
{kind=link}
‘Futures and Promises’ – How Instagram leverages it for better resource utilization
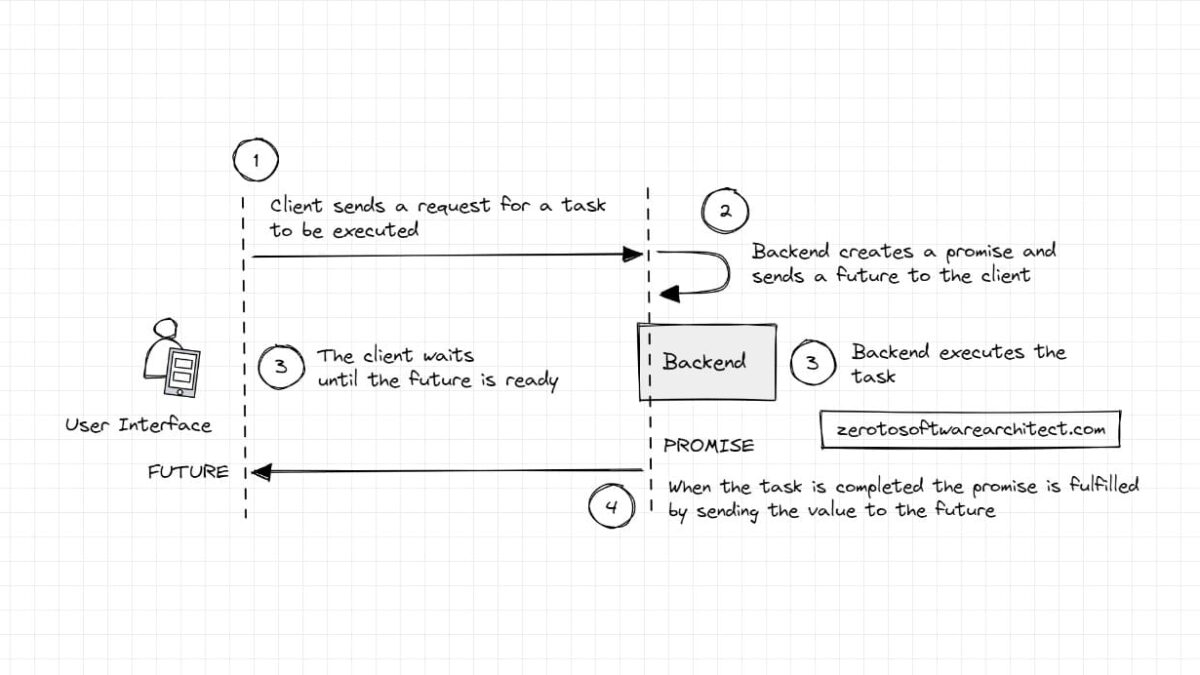
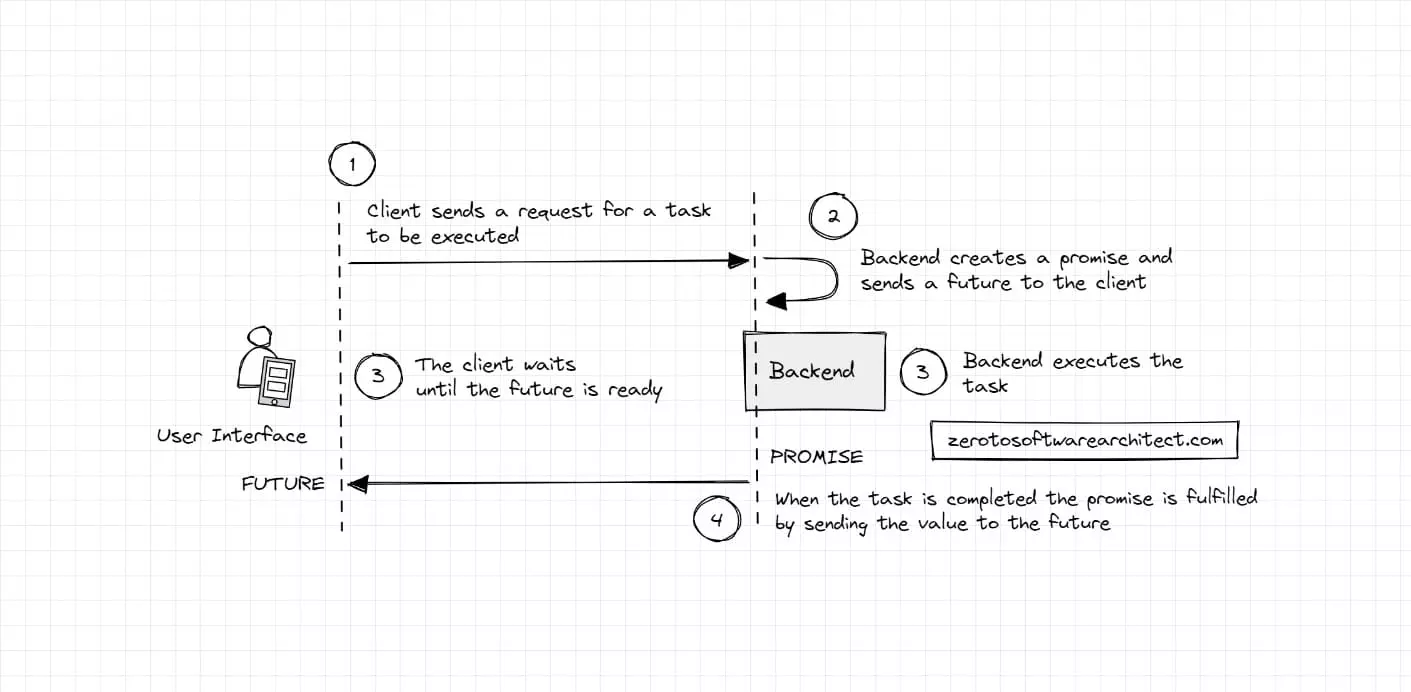
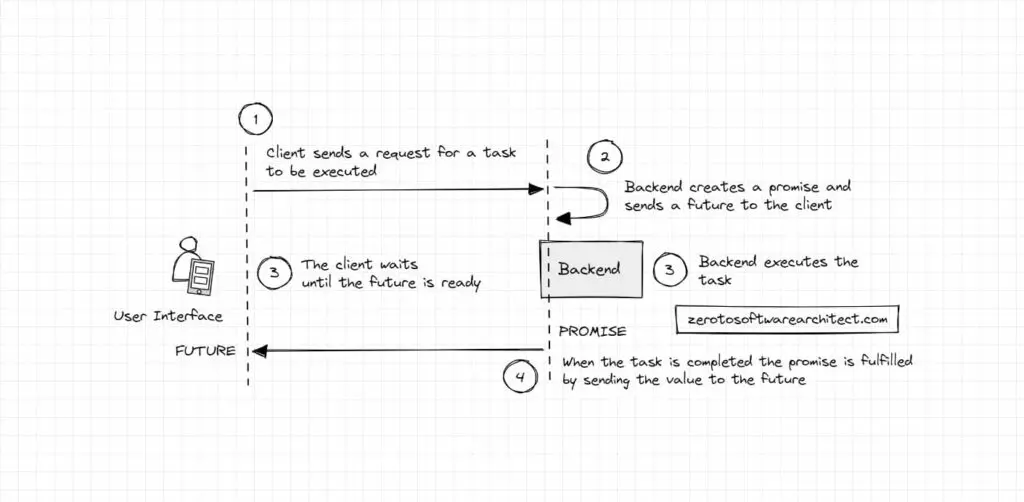
Futures and Promises is a concept that enables a process to execute asynchronously, improving performance and resource consumption. It can be applied in multiple contexts, such as in request-response in a web service call, long-running computations, database queries, remote procedure calls, interservice communication in distributed systems and more. The concept is also leveraged in several programming languages, such as Java, JavaScript, Scala, and C++.
A Future is a reference to a value or a placeholder for a value that will eventually be available. A Promise is a promise to provide that value to the future. A Future refers to a Promise.
Check out this Mozilla documentation on Promise for further insights.
Many real-world services leverage this concept. For instance, Instagram engineering leverages it in their user profile recommendation services.
Instagram user recommendation services
The user profile recommendation services comprise two services. The first service, “Suggested Users,” fetches user accounts from different sources such as friends of the user browsing, profiles they may be interested in, popular accounts in their network and such. The service, with the help of machine learning, then produces a list of personalized account suggestions and recommends it to the user. This service is an important means of discovery on Instagram and generates millions of followers per day for different user profiles.
With the help of Futures via an open-source C++ library Folly, they were able to increase the peak CPU utilization of the service from 10-15% to 90% per instance. This reduced the number of instances of the service from 720 to 38.
In another user recommendation service, “Chaining,” that generates a list of related profiles below a certain Insta profile experiences over 30K queries per second, with Futures, they achieved 40 ms average end-to-end latency and under 200ms p99 running only on 38 instances.
While most of the backend for Instagram is written in Django, the user recommendation services are written in C++ with Fbthrift. Details here.
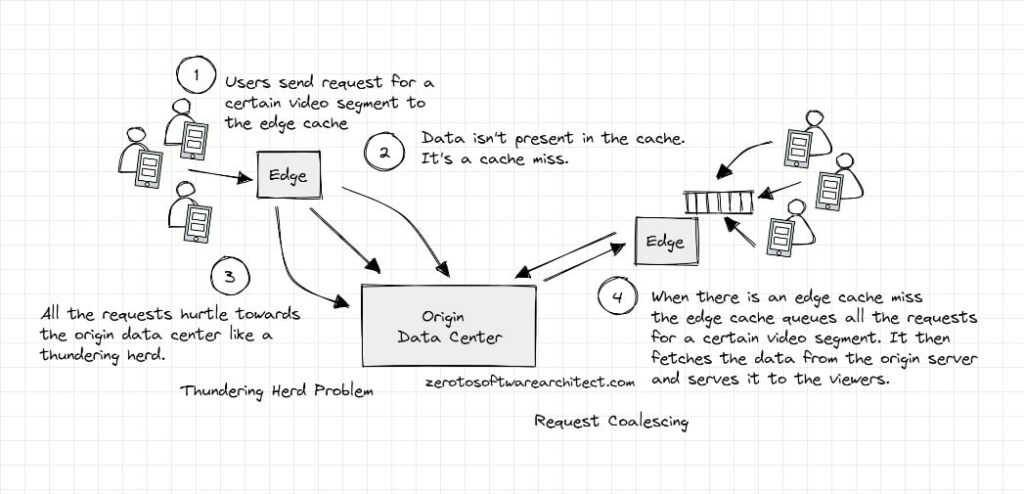
Thundering herd and request coalescing
Imagine a scenario where live video is served from the origin data center via edge locations to the end users. Cloud edge locations act as a cache for the video data.
When the video is streamed live, certain segments of the stream are not populated in the cache at the point they are requested by millions of live viewers. It’s a cache miss since the data isn’t there yet. The requests then hurtle toward the origin data center. This scenario is known as the Thundering Herd problem, which may overwhelm the origin data center causing lag, dropouts, and eventually, disconnection to the point of making the servers take a nosedive due to excessive overload.
To tackle this dreadful situation, the requests are never allowed to move to the origin data center but rather stopped right at the cache, i.e., the edge node. The edge node stores all the requests for certain video segments in a queue. The cache is then populated from the origin server and the response is returned to the viewers. The process of queuing user requests is known as Request Coalescing.
This thundering herd excerpt is from my distributed systems design course, “Design Modern Web-Scale Distributed Systems Like a Pro.” and the Zero to Software Architect learning track.
Now let’s understand how Instagram handles the thundering herd problem.
Dealing with thundering herd with the help of Promises
As a new cluster is turned up at Instagram, they face a thundering herd problem since the cluster’s cache is empty. To deal with this, they use Futures and Promises by caching a reference to the eventually provided value.
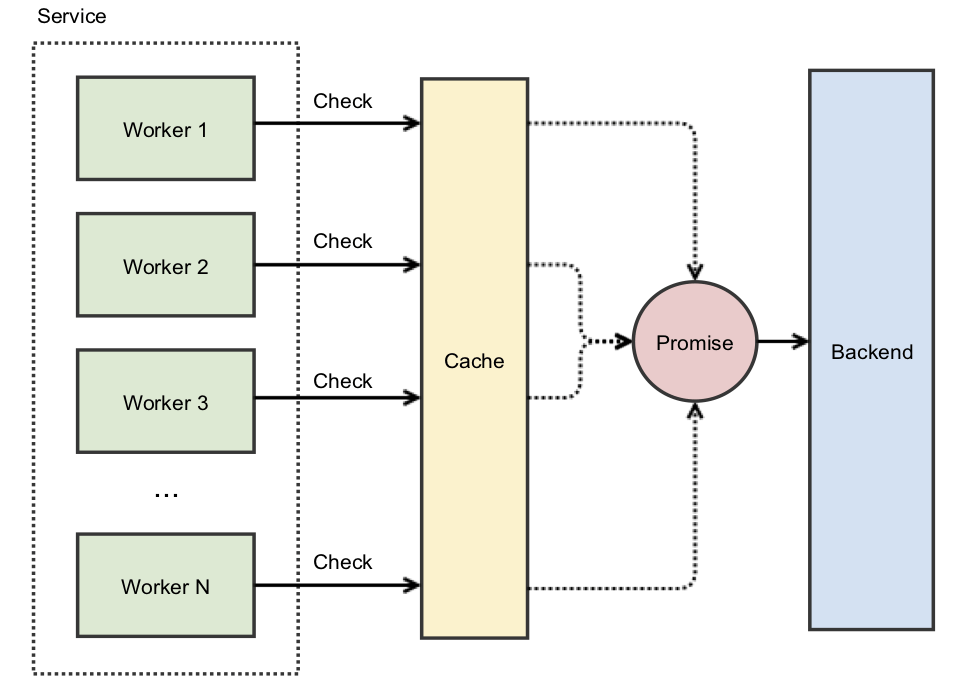
When there is a cache miss as opposed to a request hitting the backend, it hits a promise that starts working against the backend. All the concurrent requests are handled by the same existing promise. Most caches at Instagram are promised-based to cut down the load on the origin servers. Details here.
If you want to learn designing distributed services from the bare bones, including a thorough discussion on web architecture and cloud computing fundamentals, check out my Zero to Software Architect learning track.
Also, if you found the content helpful, consider sharing it with your network. Cheers!



Follow Me On Social Media