entirely out of application server’s memory. Traditional databases store data on disk, whereas in-memory databases store data in RAM, facilitating low-latency read writes.
With in-memory databases, the service’s latency goes down and this reduction in latency increases the system throughput as well.
The volume of data that can be held in-memory entirely depends on the server’s hardware and the compression techniques leveraged. Like traditional databases, in-memory databases can handle complex queries efficiently, acting as regular databases operating from RAM. They can also be horizontally scaled across the cluster, different availability zones and cloud regions, enabling them to handle increased workloads.
In in-memory databases, the data is managed in-memory to cut down the disk I/O latency, but this does not mean the data stays ephemeral. These databases provide an option to replicate data to persistent storage as well, for durability, in addition to managing it in memory.
In-Memory Database Use Cases
Since an in-memory database provides sub-millisecond latencies, it fits best with real-time service use cases such as rendering ads on a web page in milliseconds based on multiple criteria such as website niche, content type and other publisher and advertiser preferences, messaging systems, high-frequency trading systems and such.
Another use case is implementing a gaming leaderboard that needs to reflect the player rankings with minimal delay to keep the players (in the scale of millions) motivated to keep playing to keep the engagement high.
In-memory databases can ingest, process and analyze real-time data with single-digit millisecond latency. Based on the use case, they can also be used as a primary database in the service architecture, averting the need for a cache and the traditional database.
Some popular in-memory databases are AWS MemoryDB, Apache Ignite, Hazelcast and Redis. Speaking of AWS MemoryDB, it uses a distributed transactional log to replicate data across cloud availability zones, ensuring durability. Distributed transactional log deserves a dedicated article; I’ll discuss it in my future posts.
Let’s further understand the use of an in-memory database in a real-world system architecture.
ECommerce Service Design: Computing Data In Real-time Based On User Behavior With An In-Memory Database
Picture a scenario where, on our e-comm website, we intend to show the user tailored data in real-time based on their current browsing and past purchase behavior, including the already stored user state on the backend, providing a highly personalized shopping experience.
The system needs to dynamically adjust product recommendations, promotional offers, product pricing, keeping tabs on the inventory for accurate data, and so on, as the user browses through the website. This naturally requires quick compute with minimal latency. If the response time goes up, the engagement drops.
All these operations require access to the product, user and other relevant data stored in the application database.
A traditional way to pull this off is to fetch the data required for computation from the main database, perform computations in-memory in the application server and return the response to the user interface in real-time as the user browses the website.
A better way can be to store the required data for the real-time operations in-memory in the application server via an in-memory database. This averts the need to poll the primary database every now and then, dropping the latency by notches.
WalkMe Engineering originally hosted the application data needed for compute in AWS S3 object storage service. Fetching them on every user request had a significant amount of IO latency. It took almost two minutes to download 1.5 GB from S3. Accessing the same data from memory took 20 seconds — around 600% faster.
In our use case, keeping data in-memory will provide the application blazing-fast access to all the user, product data and such. This will not only cut down the latency but increase the throughput as well, enabling the system to handle an increased load of real-time user interaction requests.
Can the same be done with a distributed cache? Why specifically use an in-memory database in the above use case? What’s the difference?
Difference Between A Cache And An In-Memory Database
A cache mostly has a key-value data model with constant O(1) access. This is for a no-brainer access to data using the key with minimal latency. In-memory databases, on the other hand, are similar to traditional databases, just totally running out of server RAM.
Though they run in-memory, they support data durability and persistence features like the traditional databases. They keep the data in memory for fast access and have a copy on the disk, making it durable. In addition, they also support complex queries, data models, transactions and other features that traditional databases typically offer.
Caches have ephemeral data with a TTL (Time To Live). They solely intend to improve read performance, not worrying about data durability and persistence.
Low Latency System Architecture With In-Memory Databases
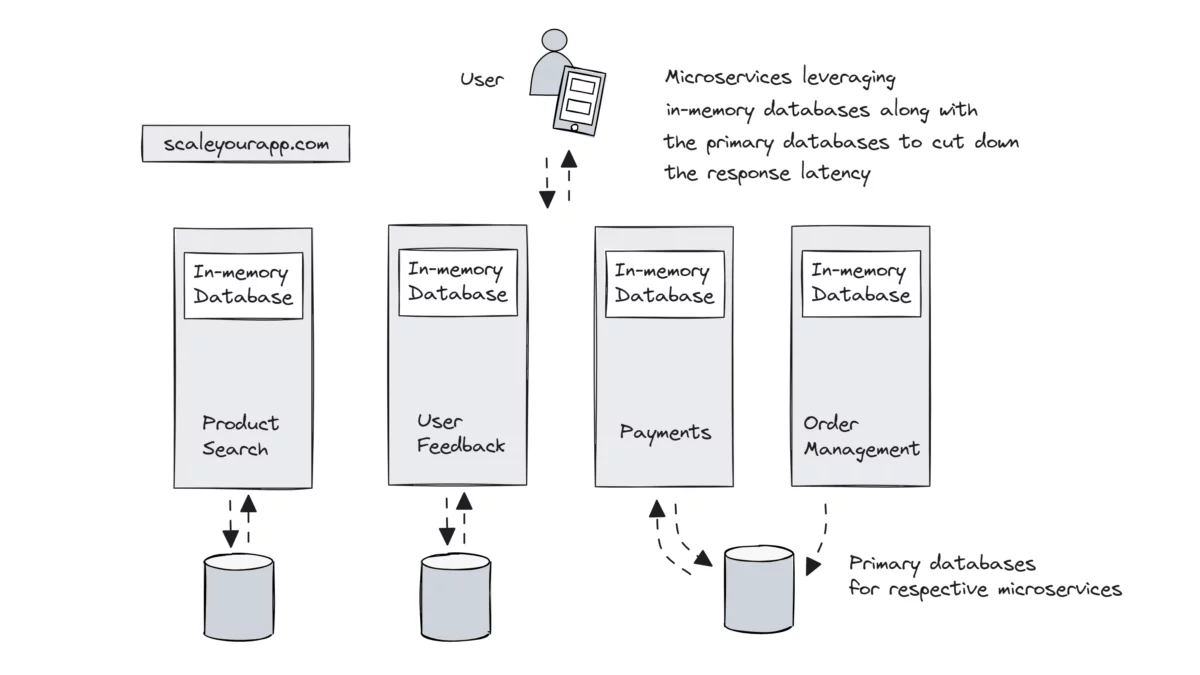
In a real-world scenario, popular e-commerce websites are powered by microservices running dedicated features such as product search, payments, user feedback, order management, and so on.
Based on the application architecture, some microservices may have common databases, and some may have dedicated databases. We can extract required data from the main databases and store them in in-memory databases running on the different microservices instances.
Frequently accessed product and active user data can move to in-memory databases, whereas the primary databases hold the entire dataset. This will avert the need for microservices to hit the primary databases, increasing the system’s performance comprehensively.

Well, it all seems hunky dory with in-memory databases, but we also need to keep in mind that the in-memory databases have a limit to how much data they can store since they operate out of the server’s memory.
In addition, RAM storage is expensive in contrast to disk-based storage and this is a crucial factor when designing and running real-world systems. What data goes into in-memory databases and what stays back in the main databases needs to be carefully thought.
If you wish to take a deep dive into how real-world large-scale systems are designed, with discussions on the fundamentals, cloud infrastructure, how large-scale services are deployed in different cloud regions and availability zones across the globe, how they handle insane concurrent traffic, how databases scale and a lot more, check out the Zero to Software Architecture Proficiency learning path (comprising three courses), I’ve authored.
It gives you a structured learning experience, taking you right from having no knowledge on the domain to making you a pro in designing web-scale distributed systems like YouTube, Netflix, ESPN and the like.
If you found the content helpful, I run a newsletter called Backend Insights, where I actively publish exclusive posts in the backend engineering space encompassing topics like distributed systems, cloud, application development, shiny new products, tech trends, learning resources, and essentially everything that is part of the backend engineering realm.
Being a part of this newsletter, you’ll stay on top of the developments that happen in this space on an ongoing basis in addition to becoming a more informed backend engineer. Do check it out.
With that being said, I’ll wrap up this article. If you found the content helpful, consider sharing it with your network for more reach. I am Shivang. Here is my X and LinkedIn profile. Feel free to send me a message. I’ll see you in the next post. Until then, Cheers!
System Design Case Study #5: In-Memory Storage & In-Memory Databases - Storing Application Data In-Memory To Achieve Sub-Second Response Latency


Follow Me On Social Media